
티스토리 뷰
editor, Seungeon Baek
Reinforcement learning Researcher / RL, GNN, Causal Inference
클릭해 주셔서 감사합니다.
GNN 논문 리뷰 연재 첫 번째 글 입니다.
현생에 밀려, 2022년엔 글을 거의 쓰지 못 하다보니, 팀블로그 활동을 함에 있어서 팀원들에게 미안한 마음이 드는 것이 사실인 것 같습니다. 그리하여, 이번 달 부터라도 글을 열심히 써보고자 합니다!
최근 들어, 강화학습과 더불어서 Graph Neural Network에도 많은 관심을 가지고 있습니다. 현재 오프라인 스터디를 주선하여 논문 스터디를 할 정도로, 진지하게 공부를 하고 있답니다.. (진지) 물론, 현재 맡은 직무와도 어느정도 관련도 있구요...ㅎ 어쨌든!
본론으로 돌아와, 이번 논문 리뷰글은 Graph LSTM이라고 하는, 특히 vision task에서, 기존의 sequential한 데이터만 다룰 수 있던 LSTM 구조를 Graph structure로 일반화한 Graph LSTM에 대한 내용으로 이루어져 있습니다. Graph LSTM의 컨셉을 간단히 말씀 드리면, "이웃 정보를 선택적으로 활용(학습)할 수 있는 LSTM" 이라고 할 수 있을 것 같습니다.
그럼, 본격적인 리뷰 시작하겠습니다!

논문의 제목은 굉장히 task specific합니다. Semantic object parsing이라는 특정 태스크를 타겟으로, 그 태스크를 잘 해결하기 위해 Graph LSTM이 제안되었다는 느낌이 슬슬 옵니다. 원래는, spatio-temporal 즉, 시공간 데이터를 임베딩 할 수 있는 Graph Neural Network 알고리즘이라고 생각하고 논문을 골랐는데, 잘못 골라 버렸습니다ㅠ. 그래도 수준 있는 비전 논문을 처음 읽어 봤는데, 좋은 경험이었던 것 같습니다.

목차는 다음과 같습니다.
가장 먼저, 도입부에서는, 저자들이 해결하고자 한 task인 semantic object parsing이라고 하는 task가 어떤 것인지에 대해 먼저 말씀 드리고자 합니다. 논문을 이해하고자 함에 있어, 중요한 부분일 뿐만 아니라, 제가 잘 모르는 분야이기에 따로 준비를 했습니다. 그 다음, image processing 분야에서 기존의 LSTM들이 성능을 내기 위해 어떤 방식으로 적용되어 왔는지에 대해서도 설명을 드리고자 합니다.
그 후, 본론에서는, Graph LSTM을 더욱 잘 이해하기 위한 배경에 대해 설명 드리고, 방법론에 대해서 논문에서 설명한 순서대로, 설명을 진행하도록 하겠습니다.
마지막으로, 실험 결과 부분에서는, Graph LSTM 논문에서 해당 task를 위해 사용된 데이터 셋에 대한 설명과, 실험 결과, 그리고 저자들이 수행한 ablation study에 대해서도 공유 드리고, 발표를 마무리 짓겠습니다.

가장 먼저, 도입부입니다. 도입부에서는 Semantic object parsing task와, LSTM on imagae processing에 대해서 말씀드리겠습니다.

