
티스토리 뷰
딩딩기/강화학습 자율주행
[RLHF-Navigation] Feedback-efficient Active Preference Learning for Socially Aware Robot Navigation
딩딩기 2024. 1. 16. 02:50요약
- Hybrid experience buffer를 통해 sample 효율을 증가
- curious exploration과 expert demonstraion 사용
- human feedback을 사용하여 좀 더 자연스러운 주행을 보여줌.
1. Abstract
(1-1) Socially aware robot navigation (SARN)
- SARN이란?
- 로봇이 목표에 도달할 때 충돌이 없도록 하는 것
- 인간과 로봇으로 하여금 편안하도록 하는 것.
- e.g. 로봇이 인간의 경로를 방해하면, 인간은 불편함을 느낌
- e.g. 로봇의 경로가 부드럽지 않으면, 로봇의 모터가 마모되는 등 불안정해짐.
- e.g. 우측 보행이 만연한 집단에 혼자 좌측 보행 하는 사람 → 우리는 불편함을 느낌.
- SARN’s challenging
- 인간과 로봇의 상호작용의 맥락에 대해서는 도전 과제로 남아 있음
(1-2) learning-based methods’ challenging
- 기존 model-based (비학습 기반) 방법론과 비교시에는 월등한 성능을 보여줌
- 그러나 학습 기반 방법론은 아래와 같은 단점을 가지고 있음.
- Reinforcement Learning (RL)
- 로봇의 주행이 질적으로 사회적 편안함을 제공하지 못함.
- 로봇이 reward를 잘못 해석하여 원치 않는 행동을 하게하는 reward exploitation problem 이 존재함.
- 위 문제들은 근본적으로 handcrafted reward에 의존하기 때문임.

- Inverse Reinforcement Learning (IRL)
- IRL의 경우 학습을 위해선 전문가의 demonstrations가 요구가 됨.
- 하지만 이는 현실적으로 많은 양의 데이터를 취득하기 어려움.
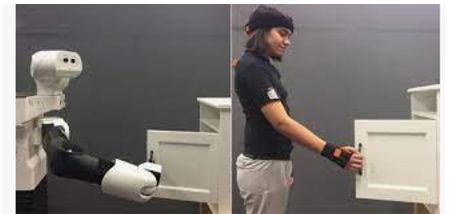
(1-3) Paper propose
- 효율적이고 포괄적인 reward를 위한 방법을 아래의 것을 통해 제안
- human feedback을 통해 로봇 주행의 사회적 편안함 학습
- human feedback data 취득의 효율을 위해 hybrid experience learning을 제안
2. INTRODUCTION
(2-1) Human-robot interaction (HRI)
- AI를 사용한 로봇의 등장은 사람과 로봇이 공존하는 많은 작업에서 성능을 향상 시킴
- e.g. 대학 캠퍼스에서의 배달 로봇, 쇼핑몰 로봇
- 위와 같은 환경들은 일반적으로 사람이 많은 환경임.
- 따라서 사회적 편안함을 제공하는 socially aware navigation이 요구.
- 목표 수행 뿐만 아니라 그 과정 조차 중요함.
- 즉, 사회적 에티켓(etiquette)을 지키는 것도 중요
(2-2) SARN에 대한 선행 연구들
- SARN에 대해서 두 가지의 종류로 나눌 수 있음.
- model-based (비학습 기반)
- 사회적 에티켓과 사람들(군중)의 움직임을 특정 상황에서 특정 수식에 따라서 움직인다고 가정
- 하지만 이러한 방법론들은 움직임 자체가 자연스럽지 않음 (oscillatory trajectory)
- 또한 모든 사람들이 동일한 움직임을 수행한다는 가정이 필요
- learning-based (학습 기반)
- 기본적으로 model-based 보다 좋은 성능을 보여줌
- RL based
- hadncrafted reward를 사용하기 때문에 모든 상황을 대변할 수 없음.
- 기본적으로 RL agent는 reward를 최대화 하는 것을 목표로 하기 때문에 우리가 원하는 action을 하지 않을 가능성이 있음 (reward exploitation)
- IRL based
- RL based와는 반대로 IRL은 reward function을 정의할 필요가 없음.
