티스토리 뷰
[Robotics with LLMs 논문 정리 1편] Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents (2023 arxiv)
hanyangrobot 2024. 5. 22. 20:46작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB)
Keywords : Open-World, Interactive Planning, Multi-task Agents, Large Language Models, Minecraft
논문 링크 : https://arxiv.org/abs/2302.01560
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents
We investigate the challenge of task planning for multi-task embodied agents in open-world environments. Two main difficulties are identified: 1) executing plans in an open-world environment (e.g., Minecraft) necessitates accurate and multi-step reasoning
arxiv.org
깃헙 링크 : https://github.com/CraftJarvis/MC-Planner?tab=readme-ov-file
GitHub - CraftJarvis/MC-Planner: Implementation of "Describe, Explain, Plan and Select: Interactive Planning with Large Language
Implementation of "Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents" - CraftJarvis/MC-Planner
github.com
Abstract
(1) 연구 문제 정의 : Open-world 환경에서 multi-task를 수행하는 에이전트를 위한 Task Planning 문제

- 'Open-world 환경에서 multi-task를 수행하는 에이전트를 위한 Task Planning 문제'는 다음과 같이 2가지 어려움이 존재함
- 오픈 월드 환경(e.g. 마인크래프트)에서 planning을 실행하는 것은 task의 장기적인 특성 때문에 정확성과 multi-step reasoning이 필요
- Multi-task planning : 여러 작업을 동시에 또는 연속적으로 계획하고 수행하는 과정. 이는 특히 자원이 제한된 상황에서 효율성을 극대화하기 위해 사용됨.
- Multi-step reasoning : 문제를 해결하거나 결론에 도달하기 위해 여러 단계에 걸쳐 논리적으로 사고하는 과정. 예를 들어, 복잡한 수학 문제를 풀 때 문제를 여러 단계로 나누어 각 단계를 순차적으로 해결해 나가는 과정을 생각할 수 있음.
- vanilla planners는 복잡한 plan 내에서 parallel sub-goals를 정렬할 때 현재 에이전트가 주어진 sub-task를 얼마나 쉽게 달성할 수 있는지를 고려하지 않기 때문에, 결과적으로 plan이 비효율적이거나 실행 불가능할 수 있음
- valnilla planners 예시 : Breadth-First Search(BFS), Depth-First Search(DFS), A* 등등...
- (번외) 'vanilla'는 기본 또는 표준 알고리즘을 의미합니다!
아이스크림의 근본도 바닐라 맛이듯이 ㅎ
- 오픈 월드 환경(e.g. 마인크래프트)에서 planning을 실행하는 것은 task의 장기적인 특성 때문에 정확성과 multi-step reasoning이 필요
(2) 제안하는 방법론 : DEPS (Describe, Explain, Plan and Select!)

- DEPS는 Large Language Models (LLMs) 기반의 interactive planning 접근 방식이며, 다음과 같이 2가지 기능이 있음.
- 초기 LLM이 생성한 plan의 오류 수정을 촉진하는 기능
- plan의 실행 과정에 대한 설명(description)을 통합
- 확장된 planning 단계에서 실패했을 때 피드백의 자기 설명(self-explanation)을 제공
(중고등학생 때 작성했던 수학 오답 노트가 생각나네요 ㅋㅋ)
- 초기 LLM이 생성한 plan을 정제(refine)하는 기능
- 목표 선택기(goal selector)를 포함하는데, 이는 학습가능한 모듈로서 완료 예상 단계를 기반으로 parallel candidate sub-goals에 대해 순위를 매기는 역할을 수행 → vanilla planners의 문제점(=plan의 비효율성)을 극복
- 초기 LLM이 생성한 plan의 오류 수정을 촉진하는 기능
(3) 실험 결과 : 최초의 zero-shot multi-task agent
- 70개 이상의 마인크래프트 task를 robust하게 수행할 수 있는 최초의 zero-shot multi-task agent를 만들어내고, 전반적인 성능을 거의 2배로 향상시킴
- 추가 실험은 우리의 방법이 널리 채택된 non-open-ended 도메인(i.e., ALFWorld 그리고 tabletop manipulation)에서도 효과적임을 보여줌
- ablation and exploratory 연구는 우리의 설계가 다른 접근 방식을 어떻게 능가하는지 자세히 설명하며, 우리의 접근 방식으로 'ObtainDiamond' 대도전에서 유망한 진전을 제공함
1. Introduction
(1) 연구 문제 정의 : multi-task agent를 개발하고 이를 Open-world로 전이하는 것
- 복잡한 도메인에서 방대하고 다양한 과제를 수행할 수 있는 multi-task agent를 개발하는 것은 일반적으로 유능한 인공지능을 향한 주요 이정표 중 하나임
- 초기 주요 연구 : Hierarchical goal execution architecture의 사용
- Hierarchical Goal Execution Architecture는 복잡한 과제를 해결하기 위해 목표를 계층적으로 나누고 각 계층에서 목표를 실행하는 구조. 이 아키텍처는 high-level planner와 low-level controller로 구성됨.
- high-level planner는 목표를 설정하고 이를 하위 목표로 분해함
- low-level controller는 이러한 하위 목표를 실제 행동으로 수행함
- 이 아키텍쳐는 아래의 항목을 포함한 많은 로봇 공학 도메인에서 유망한 진전을 보이고 있음
- table-top and mobile manipulation
- 2D shape drawing
- table rearrangement
- Hierarchical Goal Execution Architecture는 복잡한 과제를 해결하기 위해 목표를 계층적으로 나누고 각 계층에서 목표를 실행하는 구조. 이 아키텍처는 high-level planner와 low-level controller로 구성됨.
- 그러나 이러한 성공이 무한한 탐색 영역과 인터넷 규모의 지식을 가진 open-ended world로 전이될 수 있는지는 여전히 미지수임

(2) 로봇 공학 도메인과 Open-world 도메인 간의 격차에 대한 이해
- 이러한 격차를 이해하기 위해, 우리는 기존의 Hierarchical goal execution architectures인 Inner Monologue를 다음의 환경에서 실행했음
- 대표적인 open-world 도메인 : 마인크래프트
- 고전적인 로봇 환경 : ALFWorld 및 tabletop 환경
- Inner Monologue 알고리즘은 세 환경 모두에 대한 도메인별 지식을 포함하는 LLM 기반 planner를 사용하며, 모든 환경에서 Oracle goal-conditioned 제어기 또는 학습된 제어기를 사용함

