
티스토리 뷰
강화학습 논문 정리 13편 : Skill Preferences : Learning to Extract and Execute Robot Skills from Human Feedback 논문 리뷰 (CoRL 2021)
hanyangrobot 2023. 11. 14. 19:32작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB)
Keywords : Reinforcement Learning, Skill Extraction, Human Preferences
논문 링크 : https://proceedings.mlr.press/v164/wang22g.html
Skill Preferences: Learning to Extract and Execute Robotic Skills from Human Feedback
A promising approach to solving challenging long-horizon tasks has been to extract behavior priors (skills) by fitting generative models to large offline datasets of demonstrations. However, such g...
proceedings.mlr.press
홈페이지 링크 : https://sites.google.com/view/skill-pref?pli=1
SkiP
A promising approach to solving challenging long-horizon tasks has been to extract behavior priors (skills) by fitting generative models to large offline datasets of demonstrations. However, such generative models inherit the biases of the underlying data
sites.google.com
Abstract
(1) long-horizon task을 해결하기 위한 기존 연구의 한계점
- long-horizon task를 해결하기 위한 유망한 접근 방법 중 하나는 대규모 오프라인 데이터 베이스에 있는 demonstration에 대해 generative model을 적용하여 행동 우선순위(skils)를 추출하는 것이었음
- long-horizon task의 예시 : 전자레인지 문을 열어서 음식을 집어 넣고 전자레인지 전원 스위치를 켜기 등...
- 그러나, 이러한 generative model들은 underlying data의 편향을 상속받아 불완전한 demonstrations 데이터로 학습될 경우, 사용할 수 없는 기술을 결과로 낳음
(2) 제안하는 방법 및 성과
- 인간의 의도와 행동 우선순위(skils)의 추출을 더 잘 일치시키기 위해, 본 연구는 Skip(Skill Preferences)라는 알고리즘을 제안함
- 이는 인간의 선호도에 대한 모델을 학습하고, 이를 이용하여 오프라인 데이터에서 인간과 조화된 기술을 추출함
- 인간이 선호하는 기술을 추출한 후, Skip는 또한 인간의 피드백을 활용하여 강화학습으로 downstream 작업을 해결함
- 본 연구의 결과는 Skip가 시뮬레이션된 주방 로봇이 복잡한 다단계 조작 과제를 해결하는 데 도움을 주며, 인간의 선호도를 가진 기존 강화학습 알고리즘뿐만 아니라, 인간의 선호도가 없는 기술 추출 알고리즘을 크게 능가하는 것을 보여줌
1. Introduction
(1) 심층 강화학습의 한계점 : 보상 함수 설계의 어려움
- 심층 강화학습(RL)은 시간적으로 확장된 과제를 해결하기 위한 프레임 워크로, 바둑 게임, 비디오 게임, 로봇 제어 등 자율 제어 분야에서 여러 혁신적인 성과를 낳았음
- 그러나, 오늘날의 RL 시스템은 각 과제에 대해 보상을 설계하기 위해 상당히 수동적인 인간의 노력이 필요로 하며, 이는 다음과 같은 근본적인 단점을 가지고 있음
- 다양하고 여러 카테고리의 과제에 걸쳐 보상을 설계하기 위해 필요한 인간의 노력은 실용적으로 확장되기 어려움
- 설계된 보상은 종종 RL 에이전트에 의해 악용되어 의도치 않고 잠재적으로 위험한 제어 정책을 생산할 수 있음
- 실제 세계 설정에서 자주 마주치는 복합적인 구조를 가진 복잡한 과제에 대한 보상 함수를 설계하는 것은 점점 더 어려워짐
- 연구 질문 : 인간의 의도와 조화되고 복잡한 실제 세계 과제를 해결할 수 있는 로봇 제어 정책을 어떻게 학습할 수 있을까요?
(2) Human-in-the-loop RL의 잠재력
- Human-in-the-loop RL은 전통적인 RL 알고리즘 설계에 대한 대안적 접근 방법을 제시하며, RL을 인간의 의도와 더 잘 일치시키기 위한 유망한 방법으로 부상하고 있음
- 보상 함수를 수동으로 설계하고 나서 RL 에이전트를 학습 시키는 대신에, human-in-the-loop RL은 인간이 학습 중인 에이전트에게 상호작용적으로 피드백을 제공하도록 제안함
