
티스토리 뷰
강화학습 논문 정리 15편 : Accelerating Interactive Human-like Manipulation Learning with GPU-based Simulation and High-quality Demonstrations (IEEE-RAS 2022)
hanyangrobot 2023. 12. 5. 14:02작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB)
Keywords : Dexterous manipulation, Learning from human demonstrations, Reinforcement Learning
논문 링크 : https://ieeexplore.ieee.org/document/10000161
Accelerating Interactive Human-like Manipulation Learning with GPU-based Simulation and High-quality Demonstrations
Dexterous manipulation with anthropomorphic robot hands remains a challenging problem in robotics because of the high-dimensional state and action spaces and complex contacts. Nevertheless, skillful closed-loop manipulation is required to enable humanoid r
ieeexplore.ieee.org
홈페이지 링크 : https://maltemosbach.github.io/interactive_human_like_manipulation/
papertitle_website
papertitle_heading 1University of Bonn Abstract: Manipulation with anthropomorphic robot hands remains a challenging problem in robotics because of the high-dimensional state and action spaces and complex contacts. Nevertheless, skillful closed-loop manipu
maltemosbach.github.io
깃헙 링크 : https://git.ais.uni-bonn.de/mosbach/gym-grasp
mosbach / gym-grasp · GitLab
Nvidia Isaac Gym environments for robotic grasping.
git.ais.uni-bonn.de
Abstract

(1) Dexterous Manipulation의 Open Problem
- 인간형 로봇 핸드의 dexterous manipulation은 로봇 공학에서 여전히 도전적인 문제임
- 이는 고차원의 상태 및 행동 공간과 복잡한 접촉(contacts) 때문임
- 그럼에도 불구하고, 구조화되지 않은 실제 세계 환경에서 휴머노이드 로봇이 작동하도록 하기 위해서는 skillful closed-loop manipulation이 필요함
- 강화학습은 이러한 복잡한 제어 문제를 최적화할 수 있지만, 엄청난 양의 상호작용 데이터를 요구함
(2) 제안하는 방법 : GPU 기반의 시뮬레이션과 모방 학습의 융합
- 우리는 GPU 기반 시뮬레이션과 모방 학습의 장점을 활용하는 새로운 프레임워크를 제안함
- 이는 유망한 행동으로 policy search를 안내함으로써, dexterous manipulation 도메인에서 강화학습을 가능하게 함
- 이를 위해 dexterous manipulation tasks에서 사람과 같은 interactive manipulation을 위한 VR 인터페이스와 일상 생활의 작업에서 영감을 받은 manipulation 환경의 모음(suite)을 제시함
- 또한 대규모 병렬 RL과 모방 학습의 보완적인 강점을 보여주며, 이를 통해 robust하고 자연스러운 행동을 달성함
1. Introduction
(1) Dexterous Manipulation의 장점 및 Open Problem
- 인간형 로봇 핸드는 인간 중심의 세계와 상호작용하기 위한 다재다능한 인터페이스를 제공함
- 다양한 물체를 다루고 dexterous manipulation을 수행하는 능력은 인간에게는 자연스러운 일이지만, 로봇공학에서는 여전히 중요한 미해결된 문제임

(2) Dexterous Manipulation 선행 연구의 한계점
- Model-based Trajectory Optimization
- 시뮬레이션에서 강력한 성능을 보였지만, 정확한 상태 정보와 동역학 모델에 대한 접근을 가정함
- 이는 접촉이 풍부한 상호작용 작업에 대해 얻기 어렵고, 실제 세계 시나리오와 새로운 물체에 적용하기 어려움