- 결과는 그림 1의 막대 그래프에 표시되며, 결과 분석은 다음과 같음
- 첫째, Oracle 제어기를 사용하더라도, 마인크래프트 과제를 실행하는 성공률이 다른 환경보다 훨씬 낮음
- 둘째, 학습된 제어기로 대체되면 마인크래프트에서의 과제 실패율이 더욱 높아짐 → 이러한 실패는 모두 open-world 환경에서 발생하는 고유한 도전 과제에서 비롯되며, 우리는 이를 다음에서 확인함
(3) Open-world 도메인의 어려운 점 1 : 정형화된 환경보다 긴 일련의 sub-goals을 필요로 함
- 정형화된 환경(e.g., Atari 게임 환경 및 로봇 제어 모듈)과 비교했을 때, open-world는 복잡한 의존성과 관계를 가진 매우 다양한 객체 유형을 가지고 있음
- 그 결과, ground-truth plans은 일반적으로 엄격한 의존성을 가진 긴 일련의 sub-goals을 포함함
- 그림 1의 도전 과제 #1이 시사하는 바와 같이, 마인크래프트에서 다이아몬드를 얻기 위해서는 적어도 13개의 sub-goals를 올바른 순서로 실행해야 함
- 반면에, tabletop manipulation task에서는 작업이 일반적으로 3~4개의 연속적인 sub-goals에 불과함