Semantic object parsing이란, 특정 object를, 몇몇 의미를 가진 부분들(semantic parts)로 분할 하는 태스크를 의미합니다. 저도 정확한 정의를 알지는 못 하지만, 기존의 vision task에서 이미 많이 연구되던, semantic segmentation과의 다른 점은, semantic object parsing이 조금 더 디테일한 분할에 초점을 맞춘 태스크인 것 같습니다.
- 이에 대해 초점을 맞추어 자세히 설명 드리면, 오른쪽 위의 두 번째 사진에서, semantic segmentation task는 image를 {벽, 바닥, 여자} 이렇게 큼직하게 의미론적으로 픽셀들을 분할 하는 태스크를 해결한다면, semantic object parsing task의 경우, {여자가 어떤 옷을 입었고, 여자의 머리와 팔을 이루고 있는 픽셀들은 어디인지}를 분할하는 태스크인 것 같습니다.
저자들은, 이러한 semantic object parsing task의 경우, computer에게 imgae의 자세한 내용을 이해할 수 있게 해주는 task이기 때문에 중요하다고 언급을 하고 있습니다. 또한, 이러한 task가 성공적으로 이루어질 경우, image-to-caption generation, person re-identification, human behavior anaysis와 같은 downstream task or high level application에게도 큰 도움을 줄 수 있다며, 해당 태스크의 중요성을 설명했습니다.
- imagae-to-caption generation: 여자가 벽 앞에서, 드레스와 선글라스를 낀 채, 서있다.
- person re-identification: 빨간색 셔츠와 백팩, 파란 바지를 입고 있던 남자가 근처 카메라에서 다시 발견 되었을 경우, 그 둘을 동일한 인물로써 인식
- human behavior analysis: 특정 인물이 camera 앞에서 오른 팔을 머리 위로, 좌 우로 흔들고 있는 것을 인식
그런데, vision-task에서 큰 성공을 얻어온, CNN 기반의 모델들은, 해당 task에서 제한된 성능을 보여주곤 했다고 합니다. 저자들은 그 이유에 대해서 다음과 같은 점을 지적합니다.
- CNN 기반의 모델들은 제한된 neighboring context로부터, 지역적인 정보만을 빌려와 학습이 수행된다. (convolutional filter의 한계 지적)
- 직관적으로, imaga 내에서, 각 semantic part를 인식하는데에 있어서, critical cue들은 lager local context와 global perspective이며, CNN은 이를 다룰 수 없다.
그리하여, 이러한 단점을 극복하기 위해, 이전의 연구자들은 imaga에 LSTM 기반의 모델들을 적용하는 연구를 수행하여 semantic object parsing 태스크를 해결해 왔다고 언급합니다. 자연스레 다음 장으로...

저자들의 언급에 따르면, LSTM 기반의 모델들은 semantic object parsing task에 적용될만한 능력을 가지고 있다고 합니다. LSTM 기반 모델들은 sequential data를 처리하기 위해, memory cell들을 사용하며, 그 뿐만 아니라, "spatial dimension을 따라 image를 순차적으로 처리할 수 있다"라고 언급합니다.
그리하여, 저자들은 이를 위해 제안되었던 LSTM 기반의 variation들에 대해서 소개해줍니다.
- Grid LSTM: Grid LSTM의 경우, 이미지 내에서 horizontal 방향으로, 순차적으로만 memory cell, hidden states가 전파되던 LSTM의 구조를, vertical 방향으로도 해당 정보들이 전파되게끔 수정한 알고리즘이며, 그렇기에 Grid LSTM이라고 하는 이름을 붙인 알고리즘입니다.
- Row LSTM, Diagonal Bi-LSTM: Row LSTM의 경우, 이미지 내에서, 특정 pixel에 대응되는 hidden states를 업데이트 함에 있어, 이전 Row pixels혹은 Diagonal pixels을 종합하여 hidden states들이 업데이트 될 수 있도록 DeepMind에서 제안한 알고리즘입니다. 그리하여, 이미지 내에서 scene understanding과 같은 태스크에 있어서 CNN 기반의 모델들 보다 더욱 좋은 성능을 낸 것으로 보고 되었습니다.
- Local-Global LSTM: Local-Global LSTM, 줄여서 LG LSTM의 경우, 앞선 알고리즘 보다 더욱 좁은 topology를 다루긴 하지만, LSTM 구조 내에서, 특정 pixel의 hidden state를 업데이트 함에 있어, 자신의 feature, memory cell, hidden states정보(local) 뿐만 아니라, 주변의 정보(gloabl)를 종합하여 업데이트 하는 방식으로 수정된 알고리즘입니다. 해당 모델은 semantic object parsing task에서 이 논문 이전에 가장 좋은 성능을 보였다고 합니다. (Graph LSTM 저자와 동일한 저자입니다. ㅎㅎ)
도입부에서 준비한 내용은 여기까지이며, 지금부터는 Graph LSTM에 대해서 본격적인 소개 및 설명을 수행할 수 있도록 하겠습니다!

