
티스토리 뷰
강화학습 논문 정리 10편 : A workflow for Offline Model-Free Robotic Reinforcement Learning 논문 리뷰 (CoRL 2022)
hanyangrobot 2023. 10. 24. 14:32작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB)
논문 링크 : https://proceedings.mlr.press/v164/kumar22a.html
A Workflow for Offline Model-Free Robotic Reinforcement Learning
Offline reinforcement learning (RL) enables learning control policies by utilizing only prior experience, without any online interaction. This can allow robots to acquire generalizable skills from ...
proceedings.mlr.press
홈페이지 링크 : Offline RL Workflow (google.com)
Offline RL Workflow
Main Paper + Appendix: Paper Link DR3 used in this paper: DR3 preprint
sites.google.com
발표 영상 링크 : https://www.youtube.com/watch?v=h9R5LJX9b1I
Abstract
(1) 오프라인 강화학습의 장점 및 한계점
- 비용이 많이 드는 또는 위험한 온라인 데이터 수집 과정이 없이도 크고 다양한 데이터셋에서 일반화된 기술을 학습할 수 있음
- 그러나, 실제로 학습된 정책을 온라인에서 평가하지 않고 모델 아키텍쳐부터 알고리즘의 하이퍼 파라미터에 이르는 다양한 설계 선택사항을 결정하는 명확하고 잘 이해된 프로세스는 없음
(2) 제안하는 방법 : 오프라인 강화학습을 사용하기 위한 실용적인 workflow 개발
- 본 연구의 목표는 지도 학습 문제에 대해서 상대적으로 잘 정립된 workflow와 유사한 오프라인 강화학습 전용 실용적인 workflow를 개발하는 것
- 오프라인 학습 과정 중에 추적(?)될 수 있는 일련의 지표와 조건을 개발
- 이를 통해 알고리즘과 모델 아키텍쳐가 어떻게 조정되어야 최종 성능을 향상시킬 수 있는지에 대한 방향을 제시함
- 본 workflow는 지도 학습에서의 cross validation과 conservative offline RL 알고리즘의 행동에 대한 개념적인 이해에서 파생됨
- 본 workflow의 효과성을 여러 시뮬레이션에서 학습된 로봇 학습 시나리오와 두 종류의 실제 로봇에서 3가지 작업에 대해 입증함
1. Introduction
(1) 오프라인 강화학습을 위한 workflow의 필요성
- 온라인 강화학습은 학습 중에 발견된 sub-optimal 정책이 환경에서 실행되어 더 다양한 데이터를 수집할 수 있음
- 데이터 수집 과정에서 sub-optimal 정책이 수행한 행동에 대한 보상을 받음으로써 자연스럽게 정책 성능의 평가를 허용하게 됨
- 반면에, 오프라인 강화학습은 학습 중에 발견된 정책을 평가하기 위해 온라인 평가를 진행할 수 없음
- 따라서 오프라인 강화학습에서 현실 세계 구동에 대한 튜닝을 요구하지 않고 좋은 성능의 정책을 얻기 위해 신뢰성 있고 일관되게 모델 용량, 정규화 등을 조정하는 데 사용될 수 있는 일련의 프로토콜과 지표들이 필요함.
(2) 기존 오프라인 강화학습 연구의 workflow
- 기존 연구들은 Off-Policy Evaluation(OPE) 방법을 활용하여 오프라인 강화학습에서 모델의 선택을 연구해왔음
- 그러나 신뢰할 수 있는 OPE 방법을 개발하는 것 자체는 여전히 미해결된 문제임.