(4) Open-world 도메인의 어려운 점 2 : 생성된 plan의 실행 가능성

- 마인크래프트에서 침대를 만들기 위한 가장 빠른 방법은 양을 도살하여 양털을 얻어 침대를 만드는 것이나, 마을에서 침대를 수집하는 것임 (그림 1의 #2 참고)
- 그러나 3분의 게임 플레이 시간 내에 에이전트가 도달할 수 있는 양이나 마을이 없기 때문에, 침대를 효율적으로 만들기 위해 에이전트는 거미를 도살하고 얻은 재료(e.g. 실)를 사용하여 양털을 만들고, 그 후에 침대를 만들어야 함.
- 즉, 여러 가능한 sub-goals 시퀀스를 실행하여 완료할 수 있는 작업을 다룰 때, planner는 에이전트의 현재 상태에 따라 최선의 경로를 선택할 수 있어야 함
- 그러나 open-world 환경의 복잡하고 다양한 상태 분포는 상태 인식을 어렵게 만듦
(5) 제안하는 방법론 : “Describe, Explain, Plan and Select” (DEPS)
- DEPS는 LLMs을 기반으로 한 interactive planning 접근법으로, 앞서 언급한 2가지 문제점들을 완화시키기 위한 것임
- 첫번째 문제(긴 일련의 sub-goal이 필요함)를 해결하기 위한 핵심 : 실패 시 생성된 plan을 효과적으로 조정하는 것
- 구체적으로, 제어기가 sub-goal을 완료하지 못할 때 마다 descriptor가 현재 상황을 텍스트로 요약하여 LLM 기반 planner에게 다시 보냄
- 그런 다음 LLM을 descriptor로 사용하여 이전 plan에서 오류를 찾아내도록 함
- 마지막으로, planner는 descriptor로 부터 얻은 정보를 사용하여 plan을 수정함
- 두번째 문제(생성한 plan의 실행가능성은 현재 상태에 의존적임)를 해결하기 위한 핵심 : 가장 접근 가능한 sub-task를 선택하는 것
- 현재 상태에 조건화된 plan의 실행 가능성을 높이기 위해, 각 후보 sub-goal에 대한 접근성을 기반으로, 가장 접근 가능한 sub-task을 선택하기 위해 학습된 goal-selector를 사용
(6) 실험 결과 : DEPS는 마인크래프트에서 71개의 task를 성공적으로 수행하며, 다른 language plan 방법보다 거의 두 배 높은 성공률을 보임
- 우리의 실험은 open-world 마인크래프트에서 71개의 작업을 대상으로 demonstrations 없이 수행됨
- 원초적인 sub-task (e.g. 나무 캐기, 돌 캐기)에 대한 목표 조건 제어기를 제공하면, 우리의 zero shot LLM 기반 planner는 제한된 범위 내에서 모든 작업을 완료할 수 있음 (다른 task에 비해 3K-12K steps)
- 우리는 DEPS가 동일한 초기 상태와 목표 조건 제어기 하에서 모든 language planner 기준을 거의 두 배로 성공률을 높여 능가한다는 것을 발견함
- 우리의 ablation and exploratory 연구는 어떻게 우리의 접근 방식이 경쟁자들을 능가하고 도전적인 '다이아몬드 획득' 작업을 수행하는 첫 번째 plan 기반 에이전트가 되는지를 설명함
- DEPS는 환경에 대한 plan 학습이 필요하지 않음
- 또한 DEPS는 ALFWorld 및 Tabletop 환경과 같이 non-open world 로봇 도메인에서도 기존 또는 현재 LLM 기반 plan 방법에 비해 동등하거나 50% 이상의 상대적 개선을 달성함
2. Background
(1) 연구 목표 : goal-conditioned 정책과 planner를 결합하여 image observations과 language goals를 통해 long-horizon goal-reaching task를 해결할 수 있는 agent 개발
- goal-conditioned 정책의 역할 : sub-goal을 완료하기
- planner의 역할 : long-horizon task를 K개의 short-horizon sub-goals $g_1, g_2, \cdots, g_K$로 분해
- 각 time step $t$에서 goal-conditioned 정책 $\pi(a_t|s_t, g_k)$는 현재 상태 $s_t$와 특정 sub-goal $g_k$를 기반으로 행동 $a_t$를 생성함
2-1) Planning with Large Language Models
(1) 기존 LLMs의 역할 : task description을 sub-goals 시퀀스로 디코딩
- 이전 연구들은 embodied 환경에서 InstructGPT와 Codex와 같은 LLMs이 다양한 작업에 대한 sub-goal 시퀀스를 생성하는 zero-shot planner로 사용될 수 있음을 보여줌
- embodied 환경은 주로 로봇이나 가상 에이전트가 물리적 공간이나 가상 세계 내에서 상호작용하며 작업을 수행하는 환경을 의미. 이러한 환경에서는 에이전트가 물리적인 센서(예: 카메라, 마이크, 촉각 센서)를 통해 외부 세계를 인식하고, 이를 바탕으로 행동을 계획하고 실행함.
- 공식적으로, 주어진 task description $T$를 prompt $p$로 사용함
- Task description은 특정 작업이나 목표를 설명하는 문구나 문장을 의미함. 이 설명은 에이전트가 수행해야 할 작업의 세부 사항, 목표, 그리고 기대 결과를 포함함. 예를 들어, "책상 위에 있는 파란색 책을 집어서 선반에 놓아라"와 같은 설명이 작업 설명임. 이 설명은 에이전트가 무엇을 해야 하는지 명확하게 이해할 수 있도록 도와줌.
- Prompt는 LLM을 사용할 때 모델에 입력으로 제공되는 문구나 문장을 의미함. 이 prompt는 모델이 특정 작업을 수행하거나 질문에 답하도록 지시하는 역할을 함. 예를 들어, task description을 prompt로 사용하여 LLM이 이를 바탕으로 필요한 하위 목표나 단계를 생성하게 할 수 있음.
- 그 다음, LLM은 planner로서 $T$를 K개의 하위 목표 $g_1, \cdots, g_K$로 디코딩함
- 마지막으로, low-level controller $\pi(a_t|s_t, g_k)$가 이 sub-goals을 순차적으로 실행하여 작업을 완료함
(2) 기존 LLMs의 한계점 : sub-goal이 많아질수록 완벽한 plan을 생성하는 확률이 줄어들고, 에이전트의 현재 상태를 고려한 plan이 비효율적일 가능성이 큼
- 그러나 위의 파이프라인은 1장에서 식별된 두 가지 문제를 모두 겪고 있음
- 첫 번째 문제(긴 일련의 sub-goal이 필요함)와 관련된 내용
- sub-goals의 수가 증가할수록 task description 설명에서 직접 완벽한 plan을 생성할 확률이 크게 감소함
- 두 번째 문제(생성한 plan의 실행가능성은 현재 상태에 의존적임)와 관련된 내용
- LLM이 올바른 plan을 생성하더라도, 에이전트의 현재 상태를 고려했을 때 그 plan이 매우 비효율적일 가능성이 큼
- 이전 연구들의 해결 시도 및 한계점
- affordance function, success detector 또는 scene descriptor를 통해 LLM에게 환경 피드백을 제공하여 첫 번째 문제를 해결하는 데 중점을 둠
- 그러나 이러한 접근법들은 많은 non-open-ended 도메인에서는 잘 작동하지만, 여전히 open 월드 환경에서는 높은 실패율을 겪고 있음
3. Towards Reliable Planning in Embodied Open-world Environments
(1) 3절 구성
- 섹션 3.1 : open-world에서 복잡하고 장기적인 과제를 해결하기 위해 제안된 interactive planning 프레임워크인 DEPS에 대한 개요를 제공
- 섹션 3.2 : DEPS가 첫 번째로 식별된 문제를 해결하기 위해 plan을 반복적으로 수정하는 방법을 자세하게 설명
- 섹션 3.3 : DEPS가 두 번째로 식별된 문제에 대응하여 효율적인 plan을 식별하는 데 사용되는 selector 모듈을 소개
3.1. DEPS Overview
(1) DEPS의 구성 : Descriptor, Explainer, Planner, Selector
- 우리의 에이전트 : DEPS는 다음과 같은 항목으로 구성됨 (그림 2 참고)
- event-triggered Descriptor (VLM)
- LLM 기반의 Explainer 및 Planner
- horizon 예측을 기반으로 한 goal Selector
- goal-conditioned controller
(2) LLM의 역할 : Zero-shot Planner → high-level task를 sub-goals의 시퀀스로 분해
- 우리는 에이전트의 task를 완료하기 위해, LLM을 zero-shot planner로 사용함
- 작업 $T$ (e.g., 다이아몬드 획득)로 주어진 goal-command를 받으면, LLM 기반 planner는 이 high-level task을 sub-goal {$g_1, \cdots, g_K$}의 시퀀스로 분해하여 초기 plan $P_0$를 생성함
- 이 sub-goals은 자연어로 구성된 지시사항임
- 마인크래프트 예시 : "참나무 목재 채광하기"
- ALFWorld 예시 : "컵 2개 찾기"
- Tabeltop manipulation 예시 : "블록 A를 블록 B 위에 놓기"
(3) 오류를 수정하는 방법 : LLM이 오류를 찾고 plan을 수정하여 다시 실행
- 섹션 2에서 설명한 바와 같이, 제어기는 goal-conditioned 정책 $\pi(a | s, g)$을 통해 제공된 sub-goal을 순차적으로 실행함
- 그러나 planner가 제공한 초기 plan에는 종종 오류가 포함되어 있어 제어기의 실행 실패로 이어짐
- 예를 들어, 그림 2의 Initial Plan $P_0$를 보면, 다이아몬드 제작이라는 목표를 달성하기 위해서는 나무 곡괭이만으로는 충분하지 않을 수 있음 (나무 곡괭이로는 은 광석을 채굴하지 못함)
- 실패가 발생하면 Descriptor가 현재 상태 $s_t$와 가장 최근 목표의 실행 결과를 텍스트 $d_t$로 요약하여 LLM(Explainer and Planner)에게 전송함
- LLM은 먼저 자체 설명(self-explanation)을 통해 이전 계획 $P_{t-1}$의 오류를 찾아내려고 시도함
- 예를 들어, 목표(e.g. 은 광석 채굴)를 달성하기 위해서는 돌 곡괭이를 사용해야 함.
- 그런 다음, 현재 작업 $T$을 다시 plan하고 설명에 따라 수정된 plan $P_t$를 생성함
- 이 과정에서 LLM은 Planner 역할 외에도 Explainer 역할을 수행함
- Descriptor, Explainer 그리고 Planner에 대한 자세한 내용은 섹션 3.2에서 다룰 것임
(4) DEPS 알고리즘 실행에 대한 간략 설명