Graph LSTM에 대한 내용은 먼저 연구 배경에 대해서 말씀 드리고, 방법론에 대해서 길게 설명 드리는 구조로 되어 있습니다. 재미있게 읽어주세요 :)

저자들은 해당 연구의 배경으로 두 가지를 얘기하고 있습니다. 먼저, traditional semantic segmentation을 넘어서, semantic object parsing이라는 태스크가 중요해지고 있으며, 해당 태스크는 image를 조금 더 fine-grained semantic을 얻을 수 있는 multiple parts로 분할하는 것을 목적으로 두고 있다고 합니다.
- (해당 task에서 CNN 기반 모델들은 제한된 성능을 내왔다, 그이유는 어떻다는 도입부의 반복.. 생략할게요!)
- 또한, 해당 task에서 기존의 LSTM 기반의 모델들은 promising resulte들을 만들어 내 왔지만, 이들에겐 정보 전달의 측면에서, 기 정의된, 고정된 위상만을 탐험할 수 있다는 단점을 가지고 있었다고 합니다.
그리하여, 저자들은 기존의 sequential and multi-dimensional data를 다루던 기존의 LSTM 기반 모델들을 general graph-structure data를 처리할 수 있도록 확장된, Graph LSTM을 제안했다고 합니다.
- 해당 모델에서 graph는 arbitrary-shpaed superpixel을 graph의 node로, superpixel간의 spatial neighborhood relation을 grpah의 edge로 해석하여 2D image위에서 구축 되었으며, Graph LSTM은 이러한 그래프 데이터를 처리함으로써 pixel들 사이의 관계를 capture할 수 있다고 저자들은 얘기하고 있습니다.
마지막에 너무 뚱딴지 같은 소리가 나왔지만, 앞으로 천천히 풀어서 설명 드릴 예정이니 뒤로가기를 누르지 말아주세요!
다음 장 부터는, 해당 논문에서 제안한 알고리즘의 방법론에 대해서 차근차근 설명드리도록 하겠습니다.

방법론에 대해서 자세히 설명드리기 이전에, 먼저 Graph LSTM이 semantic object parsing task를 해결함에 있어 어떤 역할을 하는지, 전체 네트워크 구조와 함께 설명을 드려야 할 것 같습니다.
Graph LSTM의 경우, image를 입력 받아, 해당 image의 pixel들이 어떤 의미론적 의미를 가지고 있는지 mapping해주는 오른쪽 아래의 전체 그래프 상에서, 추출된 visual feature들에 global structure context에 대한 이해도를 향상시켜주는 역할을 하고 있습니다. 즉, 단일 모델로써 역할을 하는 친구는 아닙니다.
그리하여, 이 장에서는 먼저, Graph LSTM을 포함하는 전체 네트워크의 연산 단계를 하나씩 설명 드리겠습니다.
- Input image는 stakc of convolutional layer를 거쳐, convolutional feature map을 뽑아 냅니다. 사진 상에서의 deep connect 부분이 convolutional layers입니다.
- 해당 feature들은 특정 CNN based model을 거쳐 confidence map으로 변환됩니다. 이 confidence map은 해당 pixel이 어떤 label로 mapping이 되는지에 대한 확률 중 가장 큰 값을 가진 map으로 저는 이해 했습니다. 논문에서는 자세한 설명이 수행되진 않았습니다. 그림에서 deep connect 이후 윗 분기의 내용입니다.
- 또한, input image는 SLIC라고 하는 알고리즘을 통해서, superpixel map으로 변환 되기도 합니다. (왼쪽 아래 그림) 이 superpixel map은 추후 Graph LSTM layer에서 사용됩니다.
- Graph LSTM layer에서는 해당 superpixel map을 graph로 간주하고, 앞서 계산된 confidence map을 이용해, graph의 node(LSTM unit)들의 업데이트 순서를 정해줍니다. (기존의 순차적으로 업데이트 되던 LSTM과 큰 차이 점 중 하나입니다.)
- 이후, 논문에서 제안된 LSTM unit들의 hidden states, memory cell의 update 수식에 따라, 각각이 업데이트 됩니다.
- 또한, 앞서 계산된 Convolutional feature들은 residual connection을 이용해, Graph LSTM의 연결 사이, 연결 후 에도 정보를 전달해 줍니다.
- Graph LSTM layer에서는 해당 superpixel map을 graph로 간주하고, 앞서 계산된 confidence map을 이용해, graph의 node(LSTM unit)들의 업데이트 순서를 정해줍니다. (기존의 순차적으로 업데이트 되던 LSTM과 큰 차이 점 중 하나입니다.)
이번 장에서 설명드린 큰 그림에서는 생략된 내용이 너무 많아, 복잡한 감이 있지만, 추후 설명드릴 내용을 통해 하나씩 이해가 되시면, 저자들의 똑똑한 아이디어가 이해가 가시리라 생각됩니다!

