
티스토리 뷰
강화학습 Tips and Tricks(2)
Author: Benthebear93[이해구]
Reference: https://medium.com/@BonsaiAI/deep-reinforcement-learning-models-tips-tricks-for-writing-reward-functions-a84fe525e8e0 https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html
본 글은 reference 내용의 번역본입니다.
이번 글에서는 RL모델을 학습 시키는데 필요한 reward function(보상함수)를 효과적으로 작성하는 방법에 대해서 다루려고 한다.
The Cobra Effect
RL모델을 학습 시키는데 필요한 reward function(보상함수)를 작성하는 건 직원들에게 줄 인센티브를 정하는 것 만큼 쉽지 않다. 코브라 효과(The cobra effect)라고 하여 단순히 인센티브를 주는 것이 좋은 결과를 야기하는 것은 아닐 수 있기 때문이다. 과거 영국 정부는 코브라를 없애기 위해 사람들에게 코브라를 가지고 오면 돈을 주기로 했다. 이는 사람들이 코브라를 집에서 키워 돈을 받는 결과를 만들었다. 보상함수를 작성할 때는 코브라 효과를 항상 염두에 두자. 우리가 보상을 준 것만 얻는 것이지 원하려고 한 결과를 얻는 것은 아닐 수 있다.
Reward Function Fail
예를 들어서 로봇팔을 이용해 물체를 집은 후 물체 위에 쌓으려는 작업을 학습시키려 한다고 해보자.
가장 먼저 단순하게 로봇 팔을 이용해 물체를 옮기려고 했다. 초기 보상함수는 로봇 팔에서 가장 멀리 물체를 옮기는 것에 집중하였는데, 엔지니어는 "로봇 팔이 물체를 집어서 최대한 뻗은 다음 물체를 내려놓을 것이다" 라고 생각했다. 하지만 로봇 팔은 물체를 최대한 강하게 때려서 멀리 보내는 방식을 학습했다. 그 후에는 단순히 때리는 것이 아닌, 물체를 집이서 던지는 게 더 멀리 보낼 수 있다는 걸 학습했다. 즉, 보상함수를 작성하면서 보상함수가 하려는 것이 뭔지 잘 알고 있어야한다.
Shaping your reward
보상함수를 shaping하는 것은 중요한 일이다. 만약 보상이 sparse(부족)하다면 에이전트는 exploration 시간 동안 피드백(보상)을 받지 못하게 되고 이는 학습 시간의 증가로 연결된다. 반대로 점진적으로 reward를 받는 형태로 작성해야 agent가 목적에 달성하고 있다는 피드백을 받게 되어 학습을 빠르게, 잘 할 수 있다.
Positive Rewards
보상 자체를 수학적으로 선택하는 데 있어서 결과에 많은 영향을 줄 수 있다. 만약 보상을 양수로 주게 된다면 agent는 보상을 최대한 많이 쌓으려고 한다. 이는 이상한 행동을 학습 시킬 수도 있다
예를 들어서 로봇이 물체를 쌓는 경우에 끝까지 쌓지 않고 부순 후 다시 쌓는 행동을 반복하여 보상을 계속 쌓으려고 할 수도 있다. 즉 양수의 보상의 경우
1. 보상을 계속해서 쌓으려고 한다.
2. 학습을 끝내는 것에 매우 큰 보상이 걸려있지 않으면, 굳이 끝내지 않으려 한다.
양수의 보상을 설정할 때는 이런 문제들을 조심해야한다. 행동을 끝내는 것에 매우 큰 보상이 있지 않는 한 끝나는 경우 근처에 보상을 많이 설정하지는 않도록 한다.
Negative Rewards
음수 보상은 좀 다르다. 음수 보상은 agent에게 현재 보상을 잃고 있으니 최대한 빠르게 게임을 끝내라고 말하고 있는 것이다.
즉 음수의 보상의 경우
1. 쌓여가는 패널티를 피하기 위해 종료 지점에 최대한 빠르게 도달하려 한다.
Understanding the area you're playing in

2차원 공간에서 agent 가 왼쪽 아래의 빨간색 공간에 도착하려고 한다 해보자. 파란색에 닿으면 crash인 경우이다. 단순히 거리값에 대한 보상 함수를 작성한다면 성공은 할 수 있지만 파란색에 부딪치는 경우도 많을 것이다.
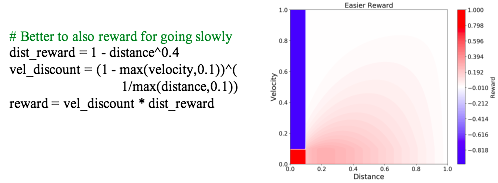
그와 반대로, 거리값에 대한 보상과 거리값, velocity에 대한 discount값을 같이 섞어주게 되면 도달하는 시간은 좀 느릴 수 있지만 실제 파란색에 부딪치는 경우는 확연이 줄었을 것이다.
Time and space
보상 함수를 작성하면서 시간과 공간에 대한 고민도 같이하면 좋다. 이는 특정 문제를 작은 문제들로 나누는 것 처럼 중요하다.
예를 들어 로봇 팔로 물체를 들어올리는 경우에 [ 1. 물체를 집고, 2. 방향을 조절하고, 3. 쌓고 ] 이렇게 3가지의 동작을 하게 된다.
당연하게도 로봇 팔이 아직 물체와 먼 상태에서 집는 걸 학습하는 데 시간을 낭비하고 싶지는 않을 거다. 따라서 reward function과 activation function을 작성하여 실제로 물체를 집을 수 없는 공간에서 시간 낭비를 피하게 할 수 있다.
문제가 단순 할 경우 보상 함수에 여러개를 섞는 것이 가능하지만, 복잡한 경우 단순히 보상 함수를 복잡하게 하는 것 보다는 concept network와 같은 기술을 고려해보는 것이 좋다.
'미니멀공대생' 카테고리의 다른 글
| 테슬라에서 요구하는 능력을 보자, Tesla Bot (6) | 2023.09.13 |
|---|---|
| [논문리뷰] Mobile manipulation in unknown environmets with differential inverse kinematics Control (4) | 2022.02.27 |
| 로봇 팔과 카메라 calibration with moveit plugin (0) | 2021.08.10 |
| 강화학습 팁 모음 (9) | 2021.06.08 |