- 방정식 (1)에서 보이는 바와 같이, DEPS는 task가 완료될 때까지 plan $P_t$를 반복적으로 업데이트함
- $f_DESC$ : descriptor model
- $f_LM$ : explainer 및 planner로서의 언어 모델
- $f_S$ : selector model
- $\pi$ : 제어기에서 생성된 goal-conditioned 정책
- 비효율적인 plan을 걸러내기 위해, selector는 현재 상태 $s_t$를 기준으로 parallel goals 집합 내의 모든 목표 $g_k$를 달성하기까지 남은 time steps의 수를 예측하도록 학습됨
- 생성된 plan에 대안 경로가 포함되어 있을 때, selector는 이 정보를 사용하여 현재 목표 $g_t$로 적합한 목표를 선택함
- 예를 들어 Savanna biome에서 selector가 예측한 목표 아카시아 나무의 horizon이 목표 참나무의 horizon보다 짧아서, 아카시아 나무를 현재 목표 $g_t$로 선택하게 됨
(저는 마인크래프를 많이 안해봐서 이 내용은 잘 모르겠네요..ㅋㅋ)
- 예를 들어 Savanna biome에서 selector가 예측한 목표 아카시아 나무의 horizon이 목표 참나무의 horizon보다 짧아서, 아카시아 나무를 현재 목표 $g_t$로 선택하게 됨
3.2. Describe, Explain and Plan with LLM Generates Executable Plans
(1) 현재 LLM 기반 planner의 한계점 : long horizon task에서 자주 실패하며, 단순히 sub-goal 완료 여부만을 알리는 피드백은 plan 오류를 수정한 데 충분하지 않음
- 현재 LLM 기반 planner는 보통 각 에피소드 시작 시 한 번 LLM을 쿼리하고, 에피소드 전체 동안 출력된 plan을 사용함
- 그러나 그림 1에서 보이는 것처럼, 이러한 one-shot plan 방법은 많은 sub-goal이 필요한 long-horizon task에서 자주 실패하며, 이는 두 가지 주요 문제로 인해 발생함
- 첫째, long-horizon task에 대한 올바른 plan은 다양한 복잡한 전제 조건을 충족해야 하므로, LLM이 task instruction(작업 지시)만으로 완벽한 plan을 직접 생성하는 것은 매우 어려움. 따라서 초기 plan을 단순히 실행할 경우에는 작업을 실패하게 됨.
- 둘째, 예측할 수 없는 transtion dynamics 때문에 실행 중에 발생하는 사건들이 초기 plan을 실행 불가능하게 만들 수 있음
- 이러한 문제를 해결하기 위해, 기존 방법들은 Success detector나 scene descriptor 등의 피드백을 도입하여 이전 실행의 결과를 반영함
- 그러나, LLM에게 sub-goal이 완료되었는지 여부만 알리는 것은 plan 오류를 수정하는 데 충분하지 않음
(2) 제안하는 방법론 : DEPS

- 우리는 더 실행 가능하고 설명 가능한 plan을 생성하기 위한 새로운 interactive planning 방법인 "describe, explain and plan"을 제안함
- 우리는 ChatGPT에서처럼 prompt를 interactive 대화 형식으로 다시 작성하여, 이후의 피드백이 LLM에 효과적으로 전달될 수 있도록 함
- 생성된 plan은 각 목표의 전제 조건과 결과를 함께 제공함
- 구조화된 prompt는 plan의 가독성과 해석가능성을 개선하고, 나중에 실행이 실패했을 때 오류를 찾아내는 것을 촉진함. (Prompt 1을 보면, 5가지 step으로 prompt가 구조화되어 있음.)
(3) Descriptor의 역할 : task 실행 중에 에이전트가 생성한 피드백을 수집하여, 게임 내 상징적 정보를 구조화된 언어로 번역하여 최종 이벤트 수준 설명으로 제공

- Descriptor는 task를 실행하는 동안 에이전트가 생성한 피드백을 수집함
- 피드백 유형 1 : 사람이 직접 피드백을 제공 (But, 피드백 데이터 수집 비용 높음)
- 피드백 유형 2 : 사전 학습된 vision-language model CLIP으로 부터 얻을 수 있음 (But, 특정 도메인에 맞게 fine-tuning해야 하므로, 에이전트의 자동화 및 일반화 능력이 감소)
- 이에 반면, 마인크래프트는 'info' 및 다른 high-level observation(e.g., biome, GPS, 나침반)을 반환하기 때문에, 비구조화된 정보를 구조화된 언어로 쉽게 번역할 수 있음
- 따라서 우리는 게임에서 사용할 수 있는 상징적 정보를 가져와, 이 task의 피드백 설명 $d_t$로 번역함
- Prompt에 관련 없는 정보를 포함시키지 않기 위해, 우리는 plan 관련 메시지(e.g., 인벤토리 정보, biome)를 최종 이벤트 수준 description $d_t$로 증류함 (아래 그림의 초록색 Description $d_t$ 참고)

(4) Explainer 및 Planner의 역할 : LLM을 explainer로 사용하여 이전 plan의 실패 이유를 분석하고, 이를 통해 업데이트된 plan을 생성
- 특히, 우리는 LLM을 explainer로 사용하여, 이전 plan $P_{t-1}$이 실패한 이유를 설명함
- 구체적으로, explainer는 현재 상태 설명 $d_t$와 현재 목표 $g_t$의 전제 조건을 분석하여 현재 목표가 성공적으로 실행되지 못한 이유를 식별할 수 있음
- 위 그림 2의 일부에서 '좌측 하단의 Explanation'에서 보이듯이, 그 이유는 현재 목표가 철 곡괭이의 사유를 요구하지만, 도구가 미리 준비되지 않은 상황일 수 있음
- 이를 구현하기 위해, 우리는 LLM에 chain-of-thoughts prompting와 같이 몇 가지 예시를 제공함 (Prompt 1 참고)
- Chain-of-thoughts prompting은 복잡한 문제를 단계별로 해결하기 위해 대형 언어 모델(LLM)에 연쇄적인 사고 과정을 유도하는 방법임. 이 접근 방식은 LLM이 문제 해결 과정을 논리적으로 단계별로 진행하도록 프롬프트를 구성함.
# Prompt 예시
Q: 두 사람이 사과를 나눠 가질 때, 각자가 받을 사과의 수는?
A:
1. 두 사람이 나눌 사과의 총 수를 파악합니다.
2. 각 사람이 받을 사과의 수를 계산합니다.
3. 따라서 각자가 받을 사과의 수는 총 사과의 수를 둘로 나눈 것입니다.
- 마지막으로, LLM은 planner 역할로 돌아가 이전 계획 $P_{t-1}$의 기존 버그에 대한 명확한 설명을 통해 작업을 replan하고, 설명에 따라 업데이트된 계획 $P_t$를 생성함
3.3. Horizon-Predictive Selector Yields Efficient Plans
(1) Selector의 필요성 : task를 완료하는 여러 경로가 존재하더라도, 현재 에피소드에서 가장 효율적인 경로를 선택해야 함
- Open-world에서는 사물의 풍부함과 그 기능의 조합적 특성 때문에, task를 완료하기 위한 여러 가지 가능한 plan이 종종 존재함. 즉 특정 목표를 완료하는 데 여러 경로가 존재하는 경우가 많음
- 그러나, 이러한 모든 plan이 실행 가능하더라도, 대부분은 현재 에피소드에서 실행하기에 매우 비효율적임
- 예를 들어, 아래 그림 2에서 보이는 것처럼, 나무를 얻기 위해 참나무, 자작나무, 아카시아 나무를 자를 수 있음
- 그러나 평원 biome에서는 참나무만 사용할 수 있음.
- 따라서 에이전트가 다른 biome으로 이동할 필요가 없기 때문에 planner는 참나무를 선택해야 함