- 우리가 학습한 정책이 얼마나 좋은지에 대한 정확한 추정치가 필요하지 않으며, 대신 다양한 알고리즘 하이퍼 파라미터를 조정함으로써 정책을 최적화하는 workflow가 필요함!!
(3) 제안하는 workflow : 오프라인 강화학습에 대해 정규화 요소, 모델 아키텍처 및 정책 체크포인트를 선택하기 위한 실용적인 workflow
- 지도 학습은 학습 및 검증 loss value를 추적하여 over-fitting과 under-fitting을 감지하고, 이러한 지표를 기반으로 하이퍼 파라미터를 조정함
- 이와 유사하게 본 workflow도 먼저 오프라인 강화학습에 대한 over-fitting과 under-fitting을 정의하고, 이를 추적할 수 있는 지표와 조건들을 제안함.
- 그런 다음에 이러한 지표들을 사용하여 신경망 아키텍쳐, 정규화 및 early-stopping과 관련된 디자인 방향을 제시함
- 또한 이 workflow는 실제 세계의 온라인 평가 없이 알고리즘 파라미터를 어떻게 수정해야 하는지에 대한 지침을 제공함
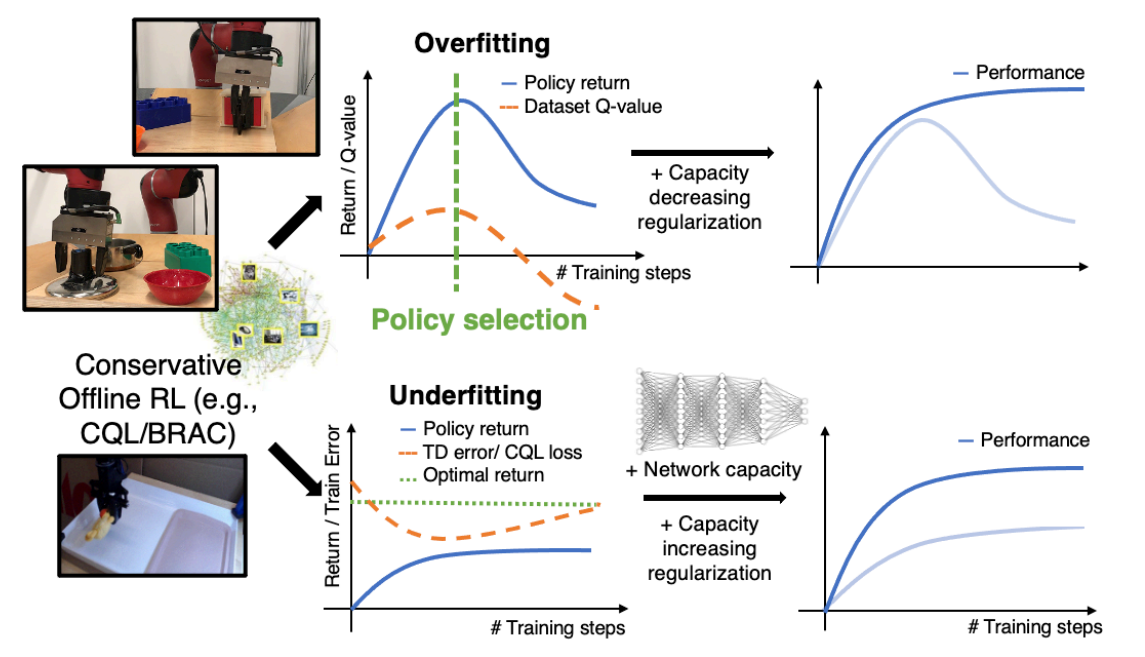
(4) 연구의 기여점
- 기여점 : Robotic Offline RL을 위한 단순하면서도 효과적인 workflow
- CQL, BRAC와 같은 conservative offline RL 알고리즘을 위해 아래의 사항을 선택하는 데 도움을 줄 지표와 프로토콜을 제안
- 정책 체크 포인트
- 정규화 파라미터
- 모델 아키텍쳐
- 시뮬레이션된 로봇 머니퓰레이션 문제에 대한 다양한 객체, pixel observation, 그리고 희소환 이진 보상을 사용하여 제안한 workflow의 효과를 실험적으로 검증함
- CQL, BRAC와 같은 conservative offline RL 알고리즘을 위해 아래의 사항을 선택하는 데 도움을 줄 지표와 프로토콜을 제안
2. Preliminaries, Background, and Definitions
(1) Basic
- RL의 목표 : infinite horizon discounted return $R$을 최적화하는 것
- $R = \sum ^{\infty }_{t=0}\gamma^{t}r(s_t, a_t)$
- $r(s_t, a_t)$ : 상태-행동 쌍에 대한 reward function
- $R = \sum ^{\infty }_{t=0}\gamma^{t}r(s_t, a_t)$
- 본 연구는 offline RL 환경에서 작동하며, 고정된 데이터셋 $D = {(s, a, r(s, a), s')}$ 이 제공됨
- $D$ 는 behavior policy $\pi_{\beta}(a|s)$ 에 의해 수집된 transtion tuples을 포함
- offline RL의 목표 : 고정된 offline dataset $D$ 만을 가지고 학습해서 최적 정책을 구하는 것 (이때 online dataset은 없음)
- 중점적으로 바라보는 offline RL 알고리즘 : conservative offline RL 알고리즘
- Q-function이 distributional shift를 패널티주기 위해 수정한 알고리즘
- 본 연구에서는 CQL 알고리즘을 중심으로 분석하고, 부록에서는 BRAC 알고리즘도 실험을 진행
(2) Conservative Q-Learning (CQL)
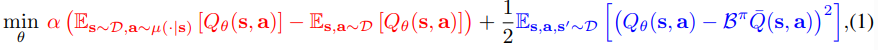
- Blue term : TD error를 최적화하는 term
- Red term : out-of-distribution(OOD) 행동에 대한 Q-value의 over-estimation을 방지하는 term
- 핵심 : 데이터셋에 있는 행동에 대한 Q-value는 최대화하고, 그 외의 행동에 대한 Q-value는 최소화하기!
(3) Overfitting and underfitting in CQL