- 이 패러다임의 변화는 보상 악용을 우회하고 RL 알고리즘에 즉각적인 피드백을 제공함으로써 인간의 의도와 가장 잘 맞추며, 인간 라벨의 효율적인 측면에서 필요한 경우, 보상 엔지니어링보다 더 신뢰성 있게 다양한 과제에 걸쳐 RL 학습을 확장할 수 있는 잠재력을 가짐
(3) Human-in-the-loop RL의 어려운 점
- 지금까지 human-in-the-loop RL은 아타리 게임을 플레이하는데, 시뮬레이션된 이동 및 조작 과제를 해결하는 데, 그리고 언어 모델의 출력을 더 잘 조정하는 데 사용되어왔음
- 이러한 초기 결과들이 유망하긴 하지만, human-in-the-loop RL은 여전히 실제 세계 로봇공학에 필요한 장기적이고 구상적인 과제에 대해 접근하기 어려움
- 주된 이유는 현재 방법들이 더 도전적인 과제에 대해 인간 라벨과 관련하여 효율적으로 확장되지 않기 때문임
- 과제의 복잡성이 증가함에 따라, 적합한 정책을 얻기 위해 필요한 인간 피드백 상호작용의 수가 실용적이지 않게 됨
(4) 또 다른 해결 방안 : 행동 우선순위인 skill의 추출
- RL 알고리즘이 더 복잡하고 긴 시간대 과제에 확장할 수 있는 능력을 다루기 위해, 최근 여러 연구들은 행동 우선 순위의 data-driven 추출을 제안했으며, 우리는 이를 기술(skills)이라고 함
- 이러한 방법에서, 행동 우선순위는 오프라인 demonstrations 데이터셋에 대해 적합하게 설정되고, 그 후에 행동 분포에 가까이 머무르도록 정규화하여 downstream 문제를 해결하기 위한 RL 정책을 안내하는 데 사용됨
- 이러한 방법들은 다양한 객체 조작 및 로봇 팔으 ㄹ사용하여 주방을 운영하는 과제를 성공적으로 해결하는 것으로 나타남
- 그러나, 이들은 여전히 downstream 과제에 대해 설계된 보상을 필요로 하며, 더 중요하게는 downstream 과제에 특별히 관련된 전문가의 시연이 포함된 clean dataset이 있다고 가정함
- 이에 따라 다양한 정책에 의해 수집된, highly multi-modal 구조를 가진, 노이즈가 많은 데이터셋에서 강건한 기술 추출 방법을 요구됨
(5) 제안하는 방법 : Skip(Skill Preferences)
- 제안하는 Skip 알고리즘 : human-in-the-loop RL과 data-driven 기술 추출을 통합한 것
- 본 연구의 주요 통찰 : 인간의 피드백이 기존 연구에서 처럼 downstream RL에만 통합될 수 있는 것이 아니라, 인간과 조화된 기술을 추출하는 데에도 사용될 수 있다
- Skip은 인간의 선호도 함수를 학습하고, 이를 사용하여 오프라인 데이터셋 내의 궤적들을 인간의 의도와의 일치도에 따라 가중치를 부여함
- 기술 추출 중 인간의 피드백을 통합함으로써, Skip는 잡음이 많은 오프라인 데이터에서 구조화된 인간 선호 기술을 추출할 수 있으며, 기존 기술 추출 접근 방식의 핵심 한계인 정제된 전문가 데이터셋에 대한 의존성을 해결
- Skip는 인간 라벨에 대해 효율적으로 기술을 추출하고 다양한 downstream 과제를 해결할 수 있음
- human-in-the-loop RL에서의 이전 연구가 수동으로 설계된 보상 함수를 인간의 피드백으로 대체할 것을 제안한 것 처럼, 본 연구는 clean 오프라인 데이터셋을 정리하는 데 필요한 수작업을 인간의 피드백으로 대체할 것을 제안함
(6) 본 연구의 기여점
- 인간의 피드백을 통합하여 오프라인 데이터로부터 기술을 추출하고, 그 기술을 활용하여 downstream 과제를 해결하는 Skip 알고리즘을 소개함
- data-driven 기술 추출을 위한 기존의 방법과는 달리, Skip는 잡음이 많은 오프라인 데이터셋에서 구조화된 기술을 추출할 수 있음을 보여줌
- Skip는 로봇 주방 환경에서 복잡한 다단계 조작 과제를 해결하는 데 있어, 기존의 human-in-the-loop RL 및 기술 추출 baseline보다 훨씬 효율적임을 보여줌
2. Background
(1) Reinforcement Learning
- 강화학습 방법에서 흔히 하는 것처럼, 우리는 control process가 감가된 return을 가진 마르코프 의사결정 과정(MDP)라고 가정함
- MDP는 다음과 같은 튜플로 정의됨 : $M=(S, A, R, \rho_{0}, \gamma)$
- $S$ : 상태 공간
- $A$ : 행동 공간
- $R = R(s,a)$ 보상 함수
- $\rho_{0}$ : 초기 상태 분포 $s_{0} \sim \rho_{0}(\cdot)$
- discount factor $\gamma \in [0, 1)$
- Control policy는 MDP에 있는 상태를 행동으로 변환함 : $a \sim \pi(\cdot|s)$
- value function $V^{\pi}(s)$ : 초기 상태에 대해 예상되는 미래 return에 대한 가치
- action-value function $Q^{\pi}(s,a)$ : 초기 (상태-행동) 쌍에 대해 예상되는 미래 return에 대한 가치

