
티스토리 뷰
Abstract
- RL의 time limit을 어떻게 다뤄야 하는지에 대해 연구
- Time limit을 적절하게 고려하지 않을 경우 일어나는 문제점
- state aliasing
- invalidation of experience replay
- 위 문제점들로 인한 sub-optimal policy학습과 training instability 발생
- RL적용 시 time horizon 종류별 time limit에대한 관점 제시
- Fixed period
- 이 경우 time limit은 환경의 부분으로 생각해야하며 Markov property를 위반하지 않기위해선 남은 시간(remaining time)에 대한 개념을 고려해야한다.
- Indefinite period
- Time limit은 환경으로써 고려될 필요 없고, 오직 학습을 위해 사용된다.
- Fixed period
Introduction
- Return:
$$
G_t=R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+\ldots=\sum_{k=1}^{\infty} \gamma^{k-1} R_{t+k}
$$
- Return with time limit:
$$
G_{t: T}=R_{t+1}+\ldots+\gamma^{T-t-1} R_T=\sum_{k=1}^{T-t} \gamma^{k-1} R_{t+k}
$$
- 딱 time limit에 맞춰진 reward maximization policy를 학습하여, time limit이후는 고려하지 않는 위험한(risky) 행동을 하도록 학습될 수 있다.
- 이를 해결하기 위해 agent 입력값에 time limit까지 남은 시간을 함께 넣어주는 time-awareness 개념을 제안한다.
- Fixed time이 아닌 indefinite time horizon task (time unlimited)를 학습하는 경우, agent 경험의 다양성을 증가시키기 위해 time limit을 사용하기도 한다.
- 이 경우 더 효과적인 학습을 위해 partial episode bootstrapping (PEB) 기법을 제안한다.
- 학습 환경적 요건 외에 episode가 종료 됐을 경우 (ex. time limit) bootstrapping을 진행
- Time awareness는 기존 dynamic programming 과 optimal control 분야에서는 널리 사용되던 개념이지만 RL에서는 간과되어 왔음
Main contribution
- Time-awareness 부족으로 인한 문제점 분석
- Time limited task에서 discount factor 영향성 분석
- Partial episode bootstrapping 기법 고안
- 기존 RL 기법의 성능 및 안정성 향상 검증
Time-awareness for time-limited tasks
- Fixed time step T task에 대한 학습은 time limit에 도달하기만 하면 어디서든 termination state가 되는 time-dependent MDP로 볼 수 있다.
- 이 time-dependent MDP는 T개의 time-independent MDP가 쌓인 형태(stack)로 생각할 수 있다.
- (0~T-1) 범위의 각 time step에서 action을 취해 next state로 이동한 것이 next MDP에 속한 state로 이동한 것으로 볼 수 있다.
- 이 때 만약 agent가 time-unaware agent라면, partially observable MDP (POMDP) 문제로 봐야한다.
- 한 state에 대한 remaining time을 알아낼 수 가 없는 상황
- 이런 현상을 state aliasing이라고 부름
- credit assignment의 어려움으로 인한 sub optimal policy 학습 및 불안정성 초래
- 위의 이유로 인해 remaining time T-t를 학습에 포함시키는 것을 제안
- 본 연구에서는 기존 연구보다 더 일반적인 종류의 time-dependent MDP를 고려함
- reward distribution과 transition이 time-dependent
- 본 연구에서는 기존 연구보다 더 일반적인 종류의 time-dependent MDP를 고려함
Ex 1) The Last Moment Problem
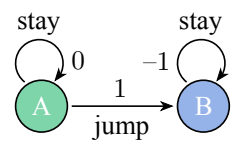
- Optimal time dependent policy 학습 예시
- Fixed horizon 상황이라면 T step 직전인 T-1 step 까지 A에 머무르다 마지막 순간에 B로 넘어가면 optimal
Ex 2) The Two-Goal Gridworld problem