(2) Selector의 영감 : 가까운 목표를 먼저 선택하면, plan의 효율성이 증가하고 성공률이 높아질 수 있음
- 다른 한편으로, plan $P_t$ 내의 일부 목표에는 엄격한 순차적 요구가 없음
- 즉, $g_i$와 $g_j$가 동일한 전제 조건을 가지며, 이는 $g_i$와 $g_j$가 어떤 순서로든 실행될 수 있음을 의미함
- 다양한 plan(순서)의 선택은 plan $P_t$의 실행 효율성에 영향을 미칠 수 있음
- 항상 더 가까운 목표를 선택하면 더 효율적인 plan을 세울 수 있으며, 제한된 에피소드 길이 내에서 최종 성공률을 높일 수 있음
- 또한 open-world 환경의 역동성은 효율적인 plan이 성공률에 미치는 영향을 더욱 증대시킴
- 예를 들어, 마인크래프트에서 에이전트가 나무를 먼저 수집하는 먼 목표를 선택하면, 더 가까운 목표인 양이 사라져 다시 찾기 어려워질 수 있음
(3) Selector을 기존 LLM으로 구현하면 발생하는 문제점 : VLM은 실질적인 경험이 부족하기 때문에 목표를 완료하는 난이도를 정확하게 반영하지 못할 수 있음
- 우리의 plan 효율성을 향상시키기 위해, 우리는 최종 plan으로 가장 높은 실행 성공률을 가진 가장 효율적인 경로를 선택하는 selector를 사용할 것을 제안함
- 구체적으로, 우리는 상태 $s_t$에서 가장 가까운 목표를 현재 목표 $g_t$로 선택하는 상태 인식 selector를 설계함
- 이 selector는 현재 상태 $s_t$와 plan $P_t$ 아래에서 목표 분포 $P(g_t | s_t, P_t)$를 예측함
- 여기에서 $g_t \in G_t$이고, $G_t$는 $P_t$에서 현재 실행 가능한 모든 목표를 설명함
- selector를 구현하는 가장 간단한 방법은 CLIP와 같은 비전-언어 모델(VLM)을 사용하여, 현재 상태와 목표 텍스트 간의 의미적 유사성을 활용하는 것임
- 그러나, VLM은 실질적인 경험이 부족하기 때문에 목표를 완료하는 난이도를 정확히 반영하지 못할 수 있음
- 예를 들어, 에이전트 앞에 있는 "참나무"는 "나무 베기" 목표에 높은 의미적 유사성을 가질 수 있지만, 에이전트와 참나무 사이에 협곡이 있다면, 이 목표를 달성하는 것은 비효율적일 수 있음
(4) 제안하는 selector : 효율성과 실행 가능성에 따라 목표를 정확히 순위를 매기는 horizon-predictive selector를 구현하여 실제 작업 경험을 반영하기
- 위와 같은 문제를 완화하기 위해, 우리는 효율성과 실행 가능성에 기반하여 목표를 정확하게 순위를 매기는 실제 작업 경험을 포함한 horizon-predictive selector를 구현함
- 여기서 우리는 목표의 horizon를 주어진 목표를 완료하기까지 남은 time step으로 정의함
- $h_t(g):= T_g - t$
- 여기서 $T_g$는 목표 g를 완료하는 시간을 의미함
- $h_t(g)$는 현재 상태에서 주어진 목표를 얼마나 빨리 달성할 수 있는지를 정확하게 반영함
- horizon을 추정하기 위해, 우리는 목표 g를 완료하는 경로에서 ground-truth horizon $h_t$가 있을 때, 엔트로피 loss을 최소화함으로써, offline trajectories에 맞추기 위한 신경망 $\mu$를 학습함
- entropy loss = $-log\mu(h_t(g) | s_t, g)$
- 따라서 목표 분포는 다음과 같이 공식화될 수 있음

- 우리는 selector의 backbone으로써 goal-sensitive Impala CNN을 선택함
- Impala CNN은 목표와 관련된 정보(e.g. 텍스트)를 입력으로 받아들이며, 목표를 달성하기 위해 입력 이미지에서 목표와 관련된 특징을 추출하고 활용함.
- 실제로 horizon predictive selector는 제어 정책과 함께 공동으로 학습할 수 있으며, 기본 파라미터를 공유할 수 있음

