
티스토리 뷰
반년전에 공부하면서 노션에 정리한 강화학습 내용을 다시 복습할 겸 올리는 중입니다.
팡요랩 유튜브 영상을 보며 정리한 내용이며, 분명히 틀린 내용이 많으니 만약 보시는 분들은 참고용으로만 보시면 좋을 것 같습니다. 강화학습이지만 귀찮으니깐 제어 카테고리에 넣겠습니다.
팡요랩 유튜브 영상 : https://www.youtube.com/watch?v=NMesGSXr8H4
강의 자료 (David silver) : https://www.davidsilver.uk/wp-content/uploads/2020/03/MDP.pdf
Dynamic programming
Dynamic programming은 어려운 문제를 작은 단위로 나눠서 푸는 방법이다. 작은 단위 문제(subproblem)을 풀고 솔루션과 subproblem을 묶어서 결과를 도출한다. DP는 몇가지 특징을 가지는 문제들에 자주 사용되는데,
1. Optimal substructure
- Principle of optimality가 적용된다.
- 최적의 솔루션이 subproblem안에 나눠 들어가 있다.
2. Overlapping subproblem
- subproblem이 여러번 반복 된다.
- 해는 캐시처럼 저장되고 다시 사용가능하다.
3. Markov decision processes satifty both properties
- 벨만식이 재귀적으로 나눠져야한다.
- Value 함수가 해를 저장하고 재 사용할 수 있다.
DP의 꼉우 주어진 환경의 모델을 MDP(Markov Decision Process)로서 모두 알고 있어야한다.
따라서 단순히 DP의 경우 planning이라 하며, 강화학습의 경우 learning이라고 하기도 한다.
MDP안에서 경로를 탐색할 때는 Perdiction과 control 부분으로 나눠지게 된다.

쉽게 생각해서, 제일 먼저 MDP, policy에 따라 value function을 구하는 것이 prediction, 그리고 이용한 policy를 어떻게 optimal 하게 발전시키는 부분이 control이다. DP는 벨만식에 따라서 policy iteration과 value iteration에 으로 나뉜다.
Policy iteration :: Iterative Policy Evaluation
Policy에 대한 평가를 해야 하는 문제이다. 평가한다는 것은 policy를 따라 행동했을 때 return을 얼마나 받는지에 대한 평가이다. 이는 Bellman expectation 백업을 반복하여 적용하는 것으로 할 수 있다. 초기 value 값인 v를 가 v1,v2,v3,,,,v_pi까지 확인하면 된다. backup에는 synchronous와 asynchronous가 있는데 여기서는 synchronous를 사용한다.
모든 state들의 value 값을 각각 다음 state값을 사용하여 업데이트 해준다. 이 부분이 조금 헷갈릴 수 있으니 더 정리해보자. policy evaluation은 iteration 을 통해서 이루어지고 이는 주로 k로 표기한다. state s에서 s'으로 이동할 수 있다고 했을 때, k+1번째의 state s의 value function을 구하는 경우에 k번째의 state s', 즉 s에서 이동하여 갈 수 있는 다음 state인 s'의 value function을 이용해서 현재 state의 value function을 구한다는 뜻이다. state의 이동보다는 iteration에 대한 값들의 이용에 초점을 맞춰야 이해가 편하다.
모든 state를 업데이트 해줬다면 다음 iteration 으로 넘어간다. 한번에 전부 업데이트 해주는 것을 synchronous라고 한다. 이를 n번 해주게 되면 v_pi로 수렴하게 된다. 즉, 반복을 통해서 policy에 대한 true value function을 구하는 과정을 policy evaluation이다.

그림에서 V_k+1(s)의 값을 정확하게 하고 싶다고 해보자. 그러면 s에서 갈 수 있는 state들은 총 4개가 있으니 이를 이용해서 V_k+1(s)값을 정확하게 구할 수 있다. 식을 보게 되면 Reward와 discount 된 state transition matrix * value function (Bellman equation)으로 이뤄진걸 볼 수 있다.
Improving a policy
주어진 policy에 대해서 먼저 Evaluate을 하고 Improve하는 방법이다. 쉽게말해서 policy를 통해서 true value function을 찾았는데 이 policy가 최적의 policy인지, 아니면 Improve할 여지가 있는지에 대한 확인을 하는 단계이다. 있다면 update를 하게 되고 이를 통해 optimal policy를 구할 수 있게 된다.
이때 Evaluate는 앞서 말한 벨만식을 사용하여 진행하고 식은 아래와 같다.