- 강화학습의 목표는 최적 정책을 학습하는 것임

- 표준 MDP 설정 외에도, 우리의 방법은 (상태-행동) squences를 기술로 매핑하는 인코더와 (상태-기술) 쌍을 atomic 행동으로 매핑하는 디코더로 구성된 기술을 학습할 것임

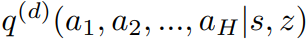
3. Method
(1) Skip 알고리즘의 개요
- Skip의 두 가지 주요 기여
- 노이즈가 많은 데이터로부터 구조화된 기술을 학습하기 위해 기술 추출 과정 도중 인간의 피드백을 도입하는 것
- downstream RL의 학습을 위해 인간의 기술 선호도를 활용하는 것
- 본 접근 방식은 그림 1에서 개략적으로 보여지며, 알고리즘 1에서 자세히 설명됨.
- 행동 우선 순위를 학습하기 위해, 인간의 피드백을 활용하는 것으로, 오프라인 데이터로부터의 기술 추출 이전 접근 방식들과 달리, 우리의 방법은 최적이 아니거나 노이즈가 많은 데이터에 대해서도 강건함


(2) The Skip Algorithm
- 알고리즘 1에 나타난 바와 같이, Skip는 두 단계로 구성됨 : 1) 기술 추출, 2) 기술 실행
- human teacher은 두 단계 모두에서 피드백을 제공함
- 기술 추출 동안, human teacher는 궤적이 선호되는지 아닌지를 라벨링하며(자세한 내용은 4절 참조), 이를 통해 선호도 분류기를 학습함
- 그런 다음 행동 우선순위는 가중 인간 선호도 함수와 함께 오프라인 데이터에 적합하게 설정됨
- 기술 실행 동안, 배운 기술은 RL 에이전트(Soft Actor Critic, SAC)에 의해 실행되며, 이는 과제 특정 인간 선호도로 학습됨
- 이와 같이, 인간의 피드백은 알고리즘의 두 단계에서 모두 사용됨.
(3) Preliminaries and Notation : 기술 추출 단계에서 주어지는 것들
- 오프라인 데이터셋 D가 주어지며, 이는 task-agnostic, multi-modal, noisy demonstrations이 포함되어 있음
- trajectory sequences as $\tau_{t} = (s_{t}, a_{t}, \cdots, s_{t+H-1}, a_{t+H-1})$
- action sequences as $a_{t} = (a_{t}, \cdots, a_{t+H-1})$
- action sequences로 디코딩되는 skils : $z \in Z$
(4) Learning Behavioral Priors with Human Feedback (Skill Extraction)
- 본 연구의 주요 통찰 : 인간의 선호도를 사용하여, 잠재적으로 잡음이 있는 demonstrations으로 구성된 오프라인 데어티셋에 대해 가중된 행동 우선순위를 적용하는 것.
- 본 방법은 expected maximum likelihood latent variable 모델을 통해 오프라인 데이터에서 행동 추출을 위한 이전 연구를 기반으로 함