- 또한 reward exploitation이 존재하지 않는데, 이는 agent가 human demonstrations를 모방하는 것에 집중하여 학습하기 때문
- 하지만 질적인 data를 습득하기 위해선 많은 시간과 노력이 필요
- model-based (비학습 기반)
(2-3) Paper’s methods
- 본 논문에선 Feedback-efficient Active Preference Learning approach (FARL)을 제시
- SARN을 위해서 사용되는 방법
- human feedback을 통해서 reward model을 학습
- curious exploration과 expert demonstration로 구성된 hybrid experience를 통해 human feedback collection 단계의 효율을 증가.
- 특히 expert experiences는 learning process의 시간적 효율을 증가시킴과 동시에 근본적으로 human feedback(선호도)에 만족하는 데이터로 학습에 긍정적 영향을 미
(2-4) Paper’s contributes
- human feedback을 통한 최초의 SARN 방법론
- hybrid experience을 통한 human feedback 향상과 효율적인 sampling
- 실험을 통한 FARL agent의 자연스러운 주행 성능
3. BACKGROUND
(3-1) 선행 연구들
- RL-based
- 기존의 사회적 편안함을 제공하기 위한 SARN의 경우 handcrafted reward function을 아래와 유사하게 agent에게 제공
- 이와 같은 수식은 distance에 크게 의존하게 되는데 단순 distance는 인간의 사회적 편안함을 100% 반영하지 못하는 문제가 있음.
- 또한 reward exploitation으로 인해 agent가 단순히 값이 큰 reward 만을 쫓아 비현실적인 주행이나 부자연스러운 행동을 할 수 있음. 이는 인간에게 사회적 불편함을 제공함.
- e.g. 빈번하게 180도 회전하는 행위

- IRL-based
- 기본적으로 IRL의 방법론은 policy 또는 reward function을 human demonstration을 통해 학습
- 이러한 것을 “human in loop learning” 이라고 부름
- IRL에게 expert data를 제공함으로 로봇이 자연스러운 SARN을 가능케 함.
- 하지만 현실적으로 expert data를 취득하기란 비용적, 시간적 측면에서 비효율적
- 추가적으로 SARN에 맞는 expert data를 취득하는 것은 더 어려움
- Active preference or feedback learning
- 본 방법은 human feedback을 human demonstration 대신에 agent에게 제공하는 방법
- 이를 통해서 IRL보다 상대적으로 교정 가능하고 적응 가능한 정보를 제시함과 동시에 expert data가 필요 없음 (vs IRL)
- 본 방법의 장점은 구체적인 reward function이 필요 없으며, reward exploitation이 존재하지 않음. (vs RL)
- 물론 좋은 성능을 이끌어 내기 위해선 충분히 빈번한 human feedback이 요구됨
(3-2) FAPL이 제시하는 것
- 다음과 같은 방법으로 인간의 편안함과 기대를 reward model로 나타낼 수 있고 이를 로봇의 Policy로 나타낼 수 있음
- hybrid experience learning:
- feedback 효율을 위해서 사용
- 이를 통해 active reward learning 과정에 중요 feedback을 제공 가능
- reward model
- RL 방법과는 반대로 reward model은 인간의 선호도에서 부터 기인함. (이는 handcrafeted 방법과는 다름)
- 이러한 방법은 인간의 선호도를 반영한 reward 를 제공할 수 있으며, 동시에 reward exploitation 을 피할 수 있음
- expert intelligence
- IRL 방법과는 다르게, expert data에 대해 비용적, 데이터의 질적, 데이터의 다양성에 대한 문제가 없음
- hybrid experience learning:
(3-3) Problem Formulation
- Partially Observable Markov Decision Process (POMDP)
- $n^{th}$: timestep t에서 관측 가능한 사람 수
- $h_t^n$: 로봇이 관측한 n명이 가지고 있는 각각의 상태 정보
- position $(p^n_x,p^n_y): n^{th}$ 에 해당하는 사람 위치 정보
- angle $\beta_h: n^{th}$에 해당하는 사람의 각도
- 본 연구에서는 sim-to-real tranfer를 고려하여 사람의 속도나 크기를 관측할 수 없는 정보로 취급
- $w_t$: 로봇 상태 정보
- position $(p_x,p_y)$: 로봇의 현재 위치
- velocity $(v_x,v_y)$: 로봇의 현재 속도
- max/min velocity ($v_{max},v_{min}$): 로봇의 최대, 최소 속도
- radius $ρ$: 로봇의 크기
- angle $\beta_r$ :로봇의 heading 각도
- goal position $(g_x,g_y)$: 로봇의 목표 위치
- Joint state $s_t^{jnt} = [w_t,h_t^1,…,h_t^n]$: 로봇에게 주어지는 최종 state
- policy $\pi(a_t|s_t)$ : 로봇이 각 timestep 마다 action $a_t$을 할 확률
- transition probability $P(. |s_t,a_t)$: 다음 state로 넘아갈 확률
- reward $r_t$: timestep t에 환경으로부터 제공받는 reward
- discount factor $\gamma$: 미래 보상에 대한 감가율
(3-4) Soft Actor-Critic Training Framework
- DRL algorithm으로 SAC 사용 (자세한 것은 링크 참고)
4. APPROACH
(4-1) Denote
- reward function $\hat R_\mu$ : social compliance-embedded reward function
- Q-function $Q_\theta$
- policy $\pi_ϕ$
(4-2) Update step
- 다음 단계를 따라서 update 됨.