- CQL에서 오버 피팅과 언더 피팅을 정의하기 위해, 위와 같은 최적화 공식 (2)를 고려해보자.
- $J_D(\pi)$ : offline dataset $D$에 있는 transitions에 의해 유도된 MDP에 대한 학습된 정책(learned policy) $\pi$의 average return을 의미함
- $D \left (\pi, \pi_{\beta} \right)$ : learned policy $\pi$와 behavior policy $\pi_{\beta}$ 간의 확률 분포 차이
- 이때 오버 피팅과 언더 피팅을 아래의 표와 같이 정의할 수 있음

- conservative offline RL에서의 오버피팅과 언더피팅을 도식화하면 아래의 그림과 같음
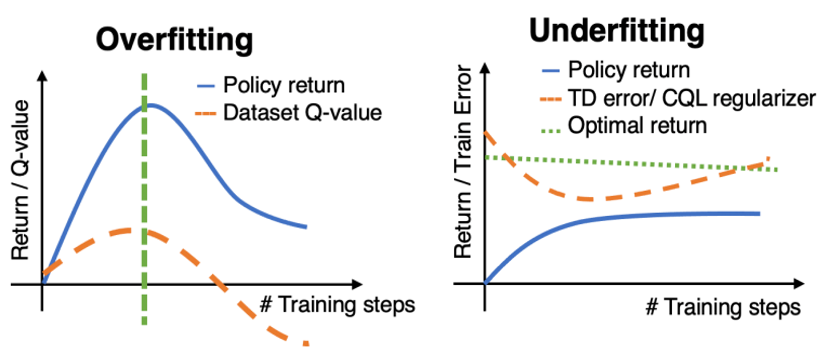
3. Detecting Overfitting and Underfitting in Conservative Offline RL
(1-1) Detectiong Overfitting in CQL
- 오버피팅의 정의 : training loss(= 2절에 있는 수식 1)는 낮지만, 실제 정책 $J(\pi)$의 성능은 낮은 현상
- 오버피팅 탐지 방법 : 학습 횟수에 따른 dataset Q-value의 경향성을 분석
- dataset Q-value를 구하는 법 : 오프라인 데이터셋 $D$에서 샘플된 transtions $(s, a, r, s') \in D$에 대한 추정된 Q-value들의 평균 값을 산출
- 아래 그림과 같이 처음에 dataset Q-value(주황색 점선)가 증가하다가 감소하는 경향을 보이면 오버피팅이라고 판단!
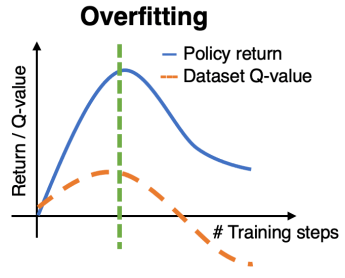
- 추가적으로 2절에 있는 수식 1인 training loss는 계속해서 줄어들고 있을 것이다... 오버피팅 현상이 왜 발생하는 걸까?
- CQL은 데이터셋에 없는 OOD 행동에 대한 Q-value에 패널티를 주기 때문에, (데이터셋에서 샘플된 state, learned policy가 선택한 행동(=OOD 행동일 확률이 높음))에 대한 Q-value가 작아지게 됨
- 이는 (데이터셋에서 샘플된 state, 데이터셋에서 샘플된 action)에 대한 Q-value도 감소하는 것으로 이어질 수 있음
(1-2) What does a low average data Q-value imply about $J(\pi)$ ?
- 본문의 부록 A를 통해 다음의 결과를 얻을 수 있음
- CQL은 dataset Montel-Carlo return 보다 작은 Q-value를 절대로 학습하지 않음 (=CQL은 최적 정책을 찾을 수 있음)
- learned policy $\pi$가 behavior policy $\pi_{\beta}$보다 나은 경우를 제외하고는 Q-value가 증가해야 함
- 직관적으로 식 1의 목표가 average dataset Q-value를 최대화하기 위해서도 있기 때문이며, 따라서 behavior policy에 대한 Q-value는 과소평가되지 않음
- 이제, policy optimizer가 dataset return보다 더 작은 learned Q-value를 얻는 정책을 찾게 되면, Q-value를 높이기 위해 정책을 behavior policy 쪽으로 더욱 업데이트 할 수 있음
- 즉, CQL에 의해 찾아진 정책(=learned policy)이 behaivor policy보다 더 좋을 때만 Q-value이 감소할 수 있음
- 따라서 low average data Q-value은 다음과 같은 의미를 지님 : Q-function이 learend policy에서 샘플된 행동에 대한 Q-value를 매우 작게 예측한다. (음? 크게 예측해야 위 문장과 성립되는거 아닌가? 이 부분은 정확히 이해가 안가네요..)
- 일반적으로 이는 상태 s에서 가장 높은 Q-value를 지닌 행동 a가 behavior policy에서 생성된 offline dataset에서 샘플링된 것이라는 것을 의미함
- 따라서 Q-value를 최대화하려는 policy optimization은 learned policy를 behavior policy에 더 가깝게 만들 것임.
(1-3) Which training checkpoint is likely to attain the best policy performance?
- 추정된 dataset Q-value 값이 최고점에 해당하는 가장 최근의 체크 포인트를 선택해야 함. (1-1에 있는 오버피팅 탐지법 그림에서 초록색 점선을 의미)
- offline RL에서 오버피팅의 정의와 이에 대한 정책 체크 포인트 선택 방법을 요약하면 아래와 같음.