- 기존 연구는 행동 우선 순위를 나타내고, 오프라인 데이터셋의 transtion statistics를 재현하도록 학습된 행동 시퀀스에 대한 매개변수화된 generative model $p_{\alpha}(a_{t}|s_{t})$를 고려함. 여기서 $a_{t} = (a_{t}, \cdots, a_{t+H-1})$
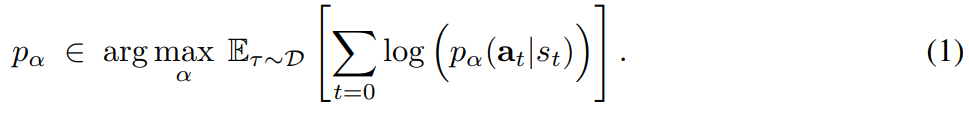
- 우리의 접근 방식에서는 인간의 선호도 함수에 따라 더 높은 보상을 달성하는 궤적을 향해 편향된 적응형 행동 우선순위를 고려함
- 이는 최적이 아니거나 노이즈가 있는 정책, 또는 다양한 전문성을 가진 여러 정책으로 수집된 다양한 데이터셋에서 특히 유용할 수 있음
- 예를 들어, 여러 인간이 시연을 수집하거나 여러 로봇이 환경을 탐색하는 것을 상상할 수 있음
- 본 연구는 데이터셋 내에서 높은 보상 궤적을 향해 편향되면서도 데이터셋의 평균 통계에 가까이 머무는 행동 우선순위를 추구함
- 그러나, 가중 행동 우선순위에 대한 이전 연구들과 달리, 가중치는 인간의 선호도 함수를 통해 결정되며, 우리는 단일 타임 스텝 행동이 아닌 행동 시퀀스의 likelihood를 극대화하려고 함. 이를 다음과 같이 수식화함
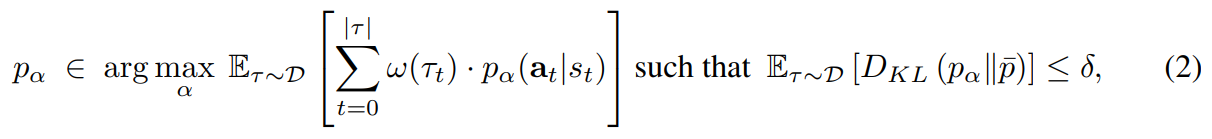
- $\bar{p}$ : empirical behavioral policy
- $w(s_t, a_t)$ : 가중치 함수
- 위 최적화 문제에 대한 non-parametric 해결책은 다음과 같이 주어짐

- 정규화 factor를 명시적으로 피하기 위해 비례 기호 $\propto $ 를 사용함
- $\eta $ : 수식 (2)에 있는 constraint level $\delta $와 관련 있는 temperature parameter을 표현
- 위 해결책은 다음과 같이 parametric neural network의 공간으로 투영될 수 있음

- 가중치 함수 $w(\tau_{t})$의 선택을 위해, 우리는 학습된 선호도 분류기 $P_{\psi }(y|\tau)$를 사용함. 이때 입력은 궤적 $\tau$이고 $y \in [0,1]$를 사용하여 이 궤적이 인간이 선호하는 것일 가능성을 출력함
- $P_{\psi}(y|\tau)$는 오프라인 데이터셋의 작은 부분 집합을 샘플링하고 인간의 피드백을 요청하여 선호하는 궤적과 선호하지 않는 궤적을 라벨링함으로써 학습됨 : $w(\tau_{t}) := log P_{\psi} (\tau_{t})$
- 이 과정에서 우리는 temperature $\eta $를 하이퍼 파라미터의 선택으로 취급함
- 이는 암묵적으로 constratint threshold $\delta$를 정의하며, 문제의 명세와 최적화를 더 간단하게 만듦
- 실제 구현에서 우리는 선행연구 [15,17]과 유사한 variational autoencoder를 적용하지만, 인간이 선호하는 transition의 likelihood를 극대화하기 위해 부드럽게(?) 가중시킴
- 우리는 ELBO 손실이 주어지는 Gaussian prior를 가진 latent variable z를 도입함