Improve의 경우 value function을 기준으로 greedy 하게 움직인다. (Improve 방법은 여러가지가 있다) greedy하게 움직인다는 말은 value가 높은 state로 이동하는 action을 취한다는 말이다. greedy한 action을 선택하는 기준을 만드는 것이 action-value fucntion인 q function이 된다.

여끼써 policy'의 경우 계속 반복할 경우 policy* (optimal policy)로 수렴하게 된다.

그렇다면 과연 greedy하게 행동하면 policy를 improve할 수 있다고 하는데 정말 그럴까?
먼저 state s에서 policy를 따를 때 value function이 있다고 해보자.
value function은 state s에서 policy로 action을 하나 고르는 action function 함수인q_pi(s,a)와 같다.
이 값은 state s에서 할 수 있는 모든 action value 값들 보다 작거나 같을 것 이다.

따라서 max값은 greedy policy를 따랐을 때 q값이 된다.

위 식은 one step에서 greedy 한 방법으로 imporve한 policy를 따르는 값이 더 크다는 것을 이야기 한다.
이를 반복적으로 하게 되면 결국 improve한 policy가 가장 큰 value function값을 가지게 한다고 보일 수 있다,
따라서 Improvement가 끝나게 되면

위 식이 되고, 이는 Bellman optimality equation을 만족하게 된다.
결국 value function이 max action function과 같아지면서 value function이 optimal value function이 되고

그에 대한 policy도 optimal policy가 된다.
Modified policy iteration
그렇다면 policy evaluation은 꼭 value function으로 수렴해야 하는 걸까? 아니면 중간에 멈춰서 policy를 평가해도 되는 걸까? 실제로 반복 횟수(k)를 100으로 해도, 1로 해도 상관은 없다. 이에 따른 방법들이 존재한다.
Principle of optimality
기존에 subproblem을 cahce 혹은 store해서 최종 해를 구하는 방법에 대해서 이야기 했었다.
이 방법을 사용해 state에서 value 값을 알면 one-step lookahead를 통해 최적 value 값을 알 수 있다.
식으로 표현하면 아래와 같다.
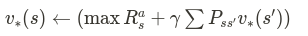
이 식은 Bellman optimality equation으로 Bellman 식에는 optimality와 expecation 식이 있다.
expectation은 optimaility식과 다르게 역행렬로 넘겨서 해를 구할 수 있다.
Deterministic value Iteration
value iteration은 앞서 말한 policy iteration과는 다른 내용이다. value iteration에는 정해진 policy 없이 value 값만
iteration 한다. value iteration이 가지는 문제는 optimal policy를 찾는 것이다.
그에 대한 해는 Bellman optimality backup을 반복적으로 적용하는 것이다.
Synchronous DP Algorithms
Asynchronous DP
DP알고리즘들은 모두 synchronous backup을 사용한다. 즉 모든 state들이 모두 업데이트 된다는 뜻이다.
하지만 asynchronous의 경우 여러 방식으로 state들을 업데이트 할 수 있는데, 이는 계산량을 매우 줄일 수 있다.
state들이 반복적으로 여러번 뽑히게 되면 수렴성도 보장 된다.
asynchronous dp를 구현하는 방법으로는 3가지가 있다.
1. Inplace dynamic programming
: value function 업데이트 이전 값과 이후 값을 저장하는 것이 아닌, 업데이트 된 값 하나만 저장하는 방법
2. Prioritised sweeping
: state를 업데이트 함에 있어서, 단순히 업데이트 하기만 하면 상관없지만 중요한 state들을 우선으로 업데이트 하는 방법.
중요한 state 들은 Bellman error가 컸던 state가 중요한 state가 된다.
3. Real-time dynamic programming
: state space가 매우 큰데, agent가 가는 state를 먼저 업데이트 하는 방법.
추가
* Full Width Backup - Sample backup
: DP는 state를 구하기 위해 이전 state들을 모두 참고하여 update 하는데, state들이 많아지만 full width backup을 할 수 없게 된다.
이를 차원의 저주(curse of dimensionality)라고 한다. 차원의 저주를 피하기 위한 방법으로 sample backup이 있다. 차원이 커지고
모델이 없어도 사용 가능하다. state에서 어떤 action을 취하여 sample 100개를 가지고 state를 업데이트 해주는 방법.
'미니멀공대생 > Control' 카테고리의 다른 글
| [임피던스 제어] Direct Impedance Modulation (2) | 2021.08.23 |
|---|---|
| Multiobjective Optimization for stiffness and position control in a soft robot arm module (4) | 2021.07.26 |
| [임피던스 제어] "Simple" Impedance Control (2) | 2021.05.22 |
| [Null space control] Null space control이란? (8) | 2021.05.18 |
| [Null space control] Nullspace에 대하여 (2) | 2021.05.18 |