(2-1) Detecting Underfitting in CQL
- 언더피팅의 정의 : 수식 1의 학습 목적 함수를 효과적으로 최소화하지 못할 때를 언더 피팅이라고 정의함.
- CQL regularizer(수식 1에서 red term)가 큰 값을 지닌다는 것은 true Q-value 보다 Q-value를 over-estimation 했다는 것을 의미함.
- 따라서 오버피팅 때와 같이 dataset Q-value가 감소할 것이라고 예상하지 않음
- 언더피팅 탐지법 : 아래의 (2-2)에서 언급.
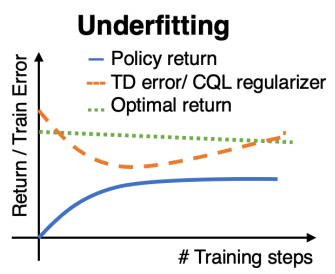
(2-2) How do we determin if the TD error and the CQL regularizer are large?
- 언더피팅 탐지법 1
- 시도 1 : 현재 모델에서 TD error(수식 1의 blue term)과 CQL regularizer(수식 2의 red term) 값을 측정
- 시도 2 : 현재 모델보다 모델 용량(레이어 수, 노드 수 등등..)이 큰 모델에서 TD error과 CQL regularizer를 측정
- 결과 : 시도 2의 TD error과 CQL regularizer 값이 시도 1보다 작으면, 현재 모델이 언더피팅 상태에 있다고 판단!
- 언디피팅 탐지법 2 (주로 사용되지는 않음)
- TD error $ L_{TD}\left ( \theta \right ) $와 task horizon $ 1 / \left ( 1 - \gamma \right ) $을 활용하여 learend Q-value와 actual Q-value에 대한 전체 오류를 추정하기.
- actual Q-value는 $ L_{TD}\left ( \theta \right )/ \left ( 1 - \gamma \right ) $ 와 동일
- 전체 오류가 task에서 허용되는 Q-value의 범위(task의 보함 함수의 구조를 기반으로 추론)에 걸쳐 있으면 현재 알고리즘이 언더피팅되고 있다고 판단.
- TD error $ L_{TD}\left ( \theta \right ) $와 task horizon $ 1 / \left ( 1 - \gamma \right ) $을 활용하여 learend Q-value와 actual Q-value에 대한 전체 오류를 추정하기.

