
티스토리 뷰
editor, Junyeob Baek
Robotics & ML Research Engineer / RL, Motion Planning and Control, SLAM, Vision
![]()
관련 글
0. Prologue
지난 글에서는 Continual Learning(이하 CL)에 대한 간단한 설명과 이를 Autonomous Agent인 Robot에 적용하기 위한 일부 연구 동향들에 대해 설명해보았다. 조금 더 명확하게 설명하자면, Continual Learning의 개념모델에 대해 논의하기 위해 몇 가지 biological system의 특징으로부터 착안한 Developmental Learning의 측면에서 주로 다루었다.
개인적으로 매우 흥미로운 이야기었지만 CL에 대한 지식이 있었던 일부의 사람들에게는 '이게 Continual Learning이야? '라고 느껴질 수 있었던 부분이라고 생각한다. 하지만 아직까지 continual learning에 대한 개념이 계속해서 정립되고 논의되고 있는 상황이기에 발생할 수 있는 혼란이며, 이러한 논의는 아주 열렬히 이루어져야한다고 생각한다.
참고로 지난 글에서 참고하였던 논문의 저자(German I. Parisi)는 continual learning 전반에 대한 review논문을 다루었는데, 그 논문의 피인용수가 2년만에 무려 870회(21.07.25 기준) 이상이다. 인류의 지식은 사회적 논의와 합의를 통해 이루지는 과정이라고 생각하기에 이정도면 자신있게 소개할 수 있겠다 싶었다.
그럼에도 불구하고, Continual Learning을 다루는 논문들에서 가장 중요하게 생각하는 요소인 Catastrophic Frogetting 문제와 Distributional Shift of Data Stream 등의 현안들을 충분히 설명하지 못하고 넘어간 것에 대해서는 아쉽게 생각한다.
때문에 이번 글에서는 Continual Learning의 역사와 목적, 개념의 정의, 그리고 핵심문제에 조금 더 초점을 맞추어 설명할 예정이며, 동시에 Robotics 분야의 문제를 풀기위해 CL이 어떤 기여를 하고 있는지 함께 이야기해보고자 한다.
1. Why Continual Learning "for Robotics"

지난 20년간의 ML분야의 눈부신 발전을 통해 머신러닝은 다양한 분야에서 널리 사용되기 시작하였다.
하지만 기존의 머신러닝 방식은 컴퓨터 프로그램 내에서 최적의 솔루션을 찾고 현실의 문제에 적용하는 방식을 사용하고 있다.
이 경우 크게 두 가지의 문제가 발생하는데,
- 컴퓨터 시뮬레이션에서의 성능 갭이 발생한다. 2. 이러한 갭을 줄이려면 수많은 시뮬레이션 및 현실에서의 수많은 데이터가 필요하다.
가장 근본적인 원인은 컴퓨터 시뮬레이션은 현실과 동일하게 모델링할 수 없다는 것에 있으며, 적용해야할 수많은 상황/도메인에서의 범용적인 모델을 만들기 위해서는 정말 많은 데이터가 필요하다는 것이다. 이는 이 세상의 모든 일어날 작용들을 미리 알고 있지 않으면 불가능하다. 차곡차곡 배워나가는수밖에..!
The world is non-stationary! [7]
앞으로의 Machine Learning에서의 가장 중요한 도전은 "훌륭한 솔루션을 찾아 현실에 적용하는 것이 아닌, 바로 현실세계에서 학습을 할 수 있게 하는 것"이다. 이러한 이유로 Continual Learning에의 가장 이상적인 방향들 중 하나는 Embodied Platform인 Autonomous Agent(Robot)에서의 현실문제를 다루는 것이라 할 수 있겠다.
Continual Learning이 필요한 CASE
- 이미 학습된 모델이 있고 기존에 학습된 모델에 크게 영향을 주지 않고 새로 데이터를 추가해 모델을 업데이트 시키고 싶을 때
- 일련의 task들을 연속적으로 한 모델에 학습시키고 싶을 때(하지만 그 모든 데이터를 저장할 공간도, 컴퓨팅 파워도 부족할 때)
- 여러 policy를 지닌 agent가 있지만 언제 어떻게 learning objective가 바뀌는지 알 수 없을 때
- 시간에 따라 데이터의 분포가 변하지만 언제 어떻게 바뀌는지 알 수 없는 일련의 연속된 data stream으로부터 학습하고 싶을 때
2. History and Motivation of CL
경험으로부터 끊임없이 배운다는 개념은 초기의 Artificial Intelligence와 Robotics 연구가 시작될 무렵부더 지속적으로 논의되어왔지만, 20세기 말이 되어서야 시스템적인 접근이 비로소 시작되었다. machine learning 분야에서는 lifelong learning이라는 패러다임이 1995년 즈음에야 알려지기 시작했으며 robotics분야에서는 그 직후에 바로 developmental robotics라는 개념이 등장하였다.
