
티스토리 뷰
반년전에 공부하면서 노션에 정리한 강화학습 내용을 다시 복습할 겸 올리는 중입니다.
팡요랩 유튜브 영상을 보며 정리한 내용이며, 분명히 틀린 내용이 많으니 만약 보시는 분들은 참고용으로만 보시면 좋을 것 같습니다. 강화학습이지만 귀찮으니깐 제어 카테고리에 넣겠습니다.
팡요랩 유튜브 영상 : https://www.youtube.com/watch?v=NMesGSXr8H4
강의 자료 (David silver) : https://www.davidsilver.uk/wp-content/uploads/2020/03/MDP.pdf
Markov Decision Processes
MDP는 RL에서 주어지는 환경을 이야기한다. 이때 환경은 관찰할 수 있으며, MDP는 RL에서 주어지는 환경을 이야기한다. 이때 환경은 관찰할 수 있으며, 현재 state가 process를 완벽히 특징화한다. 대부분의 RL 문제들이 MDP 형태로 가공이 가능하다. 최적제어의 경우 연속적인 MDP를 주로 다루며, Partially observable 문제도 MDP로 변환이 가능하다.
현재 State인 St는 과거의 정보들 (S1~St)를 모두 포함하고 있다고 볼 수 있다. 따라서 현재 state 상태를 안다면 과거 정보는 필요 없어진다.

상태는 미래의 충분 통계량(sufficient statistic)이다.
충분 통계량에 대한 내용 : https://m.blog.naver.com/PostView.nhn?blogId=sw4r&logNo=221379169569&proxyReferer=https:%2F%2Fwww.google.com%2F
현재 상태 St는 위의 조건을 만족해야만 Markov라고 부를 수 있다.
State Transition Matrix
Markov state s와 successor state s'에 대해서 state transition probability는 아래와 같이 정의 된다.
간단하게 State가 s일 때 t+1시간에서 state가 s'일 확률값이 state transition probability된다.

이런 이 state transition 확률은 매트릭스 형태로 나타낼 수 있다.

Markov Process
Markov Process는 메모리가 없는 랜덤한 프로세스로 랜덤한 state들에 연속으로 표현된다. 각 state들은 다른 state로 넘어갈 때의
확률이 정해져 있고 이를 <s,p>로 표현한다. s는 state이며, 아래 사진은 학생의 Markov chain을 나타낸다.
디지털 논리회로 시간에 나를 괴롭혔던 Finite state machine이랑 비슷하다.
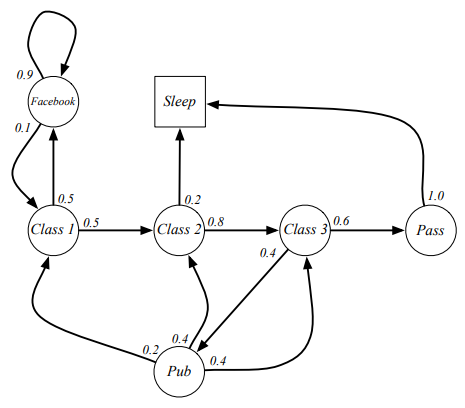
특정 행동 패턴의 state들의 모음을 episode라고 한다. 예를 들어서 위의 chain에서는 c1-c2-c3-pass-sleep이 episode이며 c1-FB-FB-c1-c2-sleep 또한 eposide가 된다. 이때 state에서 state들을 왔다갔다 하는 확률을 변환 매트릭스로 정리하면 아래와 같다.

Markov Reward Process
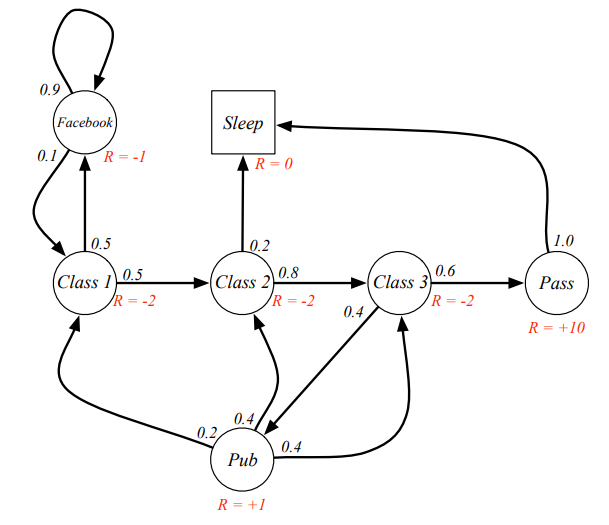
기본적인 Markov Process가 각 state들의 확률이 정해져 있었다면, MRP는 각 state들에 대한 Reward가 정해져 있는 형태이다. MRP는 <S,P,R,gamma>로 표현 된다. 여기서 R은 reward함수로 아래와 같이 평균값 평태로 표현된다.