- 모방 학습
- 고품질 demonstrations에 의존함
- 드론 비행이나 자동차 운전 분야에서는 고품질 demonstrtaions을 쉽게 얻을 수 있지만, 사람형 로봇을 위한 숙련된 demonstrations을 수집하는 것은 더 복잡한 teleoperation 설정을 요구함
- 게다가 모방 학습은 관찰된 행동의 성능을 개선할 수 없음
- 강화학습
- Dexterous Manipulation의 고차원 연속 상태 및 행동 공간으로 인해 매우 높은 샘플 복잡성을 겪고 있음.
- 지금까지, manipulation 로봇은 사람 수준의 민첩성에 도달하기에는 여전히 멀어보임
(3) 제안하는 프레임워크 : Gym-Grasp
- 복잡한 manipulation 작업에서 강화학습의 높은 샘플 요구 사항을 해결하기 위해, 두 가지 접근 방법을 통합함
- 첫째 : GPU 기반 대규모 병렬 시뮬레이션
- Isaac Gym 시뮬레이터를 활용하여 강화학습의 대규모 병렬화를 가능하게 하여 높은 시뮬레이션 처리량을 달성
- 정책 알고리즘의 성능을 강화
- 둘째 : VR teleoperation 프레임워크
- 접촉이 풍부한 환경에서 skillful manipulation을 가능하게 하기 위해 설계함
- 몰입형 시각화 외에도, 물리적 피드백은 인간이 물체와 상호작용하는 동안 의존하는 중요한 모달리티임
- 따라서 우리는 촉각 인식이 demonstrations의 quality에 영향을 미친다고 가정하고, 시뮬레이터 접촉력을 기반으로 한 haptic(촉각) feedback을 force-feedback glove을 사용하여 통합함
- 대규모 병렬 RL이 dexterous manipulation 제어를 위한 robust 정책을 합성하는 데 사용되었지만, 이전의 연구들[1, 23]은 원하는 행동으로 policy search를 안내하기 위해 dense reward에 의존함
- 이에 반면, 우리의 연구는 모방 학습이 sparse reward task에서도 이러한 학습 패러다임을 실현 가능하게 할 수 있다는 것을 보여줌
(4) 연구 목표
- GPU 가속 시뮬레이션과 고품질 demonstrations을 통해 학습 기반의 dexterous manipulation 연구를 촉진하고, 두 패러다임의 상호 보완적인 강점을 입증하는 것.
(5) 연구 기여점
- Dexterous Manipulation Benchmark : GPU 기반 시뮬레이션인 Isaac Gym을 통한 고성능 강화학습을 지원하는 dexterous manipulation task의 모음을 소개함 (총 4가지의 Task : 서랍 열기, 문 열기, 컵 붓기, 물체 올리기)
- Virtual Reality Teleoperation : 몰입형 VR Teleoperation 시스템을 제시하고, 촉각 피드백이 사용자 선호도와 작업 성공에 미치는 영향을 평가함
- Human Demonstration Datasets : Dexterous Manipulation을 위한 모방 학습 및 오프라인 RL을 가능하게 하는 작업을 위한 human demonstrations 데이터셋을 제공
- Combining RL with Demonstrations : 대규모 병렬 RL에 demonstrations 데이터를 추가하여 얻을 수 있는 잠재적 이득을 보여줌
2. Related Work
(1) Robotic Grasping and Manipulation (e.g. 2-finger gripper)
- Analytical Methods : 선행 연구 [14, 16]
- 역학, 예를 들어 force-closure 에 기반을 두고 있음
- 이 방법론들은 정확한 물체 기하학과 접촉 지점에서의 마찰 계수에 대한 접근을 가정

- Data-driven Methods : 선행 연구 [8]
- 정확한 물체의 기하학과 접촉 지점에서의 마찰 계수에 대한 접근이 필요 없음
- 그러나, 머신 러닝 알고리즘의 유형 혹은 학습 데이터의 형태에 의존

- 그럼에도 불구하고, 위 두 방법 모두 근본적으로 grasp synthesis, 즉 로봇 end-effector의 적합한 configuration을 찾는 문제에 관심을 가짐
- 이는 사람에서 관찰되는 dexterous manipulation과는 극명한 대조를 이루며, 사람의 경우 perception과 행동이 지속적으로 교차됨
(2) Manipulation with RL
- 선행 연구 [6] : QT-OPT
- 강화학습이 parallel gripper로 학습 때 보지 못한 물체를 집어 올리는 컴퓨터 비전 기반 grasping 정책을 합성할 수 있음을 보여줌
- 그러나 수십만번의 실제 세계의 파지 시도의 비용이 듦

- 선행 연구 [20] : DAPG
- dexterous manipulation 정책을 학습하기 위해 human demonstrations 데이터를 사용하였지만, 촉각 인식을 고려하지 않음