- Expert Demonstration
- 사람으로 구성된 전문가 제시하는 SARN demonstrations을 통해 experience replay buffer EB를 초기화.
- expert experiences: ($s_t,a_{expert},s_{t+1}$)
- 자세한 내용은 (4-3)절
- Curious Exploration
- 사전 학습된 policy $\pi_ϕ$ 을 state-entropy-based reward가 최대화 되도록 학습
- 이는 curious exploration와 다양한 samples를 얻기 위함
- 이러한 sample ($s_t,a_{exploration},s_{t+1}$)들은 buffer EB에 exploration experiences로써 저장됨.
- 동시에 temporary buffer B는 초기 훈련 과정에서 생성된 비일관적인 sample을 temporary experiences으로 저장
- 자세한 내용은 (4-3)절
- 사전 학습된 policy $\pi_ϕ$ 을 state-entropy-based reward가 최대화 되도록 학습
- Active Reward Learning
- $\hat R_\mu$ 는 인간의 불편함과 지식을 나타냄
- $\hat R_\mu$ 는 active preference learning을 통해 human feedback으로부터 학습됨.
- EB와 B에 있는 samples는 새로운 $\hat R_\mu$ 를 통해 새로운 reward value를 update.
- 자세한 내용은 (4-4)절
- Off-policy Learning
- $Q_\theta$ 와 $\pi_ϕ$는 SAC와 $\hat R_\mu$가 제시하는 reward를 토대로 return이 최대화 되는 방향으로 update
- 자세한 내용은 (4-5)절
(4-3) Hybrid Experience Learning
- Active preference learning과 문제점
- 초기화된 agent는 random policy를 따르며 환경과 상호 작용함
- 이러한 상호작용을 통해서 인간의 feedback을 위한 sample (state, reward)를 얻음
- 하지만 random policy는 state에 대한 비일관된 action을 제공하기 때문에, 인간이 feedback하기 어렵게 만듬
- 이러한 문제를 해결하기 위해서 curious exploration과 expert demonstration으로 구성된 hybrid experience 제안
- 초기화된 agent는 random policy를 따르며 환경과 상호 작용함
- Curious exploration
- curious exploration에서는 agent에게 state를 충분히 탐험할 수 있도록 자극하여, 초기 reward function에서 채택된 k-NN 기반 state entropy estimator를 사용하여 더 나은 state coverage를 제공
- $H_{state}(s):= \sum \log (p+\frac{1}{k} \sum || s_t -s_t^{(k)}||)$
- $H_{state}(s)$: state entropy esimator. state distribution의 희소성(sparsity)와 무작위성(randomness)를 위 수식을 통해 평가.
- $p$: 수치적 안정성을 위한 parameter (일반적으로 1로 고정). 즉,$\sum ||s_t - s_t^{(k)}|| =0$ 인 경우를 $\log$$( 0)$이 되는 것을 막기 위해 존재
- $s_t^{(k)}$: state space에서 $s_t$의 k-neighbors
- $\frac{1}{k} \sum ||s_t - s_t^{(k)}|| ≥ 0$: 각 state와 그들의 $K^{th}$ 번째 가까운 이웃들의 거리(distance)를 의미함.
- entropy인데 $-$ 가 없는 이유: $p$의 존재로 인해 $\log$ 내부의 값은 항상 1보다 큼.
- $H_{state}(s)$ 가 크면, state와 그들의 이웃간의 거리가 먼것을 의미하며, state space의 randomness와 sparsity가 강하다를 나타냄.