이 장에서는, 그러면 superpixel map이 어떻게 graph로 간주될 수 있는지에 대한 엔지니어링 내용에 대해서 설명 드리고자 합니다.
먼저 저자들은, (1) 특정 알고리즘을 통해 얻은 image의 superpixel map 내에서, 하나의 superpixel을 하나의 node로 간주 하였습니다. (2) 또한, node feature의 경우, superpixel내의 pixel들의 feature들의 평균으로써 이용했습니다. (3) 마지막으로, 실제 superpixel간의 relation 정보를 graph 상에서의 undirected edge로써 간주함으로써, superpixel map을 superpixel graph G로써 간주 하였습니다.
이렇게 구축된 그래프는, 오른쪽 아래 그림 처럼, Graph LSTM을 거쳐서 local - global context 정보를 convolutional feature에 더해주는데 사용이 되었다고 합니다.

그런데, SLIC알고리즘을 통해서 만들어진 superpixel map은 기존의 fixed topology를 가지는 image와 다르게, arbitrary topology를 가질 수 밖에 없다는 문제가 발생했습니다. 그리하여, 기존의 fixed topology를 이용해서 순차적으로 업데이트 되던 LSTM 기반의 모델들과 달리(왼쪽 아래 그림), 해당 모델은 node update 순서를 직접 정해주어야 할 필요성이 존재했습니다.
이에 대해, 저자들은 기존의 graph를 순회하는 알고리즘인 BFS, DFS등에 의존한 것이 아니라, confidence-driven update scheme을 적용하는 것을 제안합니다. 해당 전략은, 기 계산된 confidence map을 기반으로, 신뢰도가 높은 superpixel부터 node의 업데이트를 하는 전략입니다.
- 이 전략에 대해 저자들은, higher confidence score를 지닌 node들의 visual feature를 messga passing 하는 것이 더욱 reliable하기 때문이라고 서술하고 있었습니다.
- 또한, 같은 confidence score를 가진 node들이 충돌할 경우가 발생할 수 있고, 이때는 이전의 node와 가까운 node부터 업데이트 하는 방식을 사용 했다고 합니다.
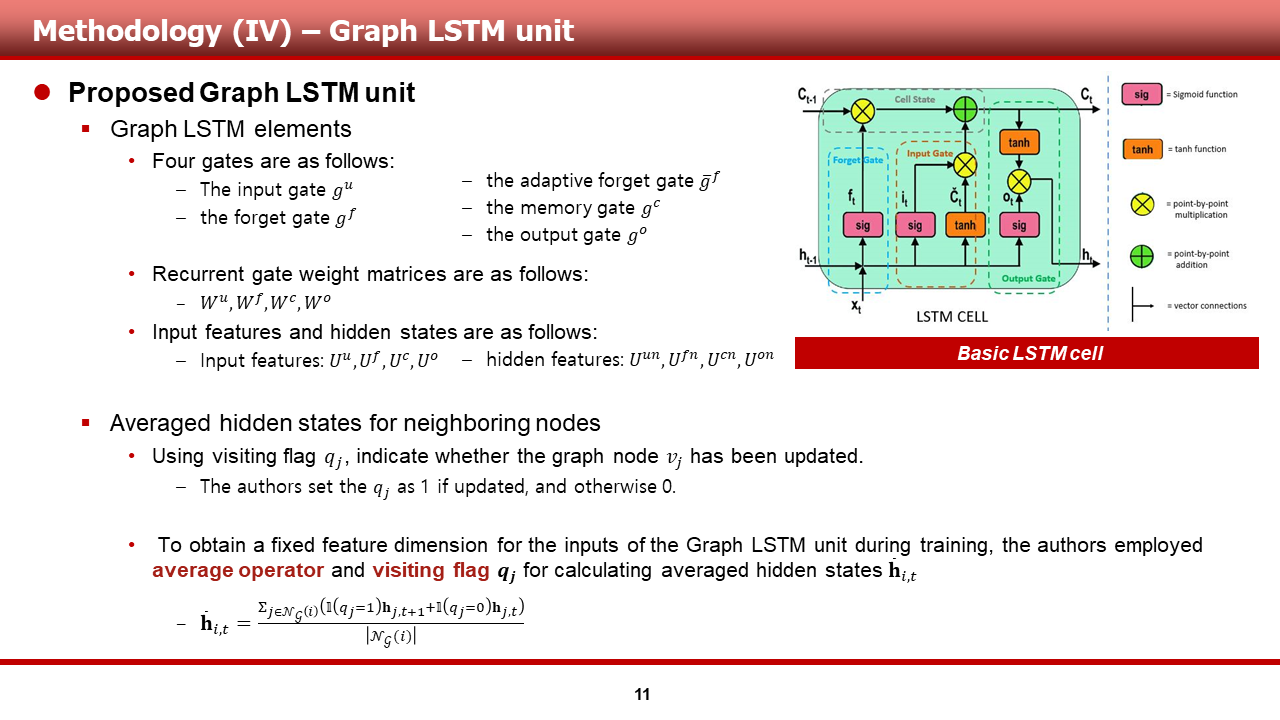
이 장 까지는, Graph LSTM layer관점에서 설명이 이루어 졌다면, 이 장 부터는, Graph LSTM unit과, 해당 모델의 수식에 대해서 자세히 설명 드리도록 하겠습니다.