- 선행 연구 [1]
- in-hand reorientation을 위한 RL을 연구하고 GPU-based 시뮬레이션에서의 parallelized learning의 강력한 성능을 보여줌
(3) Teleoperation을 통한 demonstrations의 수집
- Vision-based teleoperation
- motion capture data[9] 혹은 hand pose estimation[3, 17, 18] 기법을 사용
- 장점 : 하드웨어 요구 사항(e.g. 가격)이 낮음
- 단점 : 작업 공간을 제한 & 환경으로부터의 (force) 피드백을 제공받지 못함

- VR-based teleoperation [27]
- 시중에 판매되는 VR 컨트롤러를 사용하여 PR2 로봇을 teleoperation하는 방법을 보여줌
- 그러나 사람형 말단 구동기나 haptic feedback에 초점을 맞추지는 않음

- VR-based teleoperation with force feedback[7, 22]
- 선행 연구[7]은 bilateral teleoperation을 위한 force feedback을 연구하지만, 2-finger 그리퍼에 그침.
- Shadow Hand Teleoperation System[22]는 haptic-feedback을 제공하며 접촉이 풍부한 도메인에서 demonstrations을 수집하는 데 사용될 수 있으나, 비용이 비싸고 전문화된 하드웨어를 요구함 (제가 shadow hand 가격을 조사했을 때 억 단위 금액이였습니다 ㄷㄷ)
- 이에 반면, 우리의 시스템은 비싸지 않은 VR 구성 요소(제가 조사해봤을때 약 1천만원 미만)를 기반으로 한 사람형 손의 teleopration 중에 haptic feedback을 가능하게 하며, 다양한 로봇 핸드와 함께 사용될 수 있음
3. Virtual Reality Teleoperation
A. System Overview

(1) 조작 인터페이스
- Vive VR System(그림 2의 Headset)
- 오퍼레이터는 Isaac Gym에서 전용 카메라(그림 2의 VR 카메라)를 통해 시뮬레이션된 장면을 관찰함
- 오퍼레이터의 헤드셋으로 추적되는 head movement를 따라 camera pose를 즉시 업데이트함
- SenseGlove DK1 force-feedback Glove(그림 2의 Hand)
- 각 소가락에 대해 4자유도 손가락 관절 위치를 감지
- 별도로 제어 가능한 힘과 진동 피드백 기능을 제공함
- 글러브 위에 Vive tracker를 장착하여 90Hz에서 sub-millimeter 단위의 6자유도 자세 정보를 제공함
(2) 제어 주파수(Hz) 설정
- 몰입형 VR 운영을 위해 90Hz의 업데이트 주파수가 권장됨
- 하지만, 장기적인 작업(long horizon tasks)에 대해 강화학습과 모방 학습이 점점 더 어려워짐
- 그래서 우리는 더 낮은 주파수 비율로 행동을 선택하고자 할 수 있음
- 따라서 head-mount display와 force feedback의 업데이트 주파수를 MDP의 제어 주파수와 분리함 (그림 2 참고)
- 이에 따라, 우리는 시뮬레이션 측면을 실제 물리 시뮬레이션, 즉 헤드셋과 haptic feedback에 대한 빠른 업데이트를 제공하기 위해 초당 90Hz로 실행함
- 이에 반면 MDP 업데이트는 초당 90/c Hz로 실행됨. 여기서 c는 제어 주파수 간격이며, c는 3으로 설정. (=30Hz의 제어 주파수)
B. Haptic Feedback
- dexterous manipulation을 수행할 때, 사람에게 촉각은 중요하기 때문에, 우리는 힘(force)와 진동(vibration) 피드백을 통해 이 모달리티(촉각)를 통합함
- 사용자가 물체의 존재를 느낄 수 있도록, 우리는 손 끝의 강체 접촉 힘을 결정하고, 이를 절대 힘(absolute force)과 방향성 구성 요소(directional component)로 분해함
- 이 방향성 구성요소는 손 끝을 통해 작용하며 손이 닫히는 것을 방지함
- 손가락을 닫는 것에 반대하는 힘의 구성 요소 $F_{eff}$는 SenseGlove의 force feedback 명령에 매핑되어 breaking 시스템을 활성화하고 손가락을 더 닫는 것에 대한 저항을 증가시킴 (그림 2의 Contact Forces 참고)
- 이는 물체를 잡고 있을 때 느껴지는 저항을 모방하며, 물체를 잡고 운반하는 데 유익함
- 절대 힘 크기 값은 간단한 moving average low-pass filter를 사용하여 부드럽게 처리됨
- 그리고 나서, 우리는 절대 힘의 high-frequency 구성 요소 $||F_{abs}|| - MA(||F_{abs}||)$를 진동 피드백으로 매핑함. 여기서 MA는 이동 평균을 의미함.
- 이로 인해 충돌과 같이 접촉 힘이 갑자기 증가할 때의 피드백 반응은 증가하지만, 지속적인 접촉에 대해서는 피드백이 없음
4. Learning Dexterous Manipulation
A. Task Design