- 위 손실 함수는 action sequence modeling에 적용되는 standard $\beta$-VAE loss이다. 이때 $\beta$는 정규화 강도를 조절하는 스칼라 값이고, $\phi_{1}, \phi_{2}$는 neural network 파라미터이다.
- $q_{\phi_{2}}$는 trajectories를 latent vector로 인코딩 한다.
- $p_{\phi_{1}}$는 latent vector와 시작 상태를 다시 action sequences로 디코딩 한다.
- 우리의 학습 목표는 위 ELBO 손실을 선호도 함수로 가중하는 것임
- 따라서 최종적인 skill extraction objective는 다음과 같이 정의함

(5) Reward learning and human preferences over skills (Skill Execution)
- 전통적인 강화 학습에서는 수작업으로 설계된 보상이 사용되지만, 우리는 선호도 기반 강화 학습 프레임워크를 고려함 : human teacher가 에이전트의 행동 간 선호도를 제공하고 에이전트는 이 피드백을 사용하여 과제를 수행함
- 심층 강화학습에 인간의 선호도를 통합하기 위해, Christiano et al. [11]은 선호도로부터 보상 함수 $\hat{R_{\eta}}$를 학습하는 프레임워크를 제안함
- 이 연구에서 우리는 선호도 프레임워크를 atomic state-action transitions에 대해 작동하는 것이 아니라, 훨씬 더 긴 시간 범위를 가지는 상태-기술 transtions에 대해 작동하도록 수정함
- 공식적으로, 우리는 상태-행동 transitions이 담긴 오프라인 데이터셋(에이전트의 replay buffer) $\beta$에 접근할 수 있다고 가정함.
- 그리고 state-skill sequence pairs $\tau_{1}^{(z)}, \tau_{2}^{(z)} $를 샘플링함.
- 이는 사람이 제공하는 binary label $y \in {0,1}$이다.
- 이때 $ \tau^{(z)} = (s_{t}, z_{t}, s_{t+H}, z_{t+H}, \cdots, s_{(t+M)H}, z_{(t+M)H})$.
- 이때 H는 기술이 디코딩되는 행동의 길이이며, M은 (상태-기술) transtions의 총 수 이다.
- 이러한 궤적들이 M 길이의 (상태-행동) 궤적을 샘플링하는 경우보다 H배 더 길다는 점에 유의해야 함
- 따라서 보상 함수 $\hat{R}$은 시퀀스에 걸쳐 베르누이 분포에 적합하게 됨
- 본 연구에서는 Bradley-Terry 모델을 활용하여 매개변수화 된 보상 함수 $\hat{R_{\eta}}$을 다음과 같은 방식으로 학습함

- $A \succ B$ : 'A를 B보다 선호하다'를 의미함
- 따라서 $\hat{R_{\eta}}$는 라벨이 인간의 피드백을 통해 제공되는 이진 선호도 분류기로 해석될 수 있음
- neural network의 파라미터 $\eta$는 binary cross-entropy loss을 최적화함으로써 업데이트 됨

4. Experimentual Setup
(1) Environments
- D4RL suite에서 로봇 주방 환경과 오프라인 데이터셋을 사용함
- 이 환경은 7자유도 로봇 머니퓰레이터(6자유도의 로봇 머니퓰레이터와 1자유도의 그리퍼)이 주방에서 복잡한 다단계 과제를 해결하는 것을 요구함
- 7자유도 제어와 과제의 복합적인 장기 지평 특성 때문에, 이 환경은 SAC나 BC와 같은 표준 방법으로 해결될 수 없음
(2) Offline dataset
- random 정책에 의해 생성된 601의 노이즈가 섞인 궤적과 전문가의 601개의 궤적이 결합된 오프라인 데이터셋을 사용
- 전문가의 궤적은 전자레인지를 여는 것과 스토브를 조작하는 것과 같이 다양한 구조화된 주방 상호작용을 포함함
- 본 연구에서는 총 궤적의 10% 또는 동등하게 120개의 인간 라벨에 대한 인간의 피드백을 요청함
(3) Downstream tasks
- 본 연구는 아래의 그림 2에 나타난 난이도가 다양한 6개의 다른 downstream 과제를 사용하여 본 연구의 접근 방식을 평가함
- 이 과제 모음은 전체 목표를 달성하기 위해 연속으로 한, 둘 또는 셋의 하위 과제를 완료해야 하는 과제로 구성됨