가장 먼저, Graph LSTM elements의 경우, 기존의 LSTM element와 거의 유사하다는 것을 LSTM의 그림과 슬라이드내 적어진 사항들을 보시면 알 수 있습니다. (notation 같은 경우는 조금 다를 수 있습니다.)
- 하나 다른 점이 있다면, Graph LSTM의 경우, 단일 forget gate를 사용하는 것이 아닌, adaptive forget gate bar_g^f를 사용하는 것을 확인할 수 있습니다.
- 또한, gate별로 매칭되는 weight matrix와, input featre, hidden feature들에 대한 notation matching도 슬라이드내에 이뤄져 있습니다.
또한, 하나의 단일 unit에서 정보를 받던 기존의 LSTM과 달리, Graph LSTM은 도입부에서 설명한 image를 위한 LSTM 모델들처럼, 여러 neighboring nodes로부터 hidden states를 받습니다. 그 상황에 있어, Graph LSTM은 기존의 모델들에서 발생하지 않던, 다음과 같은 문제가 발생합니다.
- 내 hidden states를 업데이트 하기 위해 모은 주변 노드들의 hidden states가 과연 업데이트가 된 값인가? 아니면 이전의 값인가?
이를 판단하기 위해, 저자들은 각 노드별로 visiting flag q_i를 도입합니다. 그리하여, update를 하면 flag를 1로, update 하지 않으면 flag를 0으로 지정하여, 이 flag값을 hidden states, memory cell을 업데이트 함에 있어서 활용합니다.

이 장에서는, 이전 장에서 언급했던 adaptive forget gates와, 전체적인 업데이트를 위한 수식에 대해서 말씀 드리겠습니다.
먼저, adaptive forget gates의 경우, node i의 hidden states를 업데이트 할 때, 주변의 이웃 노드 정보(node j들의 hidden states)를 사용함에 있어, 해당 hidden state(j)의 정보에 따라 각기 다른 forget gates 가중치를 주어, 이웃 노드 별로 영향도를 다르게 가져가기 위해 제안된 방법입니다.
그리하여, 주변 superpixel중 중요한 부분을 알아서 학습할 수 있도록, 모델의 weight들을 조정할 수 있는, 그런 컨셉입니다. GAT가 떠오르는 느낌.
나머지 밑의 수식들은, 대부분이 LSTM과 유사한 방식으로 계산이 되기 때문에 일부 생략하지만, 한 가지 memory/cell state를 업데이트 함에 있어서도, visit flag가 쓰인다는 것만이 기존의 LSTM과 다른 점일 것 같습니다.