4. Addressing Overfitting and Underfitting in Conservative Offline RL
(1) Capacity-decreasing regularization for overfitting
- 첫번째 해결책 : dropout과 같은 정규화 기법을 Q-function layer에 적용하기
- 두번째 해결책 : 학습된 Q-function의 표현이 모든 (상태-행동) 튜플에 대해 pre-specified target과 일치하도록 강제하기
- 이를 위해 학습된 표현에 variational information bottleneck(VIB) 정규화를 적용
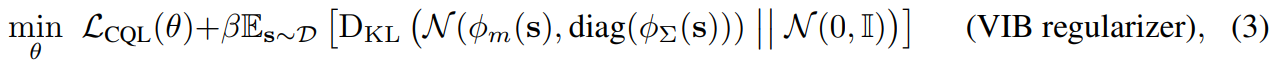
- 오버피팅에 대한 해결책을 요약하면 아래와 같음

(2) Capacity-increasing techniques for underfitting
- 첫번째 해결책 : ResNet, transformers와 같은 깊은 심층 신경망 모델 활용하기
- 두번째 해결책 : DR3 정규화 기법 적용하기

- 언더피팅에 대한 해결책을 요약하면 아래와 같음

5. Evaluation of Our workflow Metrics and Protocols in Simulation
(1) Experimental setup
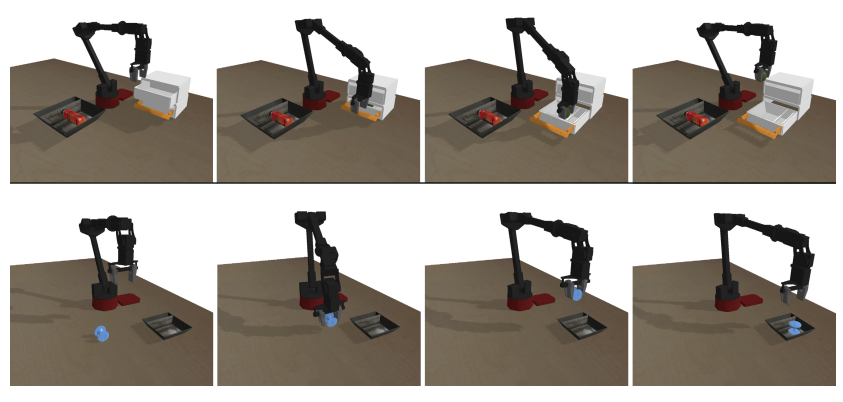
- 실험 목표 : 3절의 workflow를 적용하여 오버피팅 및 언더피팅를 탐지하고, 4절의 전략 효과를 검증하기.
- 실험 환경
- 작업 1 : Picak and Place
- 상자 앞에 6 자유도 Widow X 로봇이 있음
- 작업 목표 : 상자 밖에 있는 물건을 집어서 상자 안에 물건을 넣는 것.
- 이진 보상 제공 (상자 안에 물건을 놓았을 때만 보상 +1, 그 외는 0)
- 오프라인 데이터셋 구성 : 35%의 성공률을 지니는 물건 파지 궤적 + 40% 성공률을 지니는 물건 놓기 궤적
- 작업 2 : Grasping from drawer task
- 서랍 앞에 6 자유도 Widow X 로봇이 있음
- 작업 목표 : 서랍 안에 있는 물건을 꺼내기
- 이진 보상 제공 (서랍 안에 있는 물건을 꺼내면 보상 +1, 그 외는 0)
- 오프라인 데이터셋 구성 : 30~40% 성공률을 지니는 서랍을 여닫는 궤적 + 40% 성공률을 지니는 물건 꺼내는 궤적
- 모든 실험에서 CQL regularizer term의 영향력을 조절하는 $\alpha$ 값은 1로 설정함
- 작업 1 : Picak and Place
(2) Scenario #1: Variable amount of training data.