(1) 하드웨어 구성 및 제어 방법
- 6축 협동 로봇 UR5와 Schunk SIH hand를 사용
- 손의 구동은 5자유도를 특징으로 함
- 힘줄(Tendons)은 엄지의 회전과 손가락의 구부림을 제어하는 데 사용되며, 이로 인해 그림 3의 오른쪽 하단에 검은색 실선으로 묘사된 연결된 제어 방식이 발생함. 우리는 이 제어 방식을 Isaac Gym에서 목표 위치의 결합을 통해 재현함.
- 행동은 11차원이며, 원하는 손목 자세(6차원)과 손가락 위치(Schunk Hand의 5자유도)에 대한 상대적인 변화로 해석됨.
- 왜 5자유도이지? 손가락 1개당 1자유도로 해석하는건가??
- 우리는 원하는 손목 자세에서 Jacobian transpose methods를 사용하여 UR5의 목표 관절 위치를 계산함
(2) Dexterous Manipulation Benchmark

- 총 4개의 task가 주어지며, 모든 task는 로봇의 wrist pose와 손가락 위치에 대한 고유감각 observations을 제공함.
- Task 1 : OpenDrawer
- 에이전트는 서랍이 얼마나 열렸는지에 대한 정보를 제공 받음. 이를 통해 손잡이의 위치를 추론할 수 있음.
- Dense rewards는 로봇 핸드와 손잡이 사이의 거리가 멀면 패널티를 주고, 서랍을 여는 것에 대해 지속적으로 보상을 제공함
- 서랍이 0.2m 열리면 task가 해결되고, 환경이 종료됨
- Task 2 : OpenDoor
- 문 손잡이의 자세가 제공되며, 문이 45도 열리면 task가 성공적으로 완료됨
- dense rewards가 사용될 때, 에이전트는 문이 얼마나 열렸는지에 따라 지속적으로 보상을 받으며, 로봇 핸드와 문 손잡이 사이의 거리에 따라 패널티를 받음
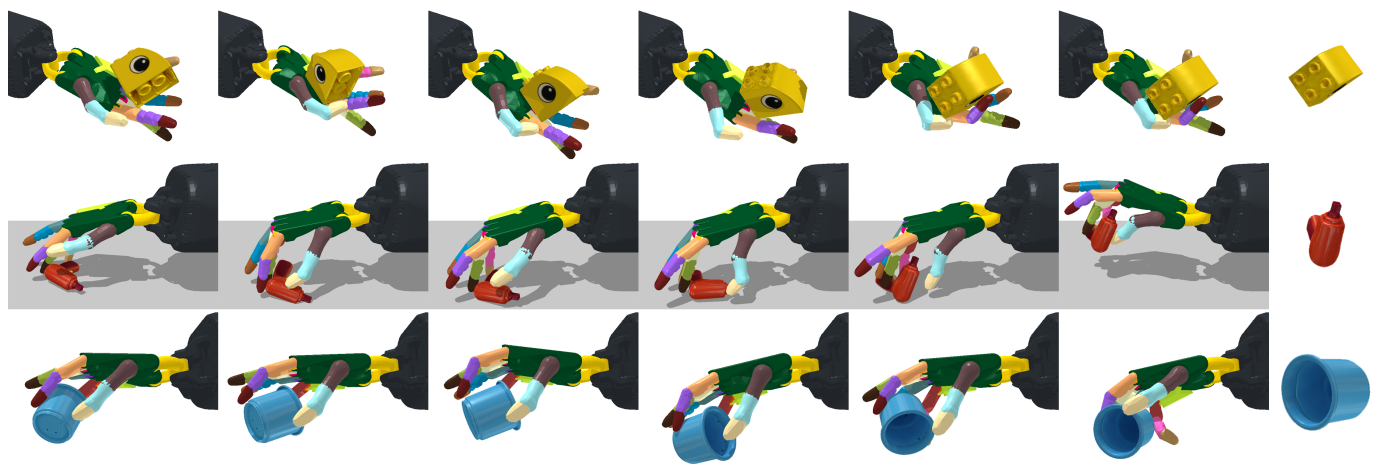
- Task 3 : PourCup
- 가득 찬 컵의 자세가 제공되며, 그룻에 붓는 입자의 양이 일정 값 이상이면 task가 성공적으로 완료됨.
- 에이전트가 그릇에 붓는 입자의 양에 비례하여 보상을 받으며, 손과 컵 사이의 거리에 대해 패널티를 ㅂ다음
- Task 4 : LiftObject
- 물체의 자세가 제공되며, 물체가 테이블 위로 0.2m 들어올려지면 task가 성공적으로 완료되고 종료됨.
- dense reward를 사용할 때, 에이전트는 물체 높이의 positive 변화에 대해 보상을 받으며, 로봇 핸드와 물체 사이의 거리에 대해 패널티를 받음.
- 위에서 설명한 dense reward function 외에도, sparse reward에 대한 성능 평가도 진행함.
- sparse reward는 작업이 성공적으로 완료되면 0의 보상을 받고, 그렇지 않은 경우 모든 작업에 대해 -1의 패널티를 받음.
B. Massively Parallel Reinforcement Learning
- CPU : AMD Ryzen 9 5950 X CPU
- GPU : NVIDIA RTX A6000 GPU (vRAM 48GB)
