
 강화학습 논문 정리 15편 : Accelerating Interactive Human-like Manipulation Learning with GPU-based Simulation and High-quality Demonstrations (IEEE-RAS 2022)
강화학습 논문 정리 15편 : Accelerating Interactive Human-like Manipulation Learning with GPU-based Simulation and High-quality Demonstrations (IEEE-RAS 2022)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) Keywords : Dexterous manipulation, Learning from human demonstrations, Reinforcement Learning 논문 링크 : https://ieeexplore.ieee.org/document/10000161 Accelerating Interactive Human-like Manipulation Learning with GPU-based Simulation and High-quality Demonstrations Dexterous manipulation with anthropomorphic robot hands remains a challenging problem in robot..
 강화학습 논문 정리 14편 : DexMV : Imitation Learning for Dexterous Manipulation from Human Videos (ECCV 2022)
강화학습 논문 정리 14편 : DexMV : Imitation Learning for Dexterous Manipulation from Human Videos (ECCV 2022)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) Keywords : Dexterous manipulation, Learning from human demonstrations, Reinforcement Learning 논문 링크 : https://link.springer.com/chapter/10.1007/978-3-031-19842-7_33 홈페이지 링크 : https://yzqin.github.io/dexmv/ DexMV: Imitation Learning for Dexterous Manipulation from Human Videos yzqin.github.io 영상 링크 : https://www.youtube.com/watch?v=scN4-KPhJe8 깃헙 링크 : https..
 강화학습 논문 정리 13편 : Skill Preferences : Learning to Extract and Execute Robot Skills from Human Feedback 논문 리뷰 (CoRL 2021)
강화학습 논문 정리 13편 : Skill Preferences : Learning to Extract and Execute Robot Skills from Human Feedback 논문 리뷰 (CoRL 2021)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) Keywords : Reinforcement Learning, Skill Extraction, Human Preferences 논문 링크 : https://proceedings.mlr.press/v164/wang22g.html Skill Preferences: Learning to Extract and Execute Robotic Skills from Human Feedback A promising approach to solving challenging long-horizon tasks has been to extract behavior priors (skills) by fitting generative models to large..
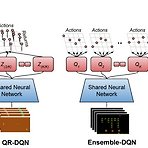 강화학습 논문 정리 12편 : An Optimistic Perspective on Offline Reinforcement Learning 논문 리뷰 (ICML 2020)
강화학습 논문 정리 12편 : An Optimistic Perspective on Offline Reinforcement Learning 논문 리뷰 (ICML 2020)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) 논문 링크 : https://proceedings.mlr.press/v119/agarwal20c.html An Optimistic Perspective on Offline Reinforcement Learning Off-policy reinforcement learning (RL) using a fixed offline dataset of logged interactions is an important consideration in real world applications. This paper studies offline RL using the DQN rep... proceedings.mlr.press 홈페이지 링크 : https:..
 강화학습 논문 정리 11편 : Eureka: Human-Level Reward Design via Coding Large Language Models 논문 리뷰 (arXiv 2023)
강화학습 논문 정리 11편 : Eureka: Human-Level Reward Design via Coding Large Language Models 논문 리뷰 (arXiv 2023)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) 논문 링크 : https://arxiv.org/abs/2310.12931 Eureka: Human-Level Reward Design via Coding Large Language Models Large Language Models (LLMs) have excelled as high-level semantic planners for sequential decision-making tasks. However, harnessing them to learn complex low-level manipulation tasks, such as dexterous pen spinning, remains an open problem. We bridg..
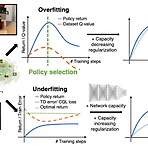 강화학습 논문 정리 10편 : A workflow for Offline Model-Free Robotic Reinforcement Learning 논문 리뷰 (CoRL 2022)
강화학습 논문 정리 10편 : A workflow for Offline Model-Free Robotic Reinforcement Learning 논문 리뷰 (CoRL 2022)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) 논문 링크 : https://proceedings.mlr.press/v164/kumar22a.html A Workflow for Offline Model-Free Robotic Reinforcement Learning Offline reinforcement learning (RL) enables learning control policies by utilizing only prior experience, without any online interaction. This can allow robots to acquire generalizable skills from ... proceedings.mlr.press 홈페이지 링크 : Off..
 강화학습 논문 정리 9편 : DR3 : Value-Based Deep Reinforcement Learning Requires Explicit Regularization 논문 리뷰 (ICLR 2022)
강화학습 논문 정리 9편 : DR3 : Value-Based Deep Reinforcement Learning Requires Explicit Regularization 논문 리뷰 (ICLR 2022)
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) 안녕하세요!! 정말 오랜만의 블로그 포스팅입니다 ㅎㅎ 요새는 Offline Reinforcement Learning 분야를 연구하고 있습니다! 그런데 요녀석이 학습이 생각보다 잘 안돼더라고요 ㅜㅜ 저와 비슷한 고민을 하는 분들을 위해 오프라인 강화학습을 위한 팁! 논문을 가져왔습니다 ㅎㅎ 재밌게 읽어봐주세요~! 논문 링크 : https://openreview.net/forum?id=POvMvLi91f DR3: Value-Based Deep Reinforcement Learning Requires Explicit... Despite overparameterization, deep networks trained via supervised..
 강화학습 논문 정리 8편 : Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics : a Survey 논문 리뷰
강화학습 논문 정리 8편 : Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics : a Survey 논문 리뷰
작성자 : 한양대학원 인공지능융합학과 유승환 박사과정 (CAI LAB) 드디어... 블로그에 논문 리뷰 글을 포스팅할 수 있게 되었습니다 ㅎㅎ 방학 때는 열심히 논문 리뷰와 연구 프로젝트 3개의 진행을, 학기 중에는 수업 4개와 5개의 연구 프로젝트를 진행하다보니 1개의 몸둥아리 밖에 없는게 너무 서글픕니다 ㅋㅋ 그래도 열심히해서 살아남겠습니다 ㅎㅎ 오늘부터 차근차근 겨울방학 때 강화학습 논문을 리뷰했던 내용을 올리고자 합니다~! 이번 포스팅은 강화학습 분야의 Sim-to-Real Transfer에 대한 서베이 논문을 리뷰하고자 합니다! 글로도 보완 설명을 하고 싶었으나, 시간이 부족한 관계로... 저를 포함한 대학원생 및 학부연구생 친구들이 논문 리뷰를 진행했던 피피티 원본을 공유하고자 합니다 ㅎㅎ 궁..