- 실험 목표 : 학습 데이터 개수(50, 100, 500, 10000개)에 따른 성능 비교
- 오버피팅/언더피팅 판단
- 왼쪽 그래프를 보면 데이터 개수가 적을수록 오버피팅이 빠르게 오는 것을 볼 수 있음 (판단 지표 : data Q-value)
- 중앙 그래프를 보면 CQL regularizer 값이 매우 작은데, 이로써 언더피팅은 아니라는 것을 알 수 있음
- 따라서 해당 현상은 오버피팅이라고 판단할 수 있음 (특히 데이터 개수가 50, 100개일 때!)
- 정책 체크 포인트 설정 : 왼쪽 그래프에서 dashed line이 있는 지점에 해당!
- VIB 정규화는 오버피팅에 효과가 있는가? : 오른쪽 그래프의 주황색 선을 보면 효과가 있음을 확인할 수 있음.
(3) Scenario #2: Multiple training objects.

- 실험 목표 : 물체 개수(1, 5, 10, 20, 35개)에 따른 성능 비교
- 각 물체마다 다른 형태와 외관을 가지고 있기 때문에, 더 많은 수의 물체를 파지하려면 더 큰 모델 용량이 필요
- 각 물체 개수 경우에 5000개의 trajectories 제공
- 오버피팅/언더피팅 판단
- 오른쪽 그래프를 보면 학습이 진행됨에 따라 Q-value가 감소되고 있지 않기 때문에, 오버피팅은 아님.
- 언더피팅인지 확인하기 위해 TD error 그래프(중앙 그래프)를 시각화했고, 물체 개수가 10, 20, 35개일 때의 TD 에러 값이 크다는 것을 확인함. 이에 따라 언더피팅임을 확인.
- 언더피팅 해결책 : 물체 개수가 35개인 경우에 언더피팅의 해결책인 1) 모델 용량 키우기(e.g. ResNet 아키텍쳐 적용), 2) DR3 정규화 적용하기를 적용함. 아래의 그래프와 같이 이는 효과가 있음을 확인할 수 있음.

6. Tuning CQL for Real-World Robotic Manipulation
(1) Sawyer manipulation tasks

- 작업 개요
- 2가지 작업을 수행 : 냄비에 뚜껑 덮기 & 서랍 열기
- 각 작업에 대한 100개의 trajectories를 오프라인 데이터로 활용
- 행동 유형 : XYZ 공간에서 3D 앤드 이펙터의 velocity control와 1D gripper open/close action을 사용. (자세한건 논문의 부록 D 확인)

- 실험 결과
- Dataset Q-value (왼쪽 그래프)
- CQL 학습 중에 dataset Q-value는 감소하지 않음 : 오버피팅 아님
- TD error (오른쪽 그래프)
- CQL 학습 중에 TD error 발산하고 있음 : 언더피팅 확인
- 모델 용량을 키운 ResNet을 적용함으로써 언더피팅 문제 해결!
- Dataset Q-value (왼쪽 그래프)
(2) WidowX pick and place task