gamma의 경우 discount factor로 0~1 사이의 값이 된다. MRP의 기본적인 예제는 아래
Return
return 과 reward는 다른 개념이다. Return은 reward를 discount한 값을 모두 더한 값이다.
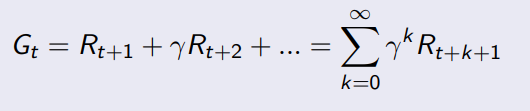
Discount
Markov reward와 decision processes에서는 discount를 하는데, 그 이유는 reward를 discount 하는 게 수학적으로 편리해서이다.
또한 MP가 무한정으로 돌아가는 것을 막기 위해서이다. 또 미래에 대한 불확실성이 표현되지 않기 때문에 reward에 discount를 해준다.
경제적으로 고려했을 때 바로 앞에 들어오는(빨리 들어오는) reward가 더욱 효과적이고 나중에 들어오는 reward는 그렇지 못하기 때문이다.
Value Function
MRP의 value 함수는 v(s)로 표시되고 이는 state s에서 return의 기대값이다.

Bellman Equation for MRPs
벨만 방정식은 현재 상태와 미래의 성공확률에 대한 수식적 표현이다. 조금 더 풀어말하면, MDP로 문제를 정의 할 경우 state와 action에 대한 value function들이 생기게 된다. 이들이 현재에서의 state, action과 미래의 state, action에 대한 관계식을 만들면 이를 벨만 방정식이라고 한다. 근데 silver 강의자료에서는 value function을 2개로 나눈다.
- 즉각적인 reward Rt+1
- discounted 된 successor state 인 값.
2개를 이용해서 value function을 정리하면 아래와 같다. 매트릭스 형태로 표현할 경우도 아래와 같다.


Bellman Equation solving
벨만 방정식은 단순히 역행렬을 해주는 걸로 풀 수 있다고 볼 수 있지만, 실제로는 작은 MRP에서만 풀 수 있다.
큰 형태의 MRP를 풀기 위해서는 수치해석 방법처럼 반복적으로 푸는 DP, Monte-Carlo, TD와 같은 방법을 사용해야 한다.
Markov Decision Process
MDP는 Markov reward process와 decision이 합쳐진 형태이다. MRP와 다른 점은 MRP에서는 state들에 이름이 있고 특정 state에 도착하면서 reward를 받는 형태였다. MDP는 어떤 action을 하게 되면 그에 따른 reward를 받게 된다. 이때 환경에서 모든 state는 Markov해야 한다.
MDP는 아래와 같이 표현 된다. MRP에서 Action인 A가 추가 됐다.

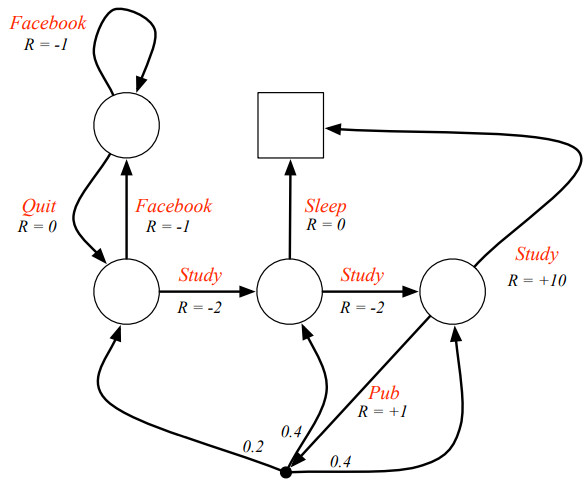
다음 글에서는 Policy부터 다루겠다.
아직 chapter 2 인데 왜케 많지...? 강화학습 전문가들 사이에서 기초이론 올리기~
'미니멀공대생 > Control' 카테고리의 다른 글
| [임피던스 제어] Interaction Control 적용 - Virtual Trajectory & nodic impedance (4) | 2021.05.14 |
|---|---|
| [강화학습] Markov Decision Processes(2) (2) | 2021.05.11 |
| [임피던스 제어] Coupled Systems 분석 (3) | 2021.05.03 |
| [임피던스 제어] Port Behavior과 Transer function(전달함수) (0) | 2021.05.03 |
| [임피던스 제어] 기계적 임피던스와 어드미턴스 (2) | 2021.05.03 |