
티스토리 뷰
Multiobjective Optimization for stiffness and position control in a soft robot arm module
미니멀공대생 2021. 7. 26. 16:23
배경지식 :
distance metric : https://joonable.tistory.com/14
absorbing state : https://en.wikipedia.org/wiki/Absorbing_Markov_chain
hypersphere : https://cumulu-s.tistory.com/9
[Abstract]
이 논문의 주된 목적은 노인을 위한 입욕을 도와줄 로봇 팔을 연구하는 데 있다. 논문에서는 소프트 로보틱스 기술의 원리를 이용하여 안전한 사람-로봇 상호작용을 위한 compliant한 시스템의 디자인과 제어를 제안하고 있다. 디자인적인 요소로 신장, 수축, 전방향 벤딩을 가능하게 하는 radial arrangemet에서의 텐던과 공압으로 구성된다. 또한 주어진 구성에서 케이블과 텐던의 시너제틱(synergetic)한 동시 활성화(coactiavation, 아마도 텐던과 케이블을 동시에 조작한다는 뜻인 것 같다)를 통해 강성에 대한 변화가 가능한데, 이는 washing과 scrubbing을 가능하게 해줄 것이다. 논문에서 주장하는 참신함은 강성변화를 가능하게 하는 세가지의 작동 사례를 보인다는 점과 강성과 위치를 동시에 최적화하는 협동 멀티에이전트 강화학습 기반의 새로운 알고리즘 개발에 있다.
[Introduction]
일반적인 소프트 매니퓰레이터는 직렬 방식으로 3개의 모듈을 연결하는 형태로 1) 몸체 부분은 케이블 기반 엑추에이터로 이루어져 중력을 보상하는 데 주로 사용된다. 2) 중심부와 말단 부위의 경우 hybrid actuation으로 입욕과 일을 수행하기 위해 자동으로 신체 부위에 도달하는 부분이다. 아래 사진을 참고하면 더 자세히 알 수 있다.

말단부 디자인이 실제 작업을 하는 부분이라 매우 중요하다. 이 논문은 Towards the development of a soft manipulator as an assistive robot for personal care of elderly people 라는 논문에서 이야기한 말단부 모듈의 운동학적 특성, 제어 그리고 제작에 대한 내용을 참고한다. 이 논문은 전 논문을 참고하여 3가지를 중점으로 두었다. 1) 무게를 줄이는 최적화 측면 2)하이브리드 엑추에이터의 synergetic coactiavation을 통한 기계적 강성 변화 3)multi obejctive(강성과 위치)에 대한 제어 알고리즘으로 구성된 제어기 설계
[Design]
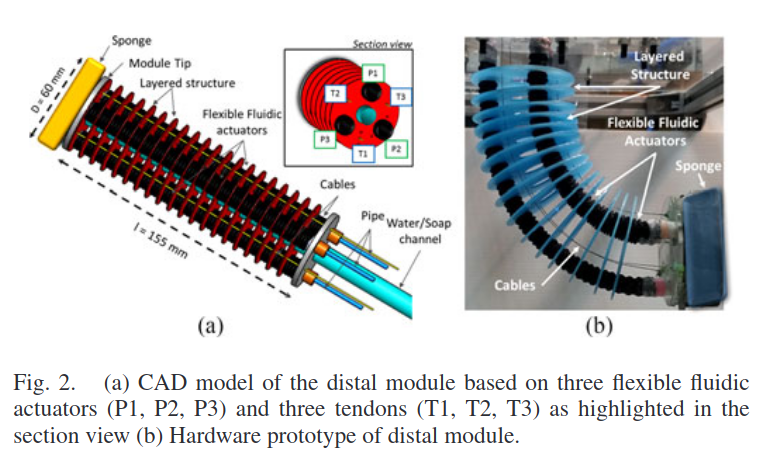
[Stiffness variation]
강성이란 몸체가(논문에서는 elastic body) 가해지는 힘에 대한 변화를 저항 할 수 있는 정도를 말한다. 즉 외부 힘에 얼마나 변하는지에 대한 수치. 논문에서 단순히 cable이나 공압(혹은 유압)만 사용한게 아니라 hybrid로 하게 된 이유가 바로 다양한 환경에서의 강성을 변화시키기 위함이다.
tendon의 tension에 대해서 chamber의 압력을 바꾸는 것으로 강성을 바꿀 수 있는데, 변화의 크기 자체는 액추에이터의 한계에 연관이 있다.
