
티스토리 뷰
[LLM] Transformer :: GPT 쓰긴 싫지만 GPT 안쓰면 도태될까봐 두려운 할미 MZ의 뒤늦은 LLM 공부 (1) Auto-regressive란?
알 수 없는 사용자 2025. 2. 26. 08:29작성자 : UNIST 기계공학과 석사과정생 임가은
ㅡ
Auto-regressive 란, transformer [1] 의 decoder가 작동하는 방식입니다. 다음 출력을 생성할 때, 이전의 예측 결과를 고려하는 방식이에요. 예를 들어 아직 미완성인 어떤 input sequence (y_1, y_2, ...y_t) 문장이 주어졌을 때, 문장의 다음 단어인 y_t+1 단어를 예측하는 과정에서 앞의 단어들이 등장할 확률을 conditional probability로 고려해 주는 거에요.
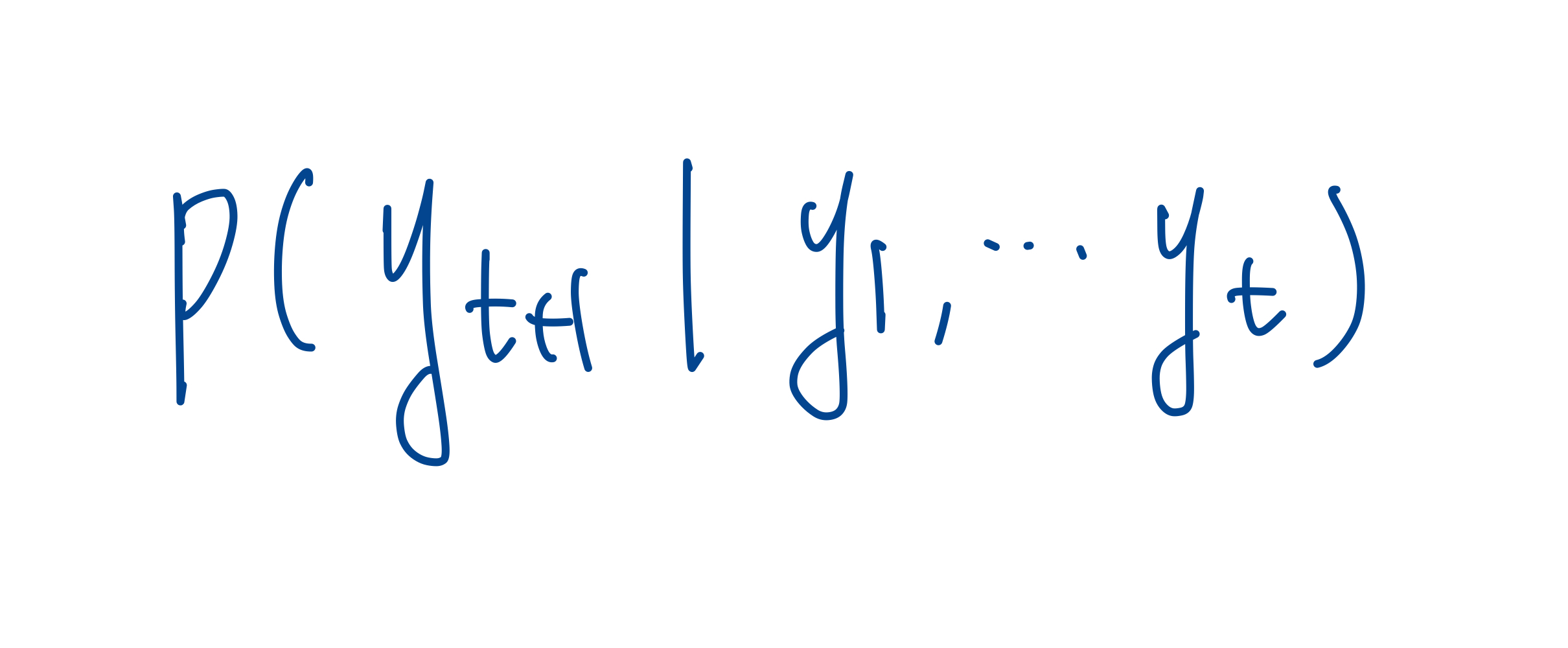
ㅡ
잠깐 사전지식으로, transformer 는 크게 encoder와 decoder로 구성되어 있습니다. 대부분의 유명한 nearul sequence transduction model들은 encoder와 decoder 조합을 구조로 취합니다. 각각의 역할은 무엇일까요?
- encoder : input sequence 'x = (x_1, x_2, ... x_n)' 을 받아 context vector 'z = (z_1, z_2, ... z_n)' 생성
- decoder : z 를 다시 output sequence 'y = (y_1, y_2, ... y_n)' 로 생성
decoder 에서는 이렇게 output sequence 를 출력해야 하는데, output sequence 문장의 각 단어를 순차적으로 (왼쪽에서 오른쪽으로) 예측해나가며 최종 문장을 생성해요.
ㅡ
그렇다면 auto-regressive 방식은 왜 중요할까요? 자연어 생성에서 중요한 것은 문장의 자연스러움 이기 때문에, 새롭게 생성되는 단어가 문장의 context를 잘 반영해야 합니다. 문맥을 점진적으로 확장해 가면서 자연스럽게 문장을 생성하려면, 이전 단어의 예측을 바탕으로 다음 단어를 예측하는 방식이 훨씬 유리할 것입니다. 하지만 순차적인 생성 과정 때문에, 속도가 느리다는 단점이 있습니다.
반대되는 개념으로는, non auto-regressive 가 있습니다. BERT와 같은 LLM의 경우 모든 단어를 한 번에 예측합니다. 병렬처리가 가능하여 속도가 매우 빠르지만, GPT나 Transformer의 decoder 에 비해서는 문맥에는 맞지 않는 단어가 생성될 수 있다는 단점이 있습니다.
ㅡ
아직은 시작 단계여서 다른 논문들을 많이 읽어보진 않았지만, decoder가 token을 생성하는 방식(다음 단어가 등장할 확률을 예측하는 방식) 을 변형시켜가며 정확도와 계산 시간을 얼만큼 잘 tradeoff 하는지가 LLM 성능의 관건이 될 것 같다는 생각이 듭니다. LLM 에서 수행하는 task 들의 종류(번역, 빈칸채우기, 등?) 에는 어떤 것들이 있는지도 찾아봐야겠습니다.
도움이 될 만한 댓글 많이 부탁드립니다! 읽어주셔서 감사합니다.
ㅡ
[1] Attention Is All You Need (Vaswani, 2017): https://arxiv.org/pdf/1706.03762
'은가 > LLM' 카테고리의 다른 글
| [LLM] Transformer :: GPT 쓰긴 싫지만 GPT 안쓰면 도태될까봐 두려운 할미 MZ의 뒤늦은 LLM 공부 (0) Prologue (0) | 2025.02.26 |
|---|