
티스토리 뷰
반년전에 공부하면서 정리한 강화학습 내용을 다시 복습할 겸 올리는 중입니다.팡요랩 유튜브 영상을 보며 정리한
내용이며, 분명히 틀린 내용이 많으니 만약 보시는 분들은 참고용으로만 보시면 좋을 것 같습니다.
팡요랩 유튜브 영상 : https://www.youtube.com/watch?v=NMesGSXr8H4
강의 자료 (David silver) : https://www.davidsilver.uk/wp-content/uploads/2020/03/MDP.pdf
Policies
policy pi는 주어진 state에서의 action을 이야기 한다. policy는 agent의 행동을 지정하는데, MDP에서의 Policy는
현재 state와 관련이 있지만 History와는 관련이 없다. 즉, policy는 시간과 관련이 없이 독립적이다는 뜻이다.
MDP M은 = <S , A, P, R, gamma>와 pi에서 state의 sequence는 Markov process <S, P^pi>이고 여기에 reward를 추가한 모양은 <S, P^pi, R^pi, gamma>가 된다.
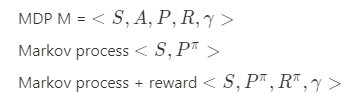
policy가 포함 된 state의 Probability와 Reward를 정리하면 아래와 같다.

즉, 특정 state에 대한 action의 policy와 각각 Probability와 Reward를 곱하면 된다.
State & action value function
state-value 함수의 경우 state s에서 시작해서 policy를 따라서 나오는 return 값들의 기대값이다. return에 대해서 다시 이야가하자면 return은 reward의 discounted amount를 말한다.
action-value 함수의 경우 state s에서 시작하여 action a를 실행하고 policy를 따라서 나오는 return 값들의 기대값이다.
이를 식으로 표현하면 아래와 같다.

넘어가기 전에 state와 action과 value function에 대해 생각해보는 시간을 가져보자. agent가 있는 state에서 어떤 action을 취할 수 있고 그 action에 따라 받게 되는 reward도 달라진다. 따라서 agent가 높은 reward를 받기 위해서는 다음 state로 갔을 경우 받는 reward를 알아야지
그에 맞는 action을 취할 수 있다. 이때 단순히 다음 state로 가는 방법말고 action을 어떻게 취하는 지에 대한 평가도 이루어질 수 있는데 이게 action value function이 된다. state value function이 아닌 다음 행동을 취할 때 action value function만 알면 되기 때문에 state value function이 필요없어진다. action value 함수의 정의를 다시 이야기 하자면, state s에서 action a를 취할 때 받는 return의 기대값이 된다. 즉 단순하게 어떤 action을 취하면 더 좋은지가 된다.
Bellman Expectation Equation
state value 함수는 immediate reward와 successor state가 discount된 형태로 표현이 가능하다.
이때 다음 state와 현재 state의 value fuction의 관계를 식으로 만들어내면 바로 Bellman equation이 된다.
물론 action value 함수도 비슷한 형태로 표현이 가능하다.

이 식을 기대값 형태가 아닌 식 형태로 표현할 수 있다.

식을 잘보게 되면, state value function은 action value function으로, action value function은 state value function으로 표현할 수 있다는 걸 알 수 있다. 이 두개의 식을 또 정리하면 아래와 같이 된다.

state value function에 대한 direct solution을 구하기 위해서 행렬의 형태로 식을 표현할 수 있다.
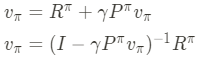
Optimal value function
강화학습의 목적은 reward를 최대로 하는 policy를 찾는 것이다.
optimal state value function은 v*(s)로 표현 되는데, 모든 policies에 대해 최대 value function을 말한다.
optimal action value functio도 똑같이 q*(s,a)로 모든 policies에 대해 최대 action value function을 말한다.
식은 아래와 같다.

optimal value function에서는 MDP에서 찾을 수 있는 최고의 performance를 알려주고, 이 optimal value function을
알게 되면 'MDP를 풀었다'라고 할 수 있다.
Optimal policy

어떤 policy들이 있을 때 두개를 항상 비교할 수 있는 건 아니라고 한다. 다만 특정 policy들 중에 두개를 비교할 수 있는데 그 경우는 모든 state들에 대해서 state value function의 값이 policy prime인 경우보다 일반 policy인 경우가 더 클 때이다.
1. 모든 MDP에 대해서는 optimal policy가 존재하는데, 이는 다른 모든 policy들 보다 크거나 같다.
2. optimal 한 policy를 따라가면 그 optimal state value function은 결국 optimal value function V*(s)와 같아진다.
3. 모든 optimal policy를 따라가면 optimal action-value function과 같다. (optimal policy는 하나 이상일 수 있다)
Bellman Optimality Equation
앞서 이야기한 Bellman equation에서 max로만 바꾸면 되기 때문에 생략하고 BQE를 푸는 것에 대해 이야기해보려 한다.
벨만 최적식은 비선형이기 때문에 closed form 해가 없다. 이를 해결하기 위해서 사용되는 방법들이 아래 4가지 이다.
1. Value Iteration
2. Policy Iteration
3. Q-learning
4. Sarsa
'미니멀공대생 > Control' 카테고리의 다른 글
| [Null space control] Nullspace에 대하여 (2) | 2021.05.18 |
|---|---|
| [임피던스 제어] Interaction Control 적용 - Virtual Trajectory & nodic impedance (4) | 2021.05.14 |
| [강화학습] Markov Decision Processes(1) (3) | 2021.05.04 |
| [임피던스 제어] Coupled Systems 분석 (3) | 2021.05.03 |
| [임피던스 제어] Port Behavior과 Transer function(전달함수) (0) | 2021.05.03 |