말단부 모듈에는 3개의 기본 configuration이 존재하는데, 어떤 configuration에서 모듈에서의 전반적인 강성은 한개 이상의 base configuration의 조합으로 이루어진다.
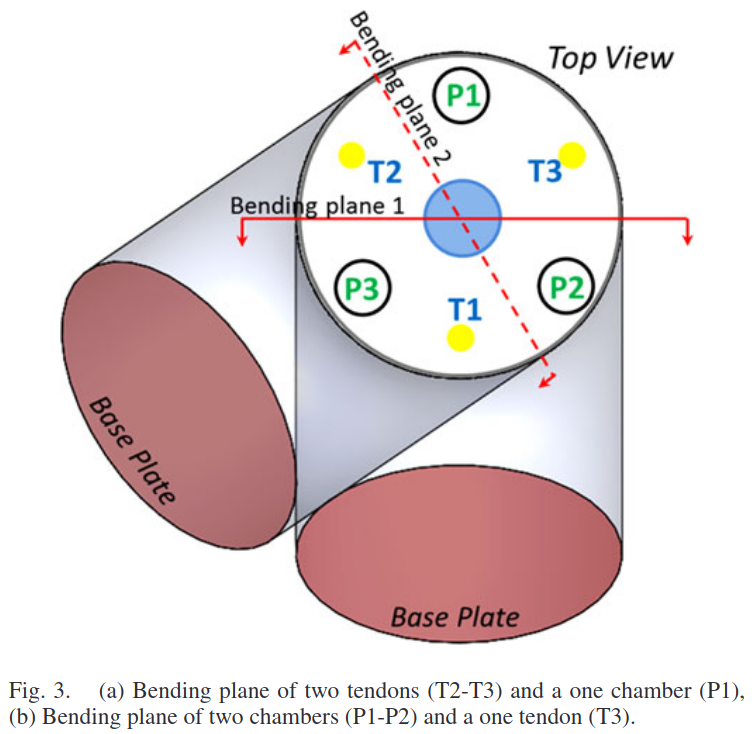
A. Bending due to Two Tendons and One Chamber
단일 챔터 P1을 부풀리면서 측면 텐던 T2,T3를 풀게 되면 밴딩 모션이 생긴다. 강성을 바꾸기 위해서는 텐션이나 압력이 변화되야 한다.
B. Bending due to One Tendon and Two Chamber
챔버 P1,P2를 부풀리면서 텐던 T3를 풀게 되면 밴딩 모션이 생긴다. 이전 시나리오와 비슷하게 강성은 텐션이나 압력의 변화로 바꿀 수 있다.
C. Elongation/Contraction
elongation에서 강성은 tendon을 줄이면 되고, contraction에서는 챔버의 압력을 조절하면 된다.