4. Experiments
(1) 4절 구성
- 이 섹션에서는 제안된 DEPS 방법을 분석하고 평가함.
- low-level 제어기에 의해 발생하는 성능 변화를 최소화하기 위해, 우리는 Behavior Cloning을 통해 학습된 하나의 제어기로 모든 실험을 표준화함. 이 제어기의 세부 사항은 부록 C를 참고.
- 섹션 4.1 : 테스트 환경과 가장 어려운 71개의 작업으로 구성된 테스트 작업 세트를 소개
- 섹션 4.2 : 기존의 LLM 기반 플래너와의 성능 비교
- 섹션 4.3 : Ablation studies
- 섹션 4.4 : 가장 어려운 작업인 ObtainDiamond에 대한 성능 측정
- 부록 A : ALFWorld 및 Tabletop Manipulation 환경에서의 실험 결과
4.1. Experimental Setup
1) Environment and Task Setting
(1) 평가 환경 : 다양한 버전의 마인크래프트 환경
- 우리는 먼저 마인크래프트에서 제안한 방법을 평가함. 마인크래프트는 섹션 1에서 논의된 두 가지 도전 과제를 포함한 인기 있는 오픈월드 환경임.
- DEPS의 성능을 더 잘 반영하기 위해, 우리는 다양한 버전의 세 가지 마인크래프트 환경을 선택하여 평가함
- Minecraft 1.11.2 버전의 Minedojo
- Minecraft 1.16.5 버전의 MineRL
- Minecraft 1.19.2 버전의 MC-TextWorld
- 위 세가지 마인크래프트 환경에서는 규칙과 아이템이 다소 다르므로, DEPS의 동적이고 상호작용적인 plan 능력을 더 잘 평가할 수 있음
(2) 작업 설정 : 71개의 마인크래프트 과제를 재료와 기능에 따라 8개의 메타 그룹으로 나눔
- 우리는 Minecraft Universe Benchmark SkillFOrgeChain에서 71개의 과제를 선택하여 DEPS를 평가함
- 이 과제들은 마인크래프트 overworld에서 얻을 수 있는 아이템과 관련이 있음
- 결과를 더 잘 제시하기 위해, 우리는 71개의 마인크래프트 과제를 재료와 기능에 따라 8개의 메타 그룹(MT1-MT8)로 나눔
- 각 과제에 대한 instruction(지시)는 자연어로 작성됨 (Table 1 참고)
- 예를 들어, MT1(기본 그룹)에서는 나무 문 만들기
- MT8(도전 그룹)에서는 다이아몬드 얻기

- 우리는 다양한 메타 과제에 대해 최대 에피소드 단계를 3000(가장 쉬운 기본 과제)에서 12000(가장 어려운 도전 과제)까지 설정함
- 모든 과제의 이름, 필요한 기술 수, 기능은 부록 B에 나와있음

- 우리는 서바이벌 모드에서 각 과제에 빈 인벤토리를 제공하고 에이전트가 환경에서 직접 모든 아이템을 획득하도록 요구함
- 각평가마다 에이전트는 무작위로 다른 환경에 소환됨
- 생물군계와 초기 위치도 매번 다름
- 이전 연구를 따라, 우리는 성공률을 평가 지표로 사용
2) Baselines
- 베이스라인 유형 (Language-based planners)
- GPT as Zero-shot Planner
- ProgPrompt(PP)
- Chain-of-Thought (CoT)
- InnerMonologue(IM)
- Code as Policies (CaP)
- 모든 베이스라인 모델에 대해 동일한 Prompt에서 demonstration 예제를 사용하고, OpenAI의 동일한 LM 모델과 모든 작업에서 동일한 제어기를 사용하여 공정한 비교를 함
- 이 방법들은 원래 마인크래프트에서 실험되지 않았기 때문에, 우리는 prompt와 피드백 템플릿 디자인을 기반으로 마인크래프트 사양에 맞게 재현함
- 모든 planner 방법은 OpenAI API를 통해 LLM 모델에 접근함
- LLM의 모든 하이퍼파라미터는 기본값으로 유지됨
- 또한 모든 다른 방법들의 전체 prompt는 부록 G에 나와 있음
4.2. Main Results

- 모든 과제는 30번 (반복?) 실행되며 Minedojo의 각 메타 과제에 대한 평균 결과는 table 2에 나와 있음
- 우리의 접근 방식 : DEPS는 모든 메타 과제에서 최고 성능을 달성함
- 과제의 복잡도가 MT1에서 MT8로 증가함에 따라, planner는 최종 과제를 달성하기 위해 더 정확한 task steps을 제공해야 함. 따라서 모든 에이전트의 성공률은 추론 단계가 증가함에 따라 감소함
- MT6부터 시작하여 거의 모든 기존 LLM 기반 planner가 실패함 (성공률이 거의 0%)
- DEP(selector 제외)는 이미 모든 메타 과제에서 기존 LLM 기반 플래너를 일관되게 큰 차이로 능가함.
- 이는 "describe, explain and plan"이 현재 plan 실패의 이유를 추정하고 원래의 결함 있는 plan을 수정할 수 있음을 입증함
- 제한된 최대 에피소드 길이와 어려운 목표(e.g. 철 곡괭이로 다이아몬드 채굴)에 대한 제한된 제어 성공률로 인해 최종 성공률은 여전히 제한됨.
- 추가적으로, Selector는 에이전트의 최종 과제 성공률을 크게 향상시킴.
- 어려운 메타 과제는 보통 여러 sub-goals(수십 개의 목표까지)의 완료를 요구하므로, 더 많은 유연성을 제공하고 Selector를 위한 더 많은 후보 목표를 제공함.
- 동시에, 에이전트가 제한된 에이포스 길이로 실험을 수행할 때, plan의 효율성에 대한 높은 요구도 부과됨.
- 따라서 Selector는 MT7과 같은 효율성에 민감한 과제에서 상당한 효율성 향상을 가져옴 (최대 2.7배 성공률 향상)
[Robustness on different controller and different Minecraft versions]

- 우리는 또한 MineRL과 MC-Textworld에서 DEPS를 평가함
- DEPS는 plan 방법으로, 마인크래프트 환경과 상호작용하기 위해서 goal-conditioned 제어기를 갖춰야 함
- 우리는 MC-COntroller와 Steve-1를 각각 Minedojo와 MineRL에서 상호작용하기 위한 제어기로 선택함
- 이 두 방법은 모두 시각적 부분 관찰을 인식하고 마우스 및 키보드 동작을 생성하는 제어 정책임
- 반면, MC-Textworld는 텍스트 세계로, 마인크래프트 제작 레시피와 채굴 규칙만을 유지함. 따라서 MC-Textworld는 제어기를 필요로 하지 않음
- 다양한 마인크래프트 환경에서 MT1-MT8 과제 세트에 대한 DEPS 결과는 table 3에 나와 있음
- 결과는 DEPS가 다양한 마인크래프트 환경에서 효과적인 plan을 생성할 수 있음을 보여줌.
- MC-Textworld의 결과는, 특히 MT6-8까지의 더 어려운 과제 세트에서 MineDojo와 MineRL의 성능이 저하된 주된 이유가 제어기의 한계임을 보여줌
4.3. Ablation Study
(1) 개요
- 우리는 다음의 변수가 어떠한 영향을 미치는지 조사하기 위해 ablation 실험을 진행함
- 다양한 Selector 모델에 대한 실행 가능한 후보 목표의 수
- DEPS의 round 수가 미치는 특정 영향
4.3.1. Ablation on Selector
(1) 실험 목표
- 제안된 selector의 다양한 병렬 목표(Parallel Goals) 하에서의 robustness을 검증하는 것이 목표
- 에이전트는 각각 2,3 그리고 4개의 후보 목표(모든 목표에 대해 전제 조건이 일관됨)를 완료하도록 요청 받음
- Task의 목표는 다양한 종류의 mob이나 재료에 해당함
(2) 실험 결과
- 우리는 다음의 항목을 포함하여, 서로 다른 selector implementations을 사용하여 우리의 방법(DEP)의 최종 성공률을 기록함
- 고정된 목표 순서
- 랜덤한 목표 순서
- (MineCLIP, CLIP, Our horizon-predictive Selector(HPS))을 기반으로 goal을 선택하는 것

