
 connected agent simulation -2-
connected agent simulation -2-
어쩌다 보니 2탄 저번에 했던 것에 이어서 connected agent들이 목표지점을 향해 가는 방향으로 학습 할 수 있는 환경을 만들어 볼 수도 있겠다고 생각했다. 아직 시뮬레이션 초기화랑 렌더링 하는 부분까지만 완성을 했는데 open gym 포맷으로 조금씩 발전시켜 나가 볼 듯함. Custom openai gym openai gym은 강화학습을 시작하면 한번쯤은 돌려봤을 환경들인데, 환경과 에이전트가 서로 상호작용한다는 프로세스를 단순화 시킨 프레임워크라 개인 환경을 짠다고하면 대체로 gym 스타일로 짜려고 한다. 요즘엔 gym을 그냥 상속받아서 그안에 step 이나 reset, render 같은 부분을 내가 원하는대로 맞춰서 쓸 수 있는데 방법은 아래 링크를 가면 잘 나와있다. 멀티에이전트 환경의 ..
conditional_filter: /build/pcl-OilVEB/pcl-1.8.1+dfsg1/search/include/pcl/search/impl/organized.hpp:57: int pcl::search::OrganizedNeighbor::radiusSearch(const PointT&, double, std::vector&, std::vector&, unsigned int) const [with PointT = pcl::PointXYZ]: Assertion `isFinite (query) && "Invalid (NaN, Inf) point coordinates given to nearestKSearch!"' failed. conditional filter 튜토리얼을 돌리던 도중에 마주한 에러이..
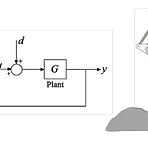 [임피던스 제어] 상호작용 컨트롤(1)
[임피던스 제어] 상호작용 컨트롤(1)
외란억제로서 상호작용 (Interaction as Disturbance Rejection) 다양한 제어이론들이 특징이 잘 설명되어 있지 않은 인터페이스를 다룰 수 있도록 발전해왔다. 외란 억제 방법을 통해서 환경에 대한 다이나믹스가 외란힘으로 추가될 수 있다. 억제를 잘하기 위해서는 외란 힘의 경계값을 잘 정해줘야한다. 하지만 로봇이 환경과 상호작용하는 경우에 외란힘은 로봇의 수용량을 넘거나 동일한 경우가 대부분이다. 예를 들어 운동학적(Kinematic) 제약은 로봇의 행동에 따라 큰 힘을 만들 수 있는데, 외란힘(환경이 주는 힘)은 로봇의 상태와 연관이 있는 데 일반적으로 외란은 상태와 독립적으로 보기 때문에 상호작용을 외란억제 문제로 보는 것은 그렇게 좋지는 않다(not seem promising)..
 [임피던스 제어] 임피던스 제어란?(2)
[임피던스 제어] 임피던스 제어란?(2)
*본 글은 https://summerschool.stiff-project.org/ 내용을 번역, 정리한 글입니다. 전 글에서 임피던스 제어란 환경을 어드미턴스로 두고 로봇과의 임피던스를 제어하는 것이라고 했다. 이를 성능(Performacne)과 안정성(Stability)의 관점에서 이야기해보자. 어떤 모션이나 힘을 제어하려고 할 때, 환경과의 상호작용은 컨트롤 가능한 변수에 영향을 주게 된다. 이런 영향으로 생기는 에러는 성능에 영향을 미치게 되고 안정성 또한 불안정해진다. 이런 불안정성은 coupled/contact instabilities라고 하는데, 단순한 시스템이 환경과 작용할 때도 확인할 수 있다. 한가지 예시를 들어보자. 질량(m)을 가지고 이노시아 값을 알고 있는 간단한 로봇이 있다고 하자..
 connected agent simulation
connected agent simulation
최근에 그래프 신경망을 이용한 프로젝트를 진행중인데 아무래도 그래프가 처음 다루는 자료형이다 보니 익숙하지가 않다. 파이썬에서 배열을 다루는데 특화된게 numpy 라면 그래프에서는 networkx가 있다. networkx.org/documentation/stable/index.html 그래프 신경망을 위한 파이토치라이브러리도 있는데 torch_gemetric이라고 있다. pytorch-geometric.readthedocs.io/en/latest/index.html 일전에 이를 이용해서 간단하게 카트폴 훈련을 시켰는데 REINFORCE로 학습시킴에도 생각보다 빠르게 학습되는 것에 놀람. github.com/keep9oing/GNN_RL keep9oing/GNN_RL reinforcement learnin..
 Pretrained Transformers as Universal Computation Engines
Pretrained Transformers as Universal Computation Engines
Reference(원본): bair.berkeley.edu/blog/2021/03/23/universal-computation/ Pretrained Transformers as Universal Computation Engines The BAIR Blog bair.berkeley.edu 구독중인 버클리 대학의 블로그인데 영어 공부도 할겸 겸사겸사 번역작업 요약을 미리하지면, Transformer라는 자연어 학습용으로 개발된 신경망 모델이 있는데, 이 녀석이 일반화 능력이 엄청좋다는 것이다. 어느정도냐면 언어모델에 대해 미리 학습시키고 그 파라미터를 고정시킨 후 이미지 분류작업에대해 간단히 fine-tuning 학습만 시켜줘도 아주빨리 학습하고 정확도도 좋다는 것이다. 특히 대용량 언어모델에 대해서 미리 ..
 DC Motor Control -2-
DC Motor Control -2-
이번 시간에는 지난 포스팅에서(2년전에 올린) 최종적으로 나온 수식을 이용하여 Matlab을 통해 실제 모터 모델링을 진행하는 시간을 가지도록 하겠습니다. 일단 지난 포스팅의 마지막에 나온 수식은 다음과 같습니다. Va=Ria+Ladiadt+Kω Kia=J˙ω+bω+TL(ω=dθdt) 각 문자가 의미하는 바를 까먹지 않기 위해 다시 한번 정리를 하면, 전기자 회로(Motor) va=Ladiadt+Raia+ea va:전기자회로에가해지는전압[V] ia:전기자권선의전류[A] $R_a : 전기자 권선의 저항[\Omeg..
 강화학습 논문 정리 2편 : DDPG 논문 리뷰 (Deep Deterministic Policy Gradient)
강화학습 논문 정리 2편 : DDPG 논문 리뷰 (Deep Deterministic Policy Gradient)
작성자 : 한양대학원 융합로봇시스템학과 유승환 석사과정 (CAI LAB) 이번에는 Policy Gradient 기반 강화학습 알고리즘인 DDPG : Continuous Control With Deep Reinforcement Learning 논문 리뷰를 진행해보겠습니다~! 제 선배님들이 DDPG를 너무 잘 정리하셔서 참고 링크에 첨부합니다! 그럼 리뷰 시이이작!!! 링크 0 (원문 ) : arxiv.org/pdf/1509.02971.pdf 링크 1 (DDPG 리뷰 1, ppt 정리) : ropiens.tistory.com/37 [Keep9oing] Deep deterministic policy gradient (DDPG) ddpg seminar from 민재 정 두번째 세미나 자료, 역시나 슬라이드 쉐어..