이 장 부터는 해당 저자들이 모델 검증을 위해 수행한 실험의 셋팅과, 결과에 대해 말씀 드리겠습니다.
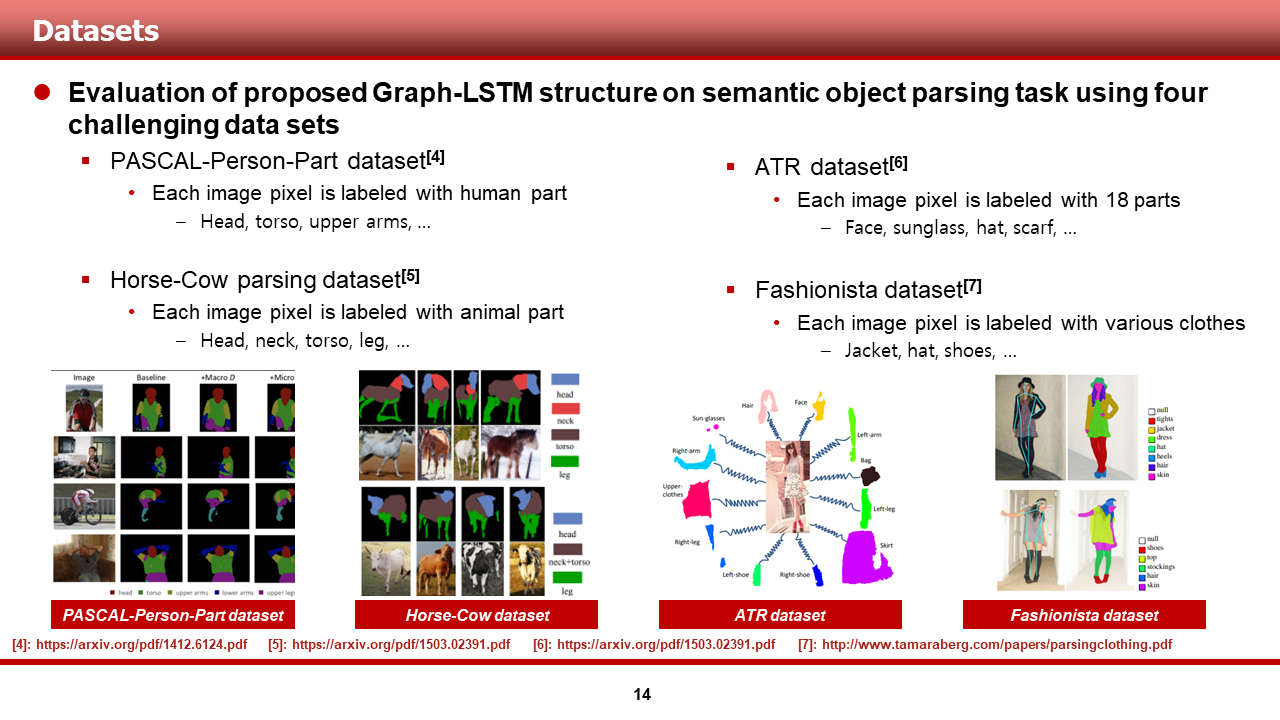
가장 먼저, 저자들이 사용한 dataset들에 대해서 말씀 드리겠습니다.
해당 데이터셋들은 semantic object parsing task를 평가하기 위해, 기존에 쓰였던 데이터 셋들이며, 먼저, 사람과 동물의 신체 부분이 라벨링 되어 있는 PASCAL-Person-Part dataset과, Horse-Cow dataset이 있습니다. 두 번째로는, 사람이 어떤 옷을 입었는지 등의 정보가 라벨링 되어 있는 ATR dataset과, Fashionista data셋이 있습니다.
저자들은 이 4개의 데이터셋에 대해 기존의 SOTA 모델과의 비교를 수행 하였으며, 가장 challenging한 PASCAL dataset에서는 ablation study를 수행하여, 자신들이 제안한 세부 기법들의 중요성에 대해서 보여주었습니다.