- 모든 작업은 16,384개의 병렬 환경에서 실행됨 (환경 개수가 어마무시하네요 ㄷㄷ)
- 모방 학습과 강화학습에서 일관된 결과를 얻기 위해, 표 1에 주어진 MDP steps보다 시뮬레이션의 steps이 3배 더 많다는 점을 유의!
C. Imitation and Reinforcement Learning
(1) 학습 알고리즘
- 강화학습 : PPO (Proximal Policy Optimization)
- 모방 학습 : BC (Behavior Cloning)
- 최종적으로는 위 두 알고리즘을 통합한 DAPG 알고리즘을 사용.
- 강화학습과 모방 학습의 손실 함수의 trade-off는 다음과 같이 설정
- $L_{DAPG} = L_{PPO} + \lambda_{0}\lambda _{1}^{k}L_{BC}$
- k : 현재 학습 epoch
- $\lambda_{0}$ = 50
- $\lambda_{1}$ = 0.99
5. Experiments
(1) 실험 질문
- 우리의 VR teleoperation 시스템을 통해 수집된 demonstrations을 사용하여 dexterous manipulation을 위한 성공적인 정책을 학습시킬 수 있을까?
- 선택된 task에 대해 대규모 병렬 체제에서 learning from scratch는 어떻게 수행될까?
- 학습 과정에 demonstration를 통합하는 것이 정책 기반 강화학습의 성능에 어떤 영향을 미칠까?
A. Experimental Setup
(1) Task 별 난이도
- OpenDrawer : 가장 간단한 작업으로, 단일 기술만 필요하며 손가락의 매우 정밀한 제어가 없어도 해결할 수 있음
- OpenDoor : OpenDrawer보다 더 복잡한 작업이며, 손잡이를 돌린 다음 문을 열어주는 두 기술의 연결을 요구함
- PourCup : 섬세한 조작이 필요하며 실패 위험이 높음. 왜냐하면 컵이 목표 위치가 아닌 다른 위치에 쏟아지면 복구할 방법이 없기 때문임.
- LiftObejct : 안정적인 파지를 생성하기 위해 손가락의 정밀한 위치 결정과 들어올려질 물체의 무작위 초기 위치 및 방향에 대한 일반화가 필요
(2) 신경망 구조 및 학습 설정
- 신경망 구조 : 512, 256, 256개의 뉴런으로 구성된 3개의 은닉 층을 가진 MLP
- 각 RL 에이전트는 1,000 epoch 동안 학습됨
- 1 epoch는 32 steps으로 구성되며, 16,384개의 병렬 환경 인스턴스를 통해 1000 epochs * 32 steps * 16384 envs = 524 million steps이 학습됨.
B. Haptic Teleoperation User Study
(1) 실험 목적 : teleoperation 시스템의 평가
- 실험 질문 1 : 비숙련자가 이 시스템을 활용하여 manipulation 작업을 해결할 수 있는가?
- 이 실험에는 프레임워크를 운영해본 경험이 없는 6명의 참가자가 참여함
- 실험 질문 2 : 사용자 선호도와 작업 완료에 대한 haptic-feedback의 영향력이 얼마나 되는가?
(2) 실험 방법

