
 [NVIDIA Jetson Nano] Jetson Nano를 오랜만에 부팅했는데 NVIDIA LOGO 화면에 stuck 되는 현상을 해결하기
[NVIDIA Jetson Nano] Jetson Nano를 오랜만에 부팅했는데 NVIDIA LOGO 화면에 stuck 되는 현상을 해결하기
작성자 : 한양대학교 일반대학원 인공지능융합학과 유승환 박사과정 안녕하세요~ 오랜만에 Jetson Nano 관련 블로그 글을 올립니다! 저는 엘스비어 저널에 투고한 논문의 리비전 작업을 위해, 오랜만에 Jetson Nano를 부팅했는데... 처음으로 모니터에 뜨는 Nvidia Logo 화면에서 Stuck되어서 다음 화면으로 넘어가지 않더라고요 ㅜㅜ (1시간 넘게 기다려도 계속 stuck된 채로 멈춰있습니다...) 관련해서 구글링을 하면 정말 다양하고 어려운 솔루션들이 나옵니다! 그런데 저는 엄청 쉬운 방법으로 해결이 되더라고요...ㅎㅎ 저와 같은 현상이 발생하면, jetson nano에 장착된 micro SD 카드를 뺐다가 다시 장착해주세요! 그런 다음에 jetson nano를 재부팅하면, 신기하게..
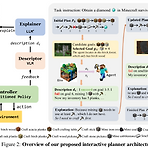 [Robotics with LLMs 논문 정리 1편] Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents (2023 arxiv)
[Robotics with LLMs 논문 정리 1편] Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents (2023 arxiv)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB)Keywords : Open-World, Interactive Planning, Multi-task Agents, Large Language Models, Minecraft논문 링크 : https://arxiv.org/abs/2302.01560 Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task AgentsWe investigate the challenge of task planning for multi-task embodied agents in open-world environment..
 강화학습 논문 정리 15편 : Accelerating Interactive Human-like Manipulation Learning with GPU-based Simulation and High-quality Demonstrations (IEEE-RAS 2022)
강화학습 논문 정리 15편 : Accelerating Interactive Human-like Manipulation Learning with GPU-based Simulation and High-quality Demonstrations (IEEE-RAS 2022)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) Keywords : Dexterous manipulation, Learning from human demonstrations, Reinforcement Learning 논문 링크 : https://ieeexplore.ieee.org/document/10000161 Accelerating Interactive Human-like Manipulation Learning with GPU-based Simulation and High-quality Demonstrations Dexterous manipulation with anthropomorphic robot hands remains a challenging problem in robot..
 강화학습 논문 정리 14편 : DexMV : Imitation Learning for Dexterous Manipulation from Human Videos (ECCV 2022)
강화학습 논문 정리 14편 : DexMV : Imitation Learning for Dexterous Manipulation from Human Videos (ECCV 2022)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) Keywords : Dexterous manipulation, Learning from human demonstrations, Reinforcement Learning 논문 링크 : https://link.springer.com/chapter/10.1007/978-3-031-19842-7_33 홈페이지 링크 : https://yzqin.github.io/dexmv/ DexMV: Imitation Learning for Dexterous Manipulation from Human Videos yzqin.github.io 영상 링크 : https://www.youtube.com/watch?v=scN4-KPhJe8 깃헙 링크 : https..
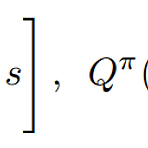 강화학습 논문 정리 13편 : Skill Preferences : Learning to Extract and Execute Robot Skills from Human Feedback 논문 리뷰 (CoRL 2021)
강화학습 논문 정리 13편 : Skill Preferences : Learning to Extract and Execute Robot Skills from Human Feedback 논문 리뷰 (CoRL 2021)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) Keywords : Reinforcement Learning, Skill Extraction, Human Preferences 논문 링크 : https://proceedings.mlr.press/v164/wang22g.html Skill Preferences: Learning to Extract and Execute Robotic Skills from Human Feedback A promising approach to solving challenging long-horizon tasks has been to extract behavior priors (skills) by fitting generative models to large..
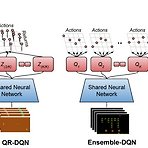 강화학습 논문 정리 12편 : An Optimistic Perspective on Offline Reinforcement Learning 논문 리뷰 (ICML 2020)
강화학습 논문 정리 12편 : An Optimistic Perspective on Offline Reinforcement Learning 논문 리뷰 (ICML 2020)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) 논문 링크 : https://proceedings.mlr.press/v119/agarwal20c.html An Optimistic Perspective on Offline Reinforcement Learning Off-policy reinforcement learning (RL) using a fixed offline dataset of logged interactions is an important consideration in real world applications. This paper studies offline RL using the DQN rep... proceedings.mlr.press 홈페이지 링크 : https:..
 강화학습 논문 정리 11편 : Eureka: Human-Level Reward Design via Coding Large Language Models 논문 리뷰 (arXiv 2023)
강화학습 논문 정리 11편 : Eureka: Human-Level Reward Design via Coding Large Language Models 논문 리뷰 (arXiv 2023)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) 논문 링크 : https://arxiv.org/abs/2310.12931 Eureka: Human-Level Reward Design via Coding Large Language Models Large Language Models (LLMs) have excelled as high-level semantic planners for sequential decision-making tasks. However, harnessing them to learn complex low-level manipulation tasks, such as dexterous pen spinning, remains an open problem. We bridg..
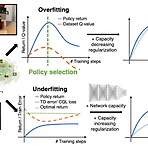 강화학습 논문 정리 10편 : A workflow for Offline Model-Free Robotic Reinforcement Learning 논문 리뷰 (CoRL 2022)
강화학습 논문 정리 10편 : A workflow for Offline Model-Free Robotic Reinforcement Learning 논문 리뷰 (CoRL 2022)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) 논문 링크 : https://proceedings.mlr.press/v164/kumar22a.html A Workflow for Offline Model-Free Robotic Reinforcement Learning Offline reinforcement learning (RL) enables learning control policies by utilizing only prior experience, without any online interaction. This can allow robots to acquire generalizable skills from ... proceedings.mlr.press 홈페이지 링크 : Off..