실험 셋팅 내용은 다음과 같습니다. 앞서 신체 관련된 두 개의 데이터셋의 경우, IOU, pixel-wise accuracy등이 evaluation metric으로 사용 되었고, ATR, Fashionista dataset의 경우, 기존의 분류 문제에서 다루는 metric들이 사용되었다고 저자들은 설명하고 있었습니다.
네트워크 구조는, 각각 기존의 SOTA 모델을 backborn model로 사용하였다고 설명하였습니다. 여러 하이퍼 파라미터 들은 슬라이드에 기재한 값으로 되어 있었습니다.

그리하여, 실험 결과는, 몇몇 클래스를 제외하곤, 모든 데이터셋에 대해 저자들이 제안한 Graph LSTM이 가장 좋은 성능을 보였다는 것을 알 수 있었습니다. 또한, 계속해서 등장하는 LG-LSTM 역시 저자들의 논문인 것은 저와 독자만의 비밀입니다..

해당 사진은, 실제 저자들이 논문에서 공개한, 정성적인 성능을 볼 수 있는 결과들입니다. 저자들은, 해당 모델의 우수한 성능을, 기존의 SOTA 모델과 비교하여 보여주었습니다. 왼쪽 사진의 경우, 일렬로 있는 사람들의 torso와 arm의 구분이 깔끔하게 되어 있는 결과는 꽤나 놀라웠습니다. (오른쪽 위에서 두 번째 사진)
또한, 저자들은 failure case를 언급하면서, 해당 모델이 너무 작은 object나 유사한 appreance를 지닌 parts들을 분리하는데엔 어려움이 있다는 것을 인정하며, 실험 결과에 대한 설명을 마무리 지었습니다.

저자들은 또한, 세부 기법이 얼마나 성능에 영향을 끼쳤는지 등을 평가하기 위한, ablation study를 다양하게 수행 하였습니다.
가장 먼저, 저자들은 superpixel smoothing이 다른 LSTM 기반 모델과 합쳐졌을 때의 성능을 확인함으로써, Graph LSTM의 아키텍쳐 및 다른 세부 기법들의 효용을 확인하고자 하였습니다. 그 결과, directed Bi-LSTM, LG-LSTM과 superpixel smoothing이 합쳐졌을 때에도 어느 정도 성능 개선이 있었지만, Graph LSTM정도의 성능은 내지 못 한다는 것을 확인했습니다.
또한, 저자들은 node updating scheme의 효용을 보여주기 위해, BFS, DFS, BFS with confidence, DFS with confidence등의 다른 updating scheme을 테스트 하였으며, 그 결과, 제안된 confidence-driven scheme에서의 성능이 가장 높은 것을 보여주었습니다.

세 번째로, adaptive forget gates을 적용 하였을 때와, 그렇지 않을 때, 즉 단일 forget gates를 사용할 때의 실험 결과도 공유함으로써, 제안된 기법의 효용을 확인하였습니다.
마지막으로, residual connection의 유무에 대한 실험도 수행 하였고, num of superpixel에 대한 parameter study 결과를 보여줌으로써, 자신들이 사용한 파라미터에 대한 타당성을 검증하였습니다.

논문을 리뷰하다 보니, 비전 연구를 하시는 분들은 파라미터 하나를 정함에 있어서도 굉장히 많은 실험을 통해 그걸 입증하는 과정을 수행하는 것을 보면서 리스펙을 하게 되었습니다. 물론 강화학습이 그런걸 안 하는 건 아니지만... 뭐 그렇습니다!
여기까지 읽어주신 분이 계시다면 감사하다는 말씀 드리며, 글을 마무리 하겠습니다.
논문의 링크는 밑에 준비되어 있습니다.
https://xiaohuishen.github.io/assets/eccv2016_graphlstm.pdf