- 그림 4에서 보이는 것 처럼, 병렬 후보 목표의 한 라운드에서 고정된 plan(즉 selector 없이)과 비교하여 horizon-predictive selector(HPS)를 사용했을 때, 각각 22.3%, 29.2%, 32.6%의 향상이 있었음
- 제한된 에피소드 길이(e.g. 1000 steps)에서 HPS 모델은 더 큰 이점을 보여주며, 이는 HPS 모델이 embodied 환경에서 plan의 실행 효율성을 향상시킬 수 있음을 증명함
- 또한 CLIP 및 MineCLIP과 같은 VLM을 목표 모델로 사용하는 것과 비교했을 때, HPS 모델이 horizon 정보를 더 잘 추정하여 최고의 성능을 보임
- 성공률 곡선 추세는 Selector를 사용한 에이전트가 오픈월드 환경에서 많은 목표 하에서 확장된다는 것을 보여줌
4.3.2. Ablation on Re-Planning Rounds
- 우리는 증가하는 최대 DEPS의 rounds로 모든 task에서 에이전트를 평가함
- Round의 정의 : description, explanation, planning and selecting을 포함하는 상호작용 LLM 기반 planning의 사이클, 즉 업데이트된 plan으로 정의됨
- 모든 최대 round의 각 task는 30번 실행되며, 평균 성공률은 Table 4에 기록됨