- Time-unaware agent의 state-aliasing 효과 보여줌
- 오른쪽 위로 도착하면 50 reward, 왼쪽 아래로 도착하면 20 reward, 움직일 때마다, -1 penalty, 3 time step 마다 혹은 goal 도달 시 termination.
- Tabular Q-learning (discount rate:0.99) 으로 학습
- a) Standard: time-unaware agent
- 가장 가까운 goal로 들어가려함
- b) Time-awareness: Time-aware agent
- Timeout이 될 것 같은 상태에서는 움직이지 않음
- c) Partial-episode bootstrapping
- Indefinite horizon에 대한 optimal policy 학습
- a) Standard: time-unaware agent
Ex 3) The Queue of Cars problem
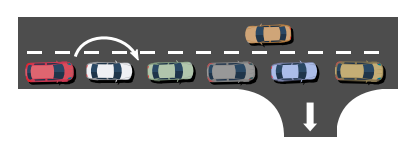
- Time-aware agent가 remained time 에 대해 적응적인 optimal policy를 학습 할 수 있는 경우 예시
- action 1: safe action
- 50% 확률로 전진
- action 2: dangerous action
- 80% 확률로 전진, 10% 확률로 충돌
- 목적지에 도착해야 reward 1로해서 PPO 학습

- Time-aware agent는 time step별로 다른 policy를 학습
- Time-unaware policy는 seed별로 다른 state 의존 policy를 학습
Ex 4) Inverted Pendulum

- T=1000 일때 PPO로 학습 된 value function (blue: time-aware, orange: standard)
- Time-aware agent는 discount rate에 따른 value를 잘 학습하는데 비해 standard agent는 constant value를 학습
Ex 5) Photo finish (Hopper-v1)

- T=300 으로 학습했을 때 마지막 step에서의 behavior 비교 (red line 아래로 중심이 내려오면 넘어진것으로 간주)
- Time-aware agents는 마지막 순간 이동거리에 대한 reward를 최대화 하기위해 달리기 경주하는 사람들이 마지막 스퍼트를 내는것 처럼 행동을 취함 (time limit이 걸려있기 때문에 마지막 순간 이후로는 넘어질때 페널티를 받지 않음)
- Standard agent의 경우 discount rate은 이런 행동을 학습하지 않고 discount rate이 극단적으로 높은 경우 (discount rate: 1) 넘어지지 않고 제자리에서 뛰기만 하는 행동을 학습
Partial-episode bootstrapping(PEB) for time-unlimited tasks
- Infinite time horizon task에 대해 학습하더라도 experience 다양성을 위해 time limit을 설정해서 학습하게 된다.
- 자주 실수하는 바는 이 때 설정한 time limit을 time horizon인 것 처럼 학습하는 것이다.
- time limit 이후의 미래 reward를 고려할 수 없게됨
- 이때 time limit에 의한 termination에서도 bootstrap을 적용하는 방법을 제안
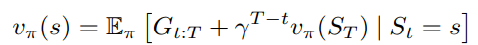

Ex 1) Hooper, Walker, and Cube pusher

- PEB를 도입할 경우 더 좋은 성능을 보임
- InfiniteCubePusher는 환경 reset없이 target만 바뀌는 연속적인 학습환경
Ex 2) Experience replay

- Replay buffer 사용 시 time limit에 대해 적절히 고려되지 않을 경우 non-stationarity 발생
- 또한 buffer size에 대해 성능 변화가 너무 큼
- Goal reaching 을 위한 grid world학습에서 PEB적용을 통해 최종성능에 대한 buffer size의 영향성을 줄일 수 있음
Discussion
- 일반적으로 time-unaware agent들이 괜찮게 학습되는 경우도 많음
- time limit이 너무 긴 경우 timeout 경험을 할 일이 별로 없는 경우
- observation 자체에 time에 관해 연관된 부분이 존재한 경우
- same state에 잘 도달하지 않는 경우
- discount factor가 충분히 작아서 confusion이 적은 경우
- RNN을 통해 POMDP인 상황을 극복할 수 도 있음
- 그러나 제안한 방법론이 적용과 해석이 더 간단함
'keep9oing' 카테고리의 다른 글
| 배터리 모델 간단 정리 (3) | 2024.08.08 |
|---|---|
| 통신 모델 및 관계 간단 정리 (2) | 2024.07.01 |
| 2023년 회고 (4) | 2023.12.31 |
| 로봇 잡생각 - 로봇이 하나의 단위가 된다면 (10) | 2023.03.23 |
| [논문리뷰]Sold!: Auction methods for multirobot coordination (0) | 2022.11.21 |
댓글