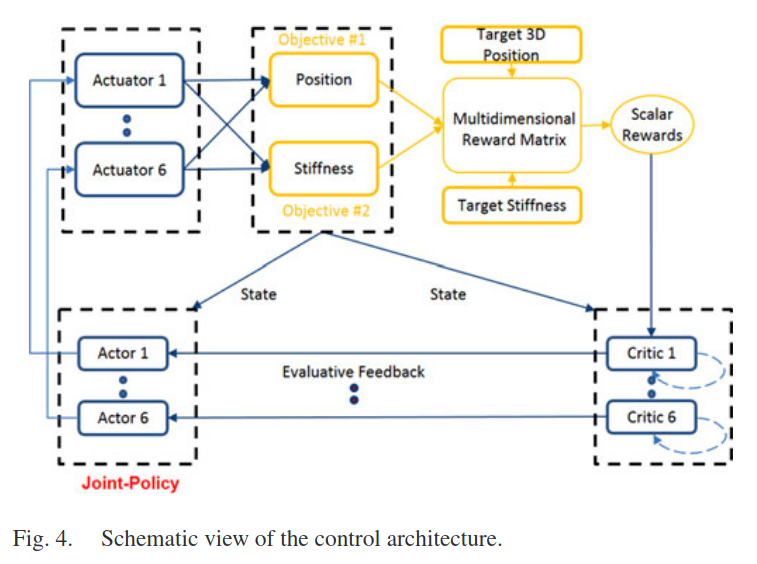
[Control Architecture]
각 액추에이터들은 환경에서 자동으로 움직이는 에이전트로 고려된다. 이때 매니퓰레이터(로봇팔)은 동일한 환경을 공유하는 에이전트들의 그룹으로 이루어져 있으며 MAS(multiagent system) 라고 본다. 특정 위치에 도달하기 위해서 각 에이전트는 자신의 행동을 조정하는(coordinate)방법을 배워야한다. 이는 model free rl을 통해서 학습된다. 각 에이전트는 독립적인 학습객체(Iterated Prisoner's Dilemma)이다.
[Background]
강화학습에서 단일 에이전트가 환경과 상호작용하는 것은 MDP로 모델링 되는데, MDP는 task space인 S와 action set인 A, system dynamic distirbution 로 이루어져 있다. 에이전트는 주어진 상태에서 policy를 따라서 action을 선택하게 되고 reward를 받는다. 초기 state부터 에이전트는 MDP와 Policy를 통해 trajectory를 생성하기 위해 반복해서 상호작용 한다. state, action, reawrd 형태로 계속 진행하게 되면 결과로 Retrun값이 나오는데 이를 cumulative discounted reward라고 한다. 논문에서는 finite horizon setting(gamma = 1)을 주로 다루게 된다. 제어 문제에서는 상태 s에서 action을 취하고 policy를 따르는 것을 action-value function Q로 정의된다.
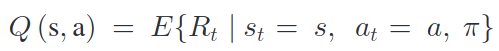
각 에이전트에 전용의 Q 함수를 할당해주는 것으로 multiple agent로 확장된다. Multiagent system의 joint-policy는 아래와 같이 나타내진다.
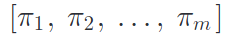
학습에서 목적은 주어진 시작 지점에서 도착지점으로 도달할 수 있는 control joint-policy를 Q 함수에서 뽑아내는 것이다.
[Approximate Reinforcement Learning]
현실에서의 시나리오는 연속적인 도메인(continuous-domain) 문제로 이루어져 있다. 이는 근사가 필요한 Q 함수로 정확하게 나타낼 수 없다.(?)
논문에서는 아래와 같은 선형 근사 함수를 고려한다. w의 경우 파라미터 벡터이며, 세타의 경우 binary basis function들의 벡터이다.

[Model Free RL]
확률론적 환경에서의 물리 시스템의 다이나믹 시스템은 알지 못한다. 논문에서는 policy iteration 기반 Temporal difference 기반 방법에 중점을 둔다. 이는 파라미터화 된 Q 함수로부터 control policy를 만들어낸다. 선형 근사 함수로 on policy TD learning인 SARSA 알고리즘은 off policy TD learning에 대해서 확실히 이점이 있기에 논문에서 사용되었다.
주어진 time step t에서 주어진 policy에 따라 action이 선택되게 된다. 이는 eligibility trace들을 L2 norm을 줄여 증가시키는 SARSA를 통해서 action value function인 Q가 평가를 하게 된다. 다음 tiem step에서는 action value 함수인 Q를 통해서 greedy하게 움직이는 향상 된 policy가 생성 된다. (policy iteration에서는 Q함수가 critic, policy가 actor라고 불린다) 이 process는 policy가 일정해질 때까지 계속 된다.