- $H_{state}(s):= \sum \log (p+\frac{1}{k} \sum || s_t -s_t^{(k)}||)$
- 초기 exploration reward는 아래와 같음
- $R_{explorations}(s_t):= \log (p+\frac{1}{k} \sum || s_t -s_t^{(k)}||)$
- 해당 state $s_t$의 randomness와 sparsity가 크면 reward 값이 크므로 더 적극적으로 agent는 exploration 하게 됨
- object function은 아래와 같음
- $ϕ^⋆_{\pi_ϕ} = \argmax_ϕ \sum R_{exploration} (s_t)$
- $ϕ$는 policy $\pi_ϕ$의 weight
- agent의 목적이 return을 최대화 하는 것을 그대로 반영
- curious exploration에서는 agent에게 state를 충분히 탐험할 수 있도록 자극하여, 초기 reward function에서 채택된 k-NN 기반 state entropy estimator를 사용하여 더 나은 state coverage를 제공
- object function $ϕ^⋆_{\pi_ϕ}$를 최대화 하는 방법
- 초기 policy $\pi _ϕ$를 통해서 agent가 다양한 state를 경험하며 학습할 수 있도록 함.
- 하지만 이때 SARN은 기본적으로 로봇의 목표지점에 충돌없이 도달해야 할 뿐만 아니라 사회적 에티켓을 지키며 주행해야함.
- 이러한 사회적 에티켓 정보는 state에 숨겨져 있기 때문에 agent가 직접적으로 발견하기 힘듬. (e.g. 우리가 일본에 간다면 일본의 사회적 에티켓을 한눈에 판단하기 힘들듯이)
- 위와 같은 이유로 SARN을 이해한 policy를 학습하려면, 많은 량의 human feedback이 요구가 됨.
- 이를 해결하기 위해서 human demonstrations를 사용
- 이를 통해서 인간은 선호도를 human demonstrations를 기반으로 평가할 수 있으며, 더 쉽게 중요 feedback을 agent에게 제공할 수 있음.
- human demonstration에 대해서
- 부정확한 demonstrations의 영향을 피하기 위해서 replay buffer EB에는 오직 $(s_t,a_{expert},s_{t+1})$의 값만 저장 (이는 기존 IRL과는 차이점)
- 이를 통해 expert demonstrations data에 대해서도 선호도를 평가할 수 있게 됨.
- 이는 곳 noise가 배제된 좋은 demonstration data를 취득할 수 있음을 의미
위의 내용은 아래의 pseudocode로 나타냄

(4-4) Active Reward Learning
- active reward learning의 목적은 SARN을 위한 인간의 선호도와 기대를 반영한 reward function $\hat R_\mu$을 학습하는 것 (여기서 $\mu$는 neural network의 weight)
- 지난 번 리뷰했던 내용과 동일하게 2 개의 trajectory segments를 인간에게 제공하여 어느 segment가 더 선호되는지 판별하게 함.
- 먼저 experience replay buffer EB에 있는 agent의 trajectory 들을 몇가지의 segment $\sigma$ 로 분리
- $Υ$는 인간의 선호도를 나타내며 2 개의 trajectory segments에 대해 (1,0),(0,1) 또는 (0.5,0.5)로 나타냄
- segments에 대한 결과를 database $D$ $(\sigma_1,sigma_2, Υ)$로 저장
- 선호도 예측자 $P_\mu$ 는 reward model $\hat R_\mu$를 학습하기 위해서 아래와 같이 제작됨.
- $P_\mu [\sigma_1>\sigma_2] = \frac{\exp \sum \hat R_\mu (s^1_t,a^1_t)} {\exp \sum \hat R_\mu (s^1_t,a^1_t) + \exp \sum \hat R_\mu (s^2_t,a^2_t)}$
- 수식에 대한 자세한 내용은 지난 번 리뷰 참고
- reward model 최적화는 아래와 같음
- 목적은 cross-entropy loss를 통해 \hat R_\mu 값을 최소화하는 것
- $L(\hat R_\mu)=−∑Υ(1)\log P_\mu[σ_1>σ_2]+Υ(2)\log P_\mu[σ_2>σ_1]$
- 여기서 추가적으로 uncertainty-based query selection method를 사용함으로 feedback 받지 못한 행동들에 대해서 불확실성을 줄이고 유익한 feedback을 받도록 함.
(4-5) Off-policy learning
- sample의 효율을 위해 off-policy RL인 SAC를 선택
- 하지만 on-policy와 비교했을 때, reward model \hat R_\mu 사용시 불안정한 수렴성을 보여줌.