- 우리는 dexcription, re-planning, 혹은 self-explanation 과정을 포함하지 않고, 초기 생성된 plan을 최종 실행 plan으로 사용하는 기본 LLM planner(=round 0)를 기준으로 삼음
- 이전 하위 섹션의 결과는 OpenAI에서 설정한 최대 토큰에 의해 제한된 최대 round를 사용함.
- 우리는 또한 표 4의 열 △에서 기본 플래너에서 DEPS로의 성공률 증가를 보고함.
- 이 실험은 DEPS가 오픈월드 환경에서 plan을 반복적으로 개선할 수 있음을 보여줌
- 더 많은 description, self-explanation, 그리고 re-planning round는 특히 어려운 작업에서 더 나은 결과를 생성함
(음? 제일 어려운 작업인 MT8에서 0.6% 밖에 상승 없는데?)
4.4. ObtainDiamond Challenge
- 오픈월드 게임 마인크래프트에서 다이아몬드를 채굴하는 것, 즉 표 2의 MT8은 커뮤니티에게 오랫동안 도전 과제로 남아있었음
- 이는 마인크래프트에서 다이아몬드를 처음부터 채굴하는 것이 다음과 같이 목표에 대한 복잡한 plan을 요구하기 때문에 어려움
- 광업, 인벤토리 관리, 제작 테이블 유무에 따른 제작, 도구 사용, 용광로에서 철괴 녹이기, 최저 깊이에서의 채굴 등등..
- 우리는 복잡한 과제에서 zero-shot planner의 능력을 보여주기 위해 ObtainDiamond 과제를 보너스 실험으로 선택함
- 이 도전에 대한 이전 방법들의 성공률은 그 어려움을 입증함
- [Skrynnik et al., 2021, Patil et al., 2020]은 도메인 특정 보상 함수와 RL fine-tuning을 활용하여 15분의 게임 플레이에서 약 0.1%의 성공률을 달성함
- VPT는 pre-training을 통해 70,000시간의 인간 시연을 수집하고 인간이 설계한 보상 함수로 미세 조정하여 20분의 플레이 내에서 성공률을 20%로 끌어올림[Baker et al., 2022].
- DreamerV3는 수정된 마인크래프트 환경(블록을 깨기 더 쉽게)에서 월드 모델을 사용하여 처음부터 학습하여 성공률 2%를 달성함 [Hafner et al., 2023].
- 이 대단한 도전 과제에서 우리의 DEPS는 동등한 성능을 달성함
- 우리의 에이전트는 10분의 게임 플레이 내에서 0.59%의 성공률을 달성함
- 주목할 점은 우리의 방법이 이 도전 과제에 맞춰 특별히 fine-tuning한 것이 아니라는 것임
- 이는 본질적으로 multi-task를 수행하도록 설계됨
- 또한 우리의 planner는 고정된 LLM에서 demonstration prompt로 작동하므로 다른 open-ended 환경에도 쉽게 적용할 수 있음
5. Related Works
1) Task Planning with LLMs
- 핵심 : LLMs을 활용하여 embodied 환경에서 high-level task을 위한 action plans을 생성
- [Huang et al., 2022b]
- 자연어 명령을 텍스트 완성과 의미(semantic) 번역을 통해 실행 가능한 행동 시퀀스로 분해하고, SayCan은 가치 함수로부터의 skill affordances로 가중된 LLM을 공동 디코딩하여 로봇을 위한 실행 가능한 plan을 생성
- [Brohan et al., 2022]
- Embodied 환경에서 plan을 더 잘 실행하기 위해, 일부 방법들은 초기 환경을 language prompt로 설명하는 object detector를 사용하여 환경에 적합한 plan을 생성하고 각 단계가 성공적으로 실행되었는지 확인하는 success detector를 채택함
- [Singh et al., 2022] & [Liang et al., 2022]
- 파이썬 스타일 prompt를 사용하여 더 실행 가능한 plan을 생성
- 한계점 : 그러나 위의 모든 방법은 LLM의 초기 plan이 올바르다고 가정함. 초기 plan에 버그가 있을 경우, 에이전트가 작업을 성공적으로 완료하기 어려움.
2) Interactive Planning with LLMs
- Inner Monologue [Huang et al., 2022a]
- LLM과의 상호작용 plan의 선두주자로서 success detection과 scene description을 planner에 도입하여 피드백을 제공함
- 한계점 : 그러나 우리는 그것이 여전히 누적 plan 오류를 겪을 수 있으며, 특히 장기적인 오픈월드 과제에서 그러할 수 있다는 것을 발견함.
- Ours (DEPS)
- 반면, 우리의 DEPS 방법은 chain-of-thought thinking and explanation을 활용하여 이전 plan의 오류를 찾아내어 더 신뢰할 수 있는 plan을 생성할 수 있음.
- 또한 우리는 plan의 효율성을 더욱 향상시키기 위해 goal selector를 제안하여 훨씬 더 나은 성능을 발휘함 (섹션 4.2 참고)
3) Agents in Minecraft
- 핵심 : low-level 컨트롤러의 개선에 중점
- [Oh et al., 2017, Mao et al., 2022, Lin et al., 2021]
- hierarchical architecture를 사용하여 마인크래프트에서 장기 과제를 해결함
- [Fan et al., 2022]
- 최근에는 인터넷 규모의 corpus를 기반으로 language-conditioned reward function를 pre-training하고 multi-task MineAgent를 학습함
- [Baker et al., 2022]
- Behavior Cloning 에이전트를 학습시키기 위해 방대한 양의 human demonstrations을 수집함
- [Hafner et al., 2023]
- 학습된 월드 모델을 사용하여 마인크래프트에서 효율적으로 탐색할 수 있는 정책을 도출
- [Cai et al., 2023a,b, Lifshitz et al., 2023]
- 더 나은 instruction following을 위해 목표 조건 정책을 학습하는 것에 중점을 둠
- Ours (DEPS)
- 우리의 아키텍처에서 planner는 도메인 지식을 적용하여 sub-goals을 제안하고 배열하는 것을 강조
- 이는 에이전트가 처리할 수 있는 작업의 복잡성과 범위에 크게 영향을 미침
- 게다가 우리의 플래너는 zero-shot으로, 다른 환경으로 일반화하는 것이 가능함
6. Limitations
(1) 첫번째 한계점 : LLM의 의존성
- 우리의 프레임워크는 GPT-3와 ChatGPT와 같은 사유 LLM에 의존하기 때문에, 이 서비스를 감당할 수 없거나 접근할 수 없는 사람들에게는 접근성이 낮음
- 그러나 우리는 더 민주화(?)된 방법을 보장하기 위해 전적으로 헌신하고 있으며, OPT와 BLOOM을 포함한 오픈 소스 모델을 사용하는 것을 탐구할 것임
(2) 두번째 한계점 : 시스템의 명시적 단계별 Plan에 따른 모델의 확장 제한성
- DPES는 베이스라인 모델보다 우수한 성능을 가져다주지만, plan 병목 현상으로 인해 모델의 확장이 제한될 수 있음
- 더 매력적인 접근 방식은 목표 조건 정책 내에서 plan을 점진적으로 통합하는 end-to-end 학습 가능 방법을 사용하는 것이며, 이는 다음에 탐구할 가치가 있음
- 게다가, plan에서 발생하는 몇 가지 근본적인 문제들(예: 막다른 길)은 우리가 채택한 환경에서는 일반적이지 않을 수 있으며, 따라서 우리의 논문에서 무심코 간과될 수 있음.
- 우리는 다음 연구 시리즈에서 multi-task generalist agent를 구축하는 데 있어 더 근본적인 문제를 해결하는 데 전념하고 있음
7. Conclusion
- 우리는 오픈월드에서의 planning 문제를 조사했으며, 이러한 환경에서 두 가지 주요 문제를 식별했음
- 1) Long-term planning은 정확하고 다단계의 추론을 요구함
- 2) 정형화된 planner는 에이전트가 병렬 목표/하위 작업에 얼마나 가까운지를 고려하지 않기 때문에 planning 효율성이 저하될 수 있음.
- 우리는 이 두 가지 문제를 해결하기 위해 LLMs을 기반으로 한 상호작용 접근 방식인 DEPS을 제안함
- 도전적인 마인크래프트 도메인에서의 실험은 우리의 접근 방식이 다른 방법들에 비해 70개 이상의 마인크래프트 과제를 robust하게 수행하고 전반적인 성능을 거의 두 배로 향상시키는 이정표를 세우면서 그 장점을 입증함
- 또한 DEPS는 이 게임에서 다이아몬드에 도달할 수 있는 최초의 planning-based 에이전트임
Appendix
A. Additional Experiments
A.1. ALFWorld
- ALFWorld는 text와 embodiment를 결합한 상호작용 학습 환경으로, 에이전트가 TextWorld에서 추상적이고 텍스트 기반의 정책을 습득한 후, 시각적으로 풍부한 환경에서 ALFRED 벤치마크의 목표를 실행할 수 있도록 함
A.1.1. Tasks

A.1.2. Results


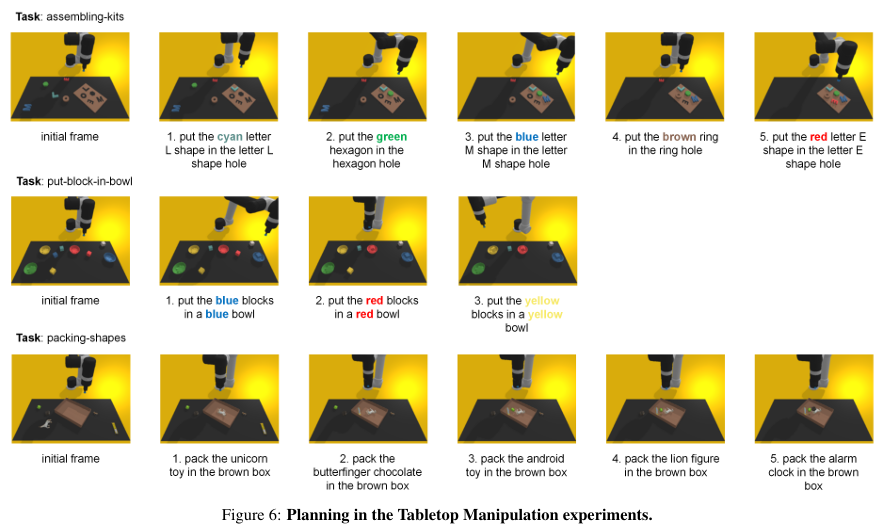
A.2. Tabletop Manipulation
- 시뮬레이션 환경에서 로봇은 UR5e와 suction 그리퍼를 사용
A.2.1. Tasks

A.2.2. Results