- 작업 개요
- WidowX 250 로봇 머니퓰레이터로 Pick and Place 작업 수행
- 35%의 성공률인 200개의 trajectories가 오프라인 데이터로 사용
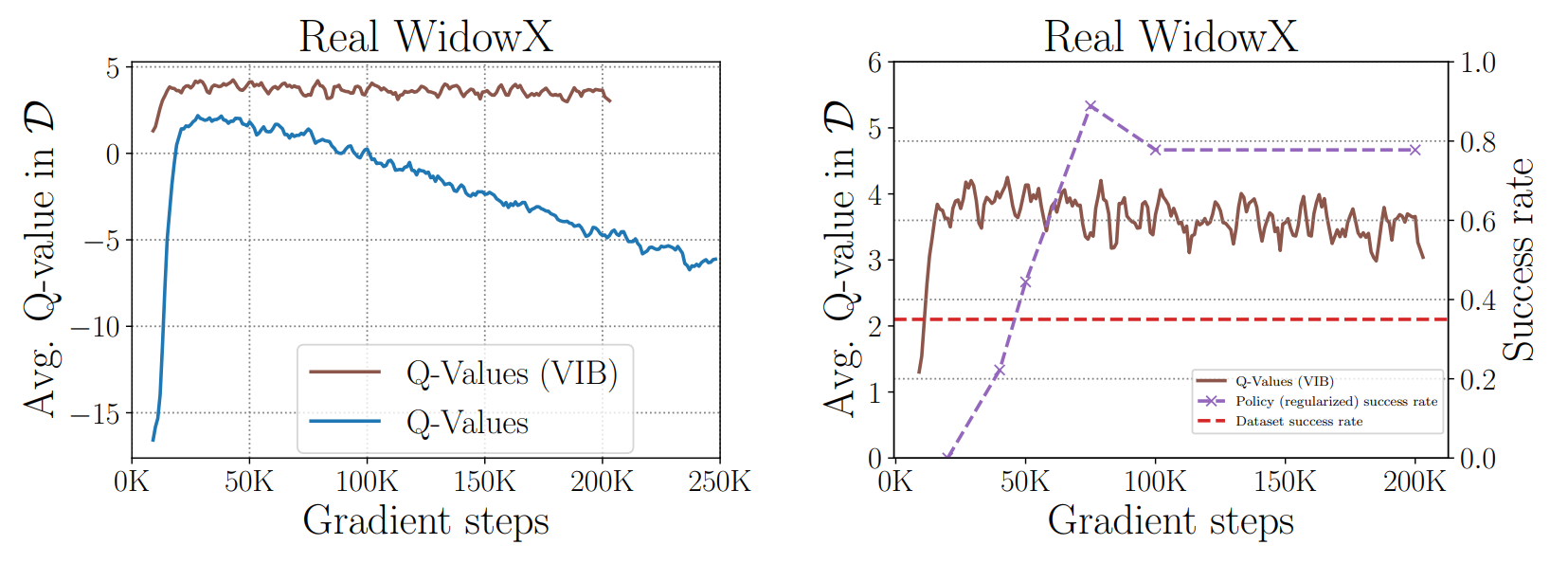

- 실험 결과
- 왼쪽 그래프를 보면 CQL의 Dataset Q-value 점차 감소하는 것을 볼 수 있으며, 이는 오버피팅 현상임.
- VIB 정규화를 적용하여 오버피팅 문제를 해결.
7 Discussion
- 본문은 CQL 및 BRAC와 같은 오프라인 강화학습 알고리즘을 위한 workflow를 제안
- 이 workflow는 오프라인 학습 과정에서 오버피팅/언더피팅을 감지하기 위해 추적할 수 있는 일련의 지표와 조건, 그리고 해결 방안으로 구성되어 있음.
- 그러나 workflow에 대한 이론적 근거가 부족하며, 이를 도출하는 것이 향후 연구 목표.