- 이는 policy 학습중에 비동기적으로 reward function이 항상 update 되기 때문이며, off-policy RL이 replay buffer 안에 있는 부정확한 reward 값을 지속해서 재 사용하기 때문임.
- 위와 같은 문제를 해결하기 위해서 expert demonstration buffer EB와 exploration buffer B를 매번 새로운 reward model이 update 될때마다 update 함.
- 이때 B의 일시적인 experience는 EB로 전이
- 그런 다음, exploration 을 통해 얻은 $Q_{\theta}$와 pre-trained $\pi_ϕ$는 최적화를 위해 EB에서 update된 sample과 결합된 보상 모델 $\hat R_\mu$에 의존하게 함
- 하지만 on-policy와 비교했을 때, reward model \hat R_\mu 사용시 불안정한 수렴성을 보여줌.


(4-6) Implementation Details
- pretrain policy $\pi_ϕ$ (curious exploration)
- episodes 3,000
- 첫 번째 samples은 초기 1,000개의 episodes B에 저장
- 나머지 2,000개는 EB에 저장
- expert demonstration
- keyboard를 통해 로봇의 속도를 조절하여 취득
- 500개의 episode
- 로봇이 해당 목표 지점에 도달해야 demonstration 종료
- reward model
- 3-layer: 265 hidden units
- activation function : Leaky ReLUs
- segment 1개: (state, action) 쌍 총 35개. 이는 15sec 분량
- 10명의 전문가 평가자를 통해 feedback 데이터 1,500개 취득
5. Experiments and Results
(5-1) 환경 구성
- 아래와 같은 그림으로 환경 구성
- 빨간색은 scan 범위 밖 사람(관측 x), 초록색은 scan 범위 안 사람(관측 o)
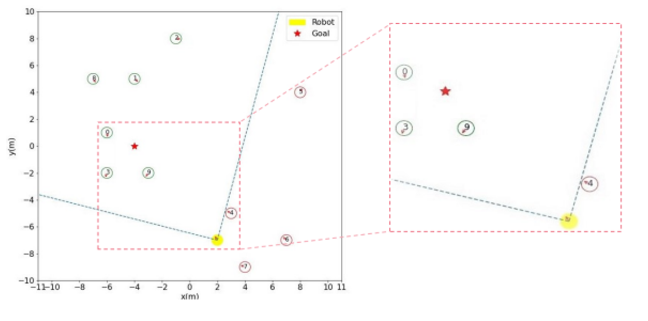
(5-2) 비교 알고리즘
- CADRL (ORCA를 통한 사전학습을 활용한 알고리즘)
- SARL (CADRL + Attention Mechanism)
- RGL (CADRL + Graph Nerual Network)
- APL: hybrid experience learning 없이 (feedback 효율 평가를 위해 구성)
- FAPL: 본 논문에서 제시하는 방법
- 실험 방법
- 환경에 보행자 5, 10, 15 명으로 구성
- 보행자 수에 따라 epsiode 최대 시간 30,35,40 sec으로 구성
- 500회의 Test
- discomfort frequency: 로봇과 사람이 일정 거리 내에 있는 횟수(논문에선 0.3m로 설정). 즉, 충돌 가능성이 높거나 사회적 불편함을 야기했다고 판단
- 환경에 보행자 5, 10, 15 명으로 구성
(5-3) 결과 및 분석 1
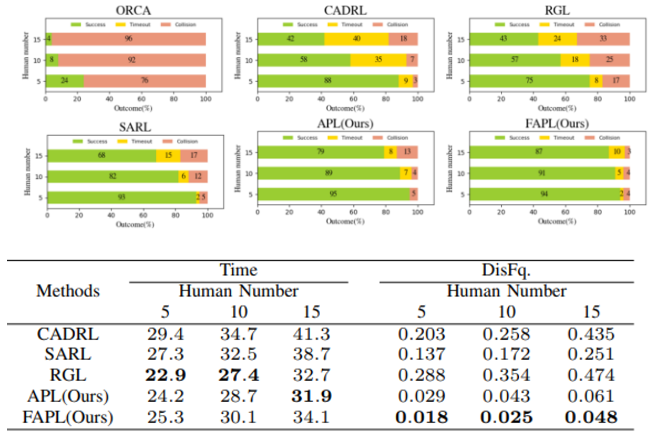
- RGL이 빠른시간 내에 목표지점에 도달했지만, DisFq의 횟수가 많은 것을 확인할 수 있음.