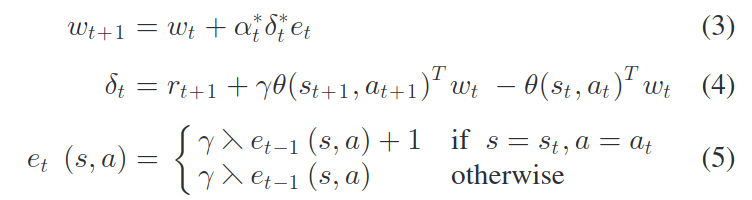
[Reward structure]
리워드는 distance metric으로 구현됐는데, 타겟 중심에 불규칙적으로 나눠진 concentric hyperspheres(task space의 차원)를 생성한다. target을 감싸는 hypersphere는 absorbing state 밖에 없다. 처음과 두번째 hypersphere 사이에 할당된 리워드는 -1인데, 크기 10으로exponential하게 줄어든다. 비록 이 방법이 rich한 state space 정보로 학습을 용이하게 하지만, 이산적인 action-set과 고차원 인풋이 섞이면 시스템을 jittering에 약하게 만든다.(여기서 말하는 jittering이 뭔지 모르겠다 그라디언트에서의 jitter를 말하나?) 이런 문제를 policy는 state space에서 중간 도착지점을 지나는 것으로 해결하려 한다. 다시 말해, 전에 만난 어떤 reward 값보다 큰 스칼라 값을 받는 joint policy를 만났다면, 다음 에피스드에도 시스템이 선택하는 첫번째 행동이 될 것이다. 이를 통해 temporally ordered policy들을 배울 수 있게 한다.
[Multi objective RL]
다수의 목적을 가진 문제는 Multi-objective reinforcement learning(MORL)이라고 불린다. 이때는 reward가 스칼라 값이 아닌 vector 형태의 reward를 받게 되고 각 리워드들은 각 목적에 대한 값들이다. 각 목적들은 상충되거나, 보완되거나, 독립적일 수도 있다. 여기서 목표는 다수의 리워드를 최대화 하게 학습된 control policy가 Pareto optimal하게 만드는 것이다. 다 목적성은 Multi-agent RL framework에 적용해볼 수 있었는데, 이는 다수의 독립 된 에이전트가 특정 타겟을 달성하는데 글로벌한 스칼라 값을 통해 학습한 joint policy가 Pareto optimal이라는 점을 추론하여 가능하였다. 결론적으로 논문에서 말하는 아이디어는 다 목적을 하나의 목적으로 바꾸고 문제 자체를 일반적인 하나의 목적을 위한 하나의 policy를 생성하는 문제로 취급한다는 것 이었다. information theoretic 방식을 착안해서 reward를 구성하였다. 각 목적의 distance metrics는 다차원의 매트릭스의 차원으로 표현되었다. 이때 매트릭스는 다 목적의 순서 조합은 모든 목적에 대한 joint policy의 영향력을 표현하는 하나의 scalar값을 가지게 된다(?..?)
[Multidimensional Reward Matrix]
논문에서는 position과 stiffness를 목적으로 두는데, 각 목적에는 5개의 지역을 만들어서 값을 줄여가면서 부여해줬다. 두 목적을 합쳐서 3차원 공간에서 1.5mm안쪽으로, 그리고 그 위치에서 0.2N/cm의 강성을 가지는 경우에 absorbing state에 도달했다고 하였다.
[Synthetic Roll-outs]
TD를 최소화 하기 위해서 model free의 경우 on policy action 노이즈가 필요하다. 현실에서는 힘든 데 이를 피하기 위해서는 인공의 on policy trajectory를 만들어주면 된다. 논문에서는 hash-table를 통해 이를 적용했다. (어떻게 했는지는 자세히 안나옴...)
[Stiffness characterizaion]
각 기본 configuration의 강성 기능을 특성화 하기 위해서 수평, 횡 방향의 force-displacement 데이터를 각 actutation에 따라 수집했다.
configuration 1: 두개 텐던을 30도 풀어준다. 이때 챔버는 0.9 bar~1.7 bar 사이에서 0.2만큼 바꿔준다.
configuration 2: 한개의 텐던은 30도 풀어주고, 옆에 있는 챔버들은 0.9에서 0.2씩 증가시켜 1.7bar까지 증가시킨다.
configuration 3: 모든 텐던들은 회전의 30도 만큼 풀어주고 모든 챔버를 0.9에서 1.7까지 0.2씩 증가시킨다.