- 실험 참가자들은 위 그림 5에 표시된 환경에서 3가지 작업을 수행함
- 3개의 RGB 큐브 쌓기
- 문 열기
- 파란 컵에서 빨간 그릇으로 입자를 붓기
- 다음의 경우에는 작업 실패로 표기함
- 최대 3분의 시간이 지났을 때
- 원상복구할 수 없는 실패가 발생한 경우 (e.g. 테이블에서 큐브를 떨어뜨리거나 컵을 쏟는 경우)
- 각 참가자는 haptic-feedback이 있는 경우와 없는 경우에 작업을 수행함
- teleoperation 중 학습의 영향을 완화하기 위해 두 경우의 시험 순서는 무작위화됨
(3) 실험의 정량적 결과

- 모든 실험 동안 단 하나의 실패만 발생했으며, 이는 큐브가 테이블에서 떨어진 경우였음
- 다양한 작업에 대한 높은 성공률은 사전 경험이 없어도 시스템이 직관적으로 사용될 수 있음을 보여줌
- 모든 작업에서 촉각 피드백이 활성화되었을 때 더 낮은 완료 시간이 관찰되었으며, 이는 teleoperation에 이 촉각 피드백을 통합하는 것의 추가적인 가치를 강조함
(4) 사용자의 경험 평가

- 각 실험 이후, 참가자들은 7단계 척도를 사용하여 실험에 느꼈던 경험을 평가함
- 로봇 팔과 손가락의 직관적인 제어는 일반적으로 높게 평가됨 (Was it easy to control the robot?, Was it intuitive to control the arm?, Was it intuitive to control the fingers?)
- haptic-feedback은 사용자들이 객체와 직접 상호 작용하고 있다고 느끼는 데 긍정적인 영향을 미침 (Was it intuitive to control the fingers?)
- 그러나 두 가지 운영 모드 사이에서 가장 두드러진 차이는 접촉 순간을 인식하는 능력에서 나타남 (Were you able to detect the moments of contact?)
- 사용자들은 haptic-feedback의 기능이 다른 객체들에 대한 손의 정확한 위치에 대한 더 확신 있는 감각을 제공했다고 보고함
C. Results and Analysis
(1) Can the demonstrations collected with our VR teleoperation system be used to train successful policies for dexterous manipulation tasks? -> BC의 결과를 중점적으로 분석!
- 이 질문을 평가하기 위해 조사된 각 작업에 대해 200개의 demonstrations 데이터셋을 수집하였고, 이를 90%의 학습 데이터와 10%의 검증 데이터로 분할함
- 그런 다음 간단한 behavior cloning 정책을 학습시켜 관찰된 demonstrations을 복제하고 검증 loss를 사용하여 과적합을 확인했으며, 성공률은 아래의 표3에서 호가인할 수 있음.