- 즉, 해당 로봇이 공격적으로 주행을 시도했음을 의미
- 사람이 불편함을 느낌
- FAPL은 CADRL, SARL과 비교시 상대적으로 짧은 시간을 보여주며 전체적으로 DisFq가 낮은 횟수를 보여줌.
- 이는 로봇이 과도한 우회나 모든 보행자가 지나갈 때까지 기다리지 않았다는 것을 의미함.
(5-4) Real-world Experiment
- simulator 만으로는 discomfort frequency를 확실하게 판단하기 어려움.
- 따라서 실제 환경에서 실험을 진행함.
- 보행자: 18세 이상으로 여성 2, 남성 8명으로 구성
- 보행자는 로봇이 어떤 알고리즘인지 모름
- 총 18개의 test 진행 (각 알고리즘 당 6회 실시)
- 보행자는 어떠한 요구사항 없이 자연스럽게 움직이도록 함.
- 단 이때 두가지의 그룹으로 나누어 실험 실시 (5-5)절 참고
- 각 test가 끝날 때 마다, 보행자들에게 불편함과 로봇의 주행이 자연스러운지 물어봄으로써 Likert Scale를 제작.
- 1은 매우 동의하지 않음, 5는 매우 동의함의 척도를 사용
(5-5) 결과 및 분석 2

- 두가지의 그룹으로 나눔
- 근거리 상호 작용 참가자 (CI)
- CI는 실험 중 로봇에 0.6m 이상으로 접근하여 2초 이상 근접한 보행자
- 비근거리 상호 작용 참가자 (NCI)
- NCI는 그렇지 않은 보행자
- 근거리 상호 작용 참가자 (CI)
- 양적 측정
- 편안함
- CI 입장에선 FAPL이 가장 편안
- NCI는 근접하여 로봇의 행동을 경험하지 못했기 때문에 FAPL이 높은 점수를 얻지 못함.
- NCI는 3가지 모델 모두에게 중간 점수를 주는 경향이 있었음
- 자연스러움
- NCI가 자연스러움에 대해서 평가가 명확한 이유는 로봇이 부자연스러운 행동(e.g. 갑자기 정지)이 NCI의 주의를 끄는 소음과 함께 발생했기 때문
- 편안함
- 질적 측정
- 각 test 후 참가자들에게 모두 개방형 면담 질문을 줌
- Long-sighted Decision
- FAPL의 로봇 행동이 보행자들에게 선호되는 이유 중 하나는 더 장기적인 판단을 내리기 때문
- expert demon과 feedback을 통해 로봇에 인간의 지성과 통찰력을 도입한 것으로 해석.
- 실험 경험자의 말 1: 내가 그중 하나(FAPL)를 좋아하는 이유는 내가 가까워지기 전에 충분한 공간을 나줘줘서 이다.
- 실험 경험자의 말 2: 세 번째 로봇(FAPL)이 처음에는 바로 중심에 직접 관여하는 대신에 왼쪽으로 돌아서 우회했기 때문이다.
- FAPL의 로봇 행동이 보행자들에게 선호되는 이유 중 하나는 더 장기적인 판단을 내리기 때문
- Behavior Naturalness
- FAPL이 선호되는 또 다른 이유는 더 자연스러운 행동을 유도하기 때문 (e.g. 갑자기 좌우로 빈번하게 꺽는 행위 없음)
- 이는 expert demon과 feedback을 통해서 reward exploitation이 존재하지 않았기 때문
- 실험 경험자의 말 1: 두 번째 것(SARL)은 항상 즉시 멈추었고, 첫 번째 것 (APL)도 가끔 그랬었다.
- 실험 경험자의 말 2: 마지막 로봇(FAPL)이 좀 더 인간처럼 움직였다. 즉, 거의 갑자기 멈추지 않고 자주 돌아가지 않았다.
- FAPL이 선호되는 또 다른 이유는 더 자연스러운 행동을 유도하기 때문 (e.g. 갑자기 좌우로 빈번하게 꺽는 행위 없음)
6. CONCLUSION
- 해당 연구를 통해서 FAPL를 제시
- 본 연구는 simulation과 real env를 통해 실험을 진행하였으며, 해당 방법론이 인간으로 하여금 자연스러우며 편안하게 하는 것에 대해 SOTA(state-of-the-art)라는 걸 보여줌.
- 또한 hybrid experience learning을 통해 human feedback의 효율이 증가할 수 있음을 보여줌.
댓글