이 3가지를 텐던 50도만큼으로도 동일하게 실시한다.

일반적으로 주어진 텐던 상황에서 챔버 압력을 높이는 것은 강성을 높였다.
[Memory]
제어 알고리즘을 위해 motor space와 task-space가 bending configuration에 따라 hash-table에 매핑됐다. Motor space의 경우 각 bending configuration에 대해서 서보모터 값을 50도로 제한됐고, 각 챔버에 압력에 따라 지역마다 125개의 조합으로 구성됐다.
task space의 경우 각 액추에이터에 따라 카타시안 좌표값과 강성값이 기록되었다. 아래 사진은 계산된 강성 맵과 카타시안 좌표 포인트 클라우드

주어진 actuaton 영역에서 봤을 때 강성변화와 함께 위치 변화도 존재하는 걸 알 수 있다. 따라서 타겟 위치에 높은 정확도를 가지고 도착하면서 동시에 강성 값도 최적화 하는 부분을 학습으로 해결해야 한다.
[Learning]
각 configuration에 따라 강성값이 설정 됐을 때 설정한 강성값과 주어진 타겟 위치로 도달하는 게 학습의 목적이 된다. 학습이 수렴 됐을 때는 2가지로 평가가 이루어졌다. 1. 도달 에러, 2. 해결하는데 걸리는 시간 결과는 아래 2차원 리워드 매트릭스를 통해 볼 수 있다.
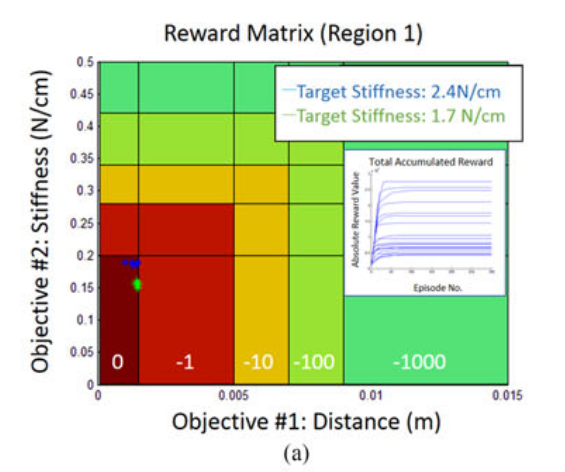
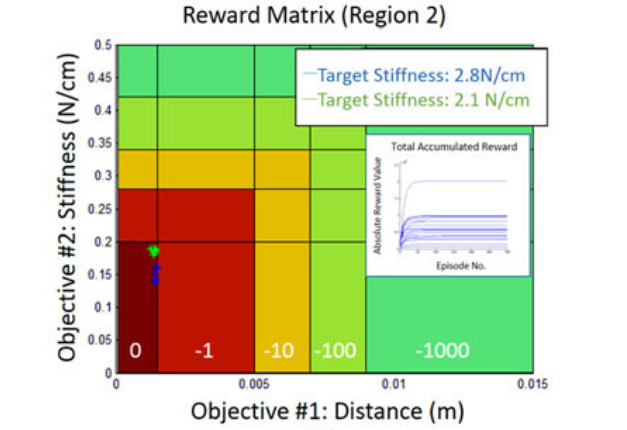
잘 이해하지는 못했지만, 정리한게 아까워서 올려봅니다.
'미니멀공대생 > Control' 카테고리의 다른 글
| [Null space control] Null space Projection for redundant manipulator (1) | 2021.09.15 |
|---|---|
| [임피던스 제어] Direct Impedance Modulation (2) | 2021.08.23 |
| [강화학습] Dynamic programming (0) | 2021.06.04 |
| [임피던스 제어] "Simple" Impedance Control (2) | 2021.05.22 |
| [Null space control] Null space control이란? (8) | 2021.05.18 |