(4) Simulated human
- 이전 연구들과 유사하게, 우리는 실제 인간 대신 시뮬레이션된 human teacher로부터 피드백을 얻음
- 기술 추출 중에는 궤적이 잡음이 많은지, 혹은 구조화되었는지에 대해 사람이 라벨을 제공함
- 기술 실행 중에는 시뮬레이션된 인간이 원하는 과제를 완료하기 위한 진전을 더 많이 이룬 궤적 부분에 긍정적인 라벨을 할당함
5. Experimental Results
(1) 실험 질문
- Skip는 도전적인 장기적 과제를 해결할 수 있을까? 그리고 이전의 접근 방법들과 어떻게 비교될까?
- 완벽한 전문가 시연으로부터 기술을 추출하고 실제 보상에 접근 가능한 oracle 기준과 Skip는 어떻게 비교될까?
- 기술 추출 중 인간의 피드백을 제공하는 것은 필요할까? 아니면 오프라인 데이터에 대해 가중치가 없는 행동 우선순위를 적용하는 것으로도 충분할까?
- 기술 실행 단계 중 인간의 피드백을 어떻게 통합해야 할까?
(2) 메인 실험
- 비교 대상
- Skip 3x : Skip 보다 human 라벨을 3배 이상 쓴 알고리즘
- Skip : 본 연구에서 제안하는 기법
- PEBBLE : 기존 SOTA human preference RL 알고리즘
- Flat Prior : 최적 데이터셋 위의 원자적 행동 공간에서 단일 단계 행동 우선순위를 학습하고, 실제 보상을 가진 행동 우선순위로 규제된 온라인 SAC 에이전트를 학습함 (?)
- Oracle : expert demonstrations과 ground truth reward가 제공되는 알고리즘
- 아래의 그림 4를 보면, 모든 task에서 Skip 3x와 Skip의 성능이 좋음
- human label이 증가한 Skip 3x과 Skip의 성능 차이가 크게 나지 않음. 이에 따라 human label의 효율성을 증가시키는 후속 연구가 필요함.

(3) 서브 실험 1 : 인간의 피드백이 꼭 필요할까?
- Skip (has human feedback) : 기술 추출 과정에서 human feedback을 사용한 모델
- Skip (no human feedback) : 기술 추출 과정에서 human feedback을 사용하지 않은 모델
- 아래의 그림 5에서 Skip (has human feedback)의 성능이 훨씬 우수함을 확인할 수 있으며, 최적이 아닌 오프라인 데이터에서 기술 추출에 인간 피드백이 필수적임을 시사함

(4) 서브 실험 2 : 인간의 피드백을 어떻게 통합해야 할까?
- 선호도 대신, 인간의 피드백에서 학습하는 더 간단한 접근 방법 : 과제(또는 하위 과제)가 해결되었는지에 대한 이진 피드백을 제공하고 보상 분류기를 학습하여 RL 에이전트에게 안내하는 방법
- Skip (with preference) : 인간의 선호도로 보상 분류기를 학습한 Skip 기법 (본 연구 기법)
- Skip (with learned sparse reward) : 과제 성공 여부로 보상 분류기를 학습한 Skip 기법
- 아래의 그림 6을 보면, 하위 과제 완료를 위한 보상 분류기를 가진 RL은 일부 과제를 해결할 수 있지만, 일반적으로 인간의 선호도를 가진 RL보다 훨씬 더 나쁜 성능을 보이고 있음

6. Related work : Human-in-the-loop RL
- 주요 연구 방향 중 하나는 인간의 피드백을 학습 신호로 직접 활용하는 것. 하지만 인간의 피드백이 많이 필요로 하는 복잡한 과제에서 실용적이지 않음
- 이러한 한계를 해결하기 위해, 많은 연구들이 인간 피드백으로부터 보상 모델을 학습하는 것을 제안함. 하지만 이러한 방법들은 단기적 또는 순환적인 과제에 국한됨
- 본 연구에서는 기술에 대한 선호도를 지정함으로써 이러한 도전적인 과제에 인간 선호도를 어떻게 확장할 수 있는지 조사함.
7. Conclusion
- Skip 알고리즘은 기술 추출 뿐만 아니라 기술 실행을 위해 인간의 피드백을 사용함
- Skip는 로봇 에이전트가 장기적이고 구성적인 조작 과제를 해결할 수 있게 해준다는 것을 보여줌
- 이 연구가 기술과 인간의 피드백을 통한 학습의 잠재력에 대해 다른 연구자들에게 흥미를 불러일으키기를 바람