- 오직 모방 학습(BC)만을 사용하여 OpenDrawer와 OpenDoor 작업에서 거의 완벽한 결과를 달성할 수 있음
- PourCup의 경우, 작업의 복잡성과 로봇의 제어 공간을 고려할 때 여전히 강력한 결과를 보이지만, 성능은 일관적이지 않음. (편차 +- 23%)
- 마지막으로, 이 연구에서 단일 물체 기하학만을 사용함에도 불구하고, LiftObject는 모방 학습만으로 배우기에 가장 어려운 것으로 나타남
- 이는 인간 조작자에게도 물체를 안정적으로 잡는 것이 직관적이지 않아 자주 재잡거나 조정이 필요하기 때문일 수 있음
- 또한 물체 자세의 무작위 초기화에 의해 요구되는 일반화가 모방 학습을 상당히 더 어렵게 만드는 것으로 보임.
- 전반적으로 우리는 제안된 파이프라인을 사용하여 사람형 로봇 손에 대한 demonstrations을 수집할 수 있음을 확인했지만, behavior clonning만으로는 더 복잡한 작업에 대한 robust 정책을 생산하기 어려움을 지적함
(2) How does learning from scratch in the massively parallel regime perform on the selected tasks?
-> PPO의 결과를 중점적으로 분석!
- 이 분석을 위해 우리는 dense reward와 sparse reward의 설정으로 구분함
- sparse reward에서 학습하기는 일반적으로 더 어렵지만, 이를 명시하기는 쉬움
- 반면에, dense reward를 제공하는 것은 번거로운 보상 형성을 필요로 하며, 의도하지 않은 해결책으로 학습된 행동을 편향시킬 수 있음
- 모든 작업에서 PPO가 dense reward를 사용하여 얻은 강력한 결과는, 의미 있는 학습 신호가 존재하는 한 대규모 병렬 정책 기반 RL이 연구된 난이도의 작업에 대해 능숙한 해결책을 찾을 수 있을 것임을 시사함
- 반대로, sparse reward를 사용한 PPO는 OpenDrawer 작업에 대한 만족스러운 해결책을 얻는데에만 충분했음
- LiftObject와 Pourcup은 각각의 문제를 해결하기 위해 일부 진전을 보였지만, 결과는 시드마다 크게 달랐음
- OpenDoor는 모든 시드에서 학습 진전이 없었음
- 요약하자면, sparse reward는 랜덤 탐험을 통해 반복적으로 해결책을 발견할 수 있는 더 단순한 작업에서만 학습에 충분했음
- 여러 행동을 연속적으로 결합하고 정확한 조치가 필요한 작업은 이러한 방식으로 해결하기가 매우 어려움
(3) How does incorporating demonstration data into the learning process impact the performance of on-policy RL? -> DAPG의 결과를 중점적으로 분석!
- 마지막으로, demonstrations을 학습 과정에 통합하는 것이 RL에 견고한 정책을 생성하는 데 필요한 학습 신호를 제공하는 데 충분한지 분석함
- 표 3에 보고된 DAPG의 모든 작업에 대한 완벽한 결과는 이 가설을 확인하며, 대규모 병렬 RL과 모방 학습의 상호 보완적인 강점이 어려운 조작 작업을 해결하는 강력한 도구임을 강조함
- 이 방식으로, GPU 가속 환경에서의 정책 기반 학습은 모방 학습만으로는 원하는 견고성이나 일반화를 이끌어내지 못하는 행동을 개선하는 데 사용될 수 있음
- 조사된 복잡도의 모든 작업에 대해 이 패러다임은 견고한 정책을 생성할 수 있으며, 최종 테스트 롤아웃에서 실패 사례는 관찰되지 않았음
- 그림 7에서는 PourCup 작업에서 pure RL(PPO)와 DAPG를 사용한 학습된 행동의 예를 보여주며, DAPG의 성능을 시각적으로 보여줌.

6. Discussion and Conclusion
(1) 요약
- 우리의 결과는 대규모 병렬 model-free RL의 학습 과정에 demonstrtaions을 추가하는 것이 두 접근법의 상호 보완적인 강점을 활용할 수 있음을 보여줌
- demonstrations은 RL에 의미 있는 진전을 이루기 위한 학습 신호를 제공하며, 고도로 병렬화된 RL 학습은 demonstrations에서 본 행동을 세밀하게 다듬는 데 사용될 수 있음
- 이 작업의 목적은 이 유용한 연결을 강조하고, 강화학습과 모방학습의 교차점에 대한 연구를 촉직하기 위한 도구를 제공하는 것임
(2) 향후 연구 방향
- Nvidia Isaac Gym 시뮬레이터에서 학습한 정책을 실제 로봇 설정으로 전환하기
- 복잡한 다중 객체 환경에서 demonstration을 통해 학습 (e.g. 지저분한 통에서 물건을 고르기)
- 더 복잡한 다단계 작업에서의 성능 검증 (e.g. 닫힌 서랍에서 물건을 꺼내기)