90년대에서 2000년대 초 즈음에 supervised learning, unsupervised learning, reinforcement learning 등으로 개념이 분리되어 꾸준히 주목받아왔지만, 지금까지도 이 이상의 프레임의 확장으로 이어지지 못했다. 그 이유에 대해 우리는 다음과 같은 근본적인 문제들이 있었음을 정리해볼 수 있다.
- Lack of systemic approaches:
- 지난 20년 간의 ML 연구는 simple tasks에 대한 statistical or algorithmic 접근들에 집중되었을 뿐이다.
- 반면, CL은 보다 복잡하고 동적인 task에 대한 다양한 요소들과 학습알고리즘을 결합할 수 있는 그런 system적인 접근이 필요하다.
- continual learning에서 다루어지는 task의 복잡성과 학습한 task의 응용이 CL의 학습과 평가방법을 더욱이 어렵게 만들고 있다.
- 또한 continual learning과정에서 생기는 부작용(catastrophic forgetting 등)은 안정적인 학습성능을 만들어내기 위해서 반드시 해결되어야 하는 과제이다.
- Limited amount of data and computational power:
- 21세기 현재는 아주 풍요로운 디지털 데이터의 시대이지만, 사실 Big data 혁명 이전까지는 데이터를 모으고 처리하는 일이 아주 골치아픈 일들이었다.
- 게다가 computational power의 한계는 복잡하고 cost가 높은 알고리즘을 돌리기에 항상 걸림돌이 되었다.
- continual learning 시스템은 훨씬 복잡하고 다양한 task를 수행할 수 있는 학습시스템을 요구하기 때문에, 데이터의 부족과 computational power의 한계로 인해 시작조차 못하고 있었다..
- Manually engineered features and ad-hoc solutions:
- 2000년대 이전 처음 representation learning에 대한 연구가 시작될 무렵, ML 시스템을 만든다는 것은 손수 그 특징을 설계하고 만들어 맞춤형 솔루션을 내놓는다는 것을 의미했다. 물론 이는 아마도 task마다, domain마다 너무 달라서 매번 새로 설계해야만 한다는 이야기가 될 것이다..
- 보다 systemetic approach를 가진 일반적인 알고리즘을 가지는 것은 아주 장기적이고 먼 목표처럼 보이며, 매번 손수 만들어야하는 특징들을 극복하는 것은 그 목표에 도달하기 위해 아주 큰 걸림돌이 되고 있다.
이러한 한계점들은 최근의 진보된 ML 연구들과 지난 20년간의 아주 빠른 기술적 진보를 통해 점차 해소되고 있으며, 지속적으로 학습할 수 있는(CL) 시스템 등과 같은 보다 복잡한 문제의 해결을 위한 문을 두드릴 수 있게 해주었다.
Discussion in the field of robotics

최근에 일어난 ML분야의 진보는 robotics분야에게도 상당한 진전을 가져다 줄 수 있을 것으로 기대된다.
robotics 학계에서는 새로운 skill과 knowledge에 대해 지속적인 학습이 가능한 embodied machine의 실현에 대해 꾸준히 관심을 가져왔지만, 기존의 ML 기술로는 도달될 수 없는 것으로 제기되어왔던 문제였다. 반면, 최근 ML의 발전과 더불어, 학습하고 생각할수 있는 로봇지능구현을 위한 continual learning의 역할과 'embodiment'라는 개념이 주는 영향력을 이해하는 것에 초점을 두어 연구되기 시작하였다.
앞으로의 robotics분야에서의 가장 중요한 3가지 도전과제로 'Learning, Embodiment, Reasoning' 등과 같은 개념들이 제시되고 있다.[5] 그 중에서도 우리는 CL이 다루고있는 learning problem이 'embodiment'의 중요성과 그 한계에 대해 탐구하는 것이라고 가정해볼 수 있다.
(물론 CL을 탐구하는 과정에서 학습과정의 효율을 최대화하기 위한 추론(Reasoning)과 같은 개념과 함께 그 의의를 찾아낼 수 있다면 BEST CASE가 될 것이다!)
이처럼 continual learning은 아주 중요한 robotics 과제의 교차점에 위치하고 있다.
3. Challenges Addressed by CL
이번 섹션에서는 Continual Learning이 다루고있는 문제들에 대해 구체적으로 설명해보고자 한다.
CL에서 다루고있는 문제는 다음과 같이 크게 3가지로 볼 수 있다.
- Catastrophic Forgetting
- Handling Memories
- Detecting Distributional Shifts
이러한 문제들은 1.들어오는 데이터가 i.i.d로 가정될 수 없다는 점과 2.data distribution이 static하다고 가정하는 것이 유효하지 않다는 이유에서 발생한다.
Catastrophic Forgetting
- neural network이 새로운 개념에 대해 연속적으로 학습하게 될 때, 기존에 학습했던 task에 대한 성능이 저하 되는 현상을 의미한다.
- 연속적인 classes와 tasks를 학습해야하는 continual learning의 정의에 따라, catastrophic forgetting문제는 아주 중요한 도전과제로서 다루어져야 할 것이다.
- catastrophic forgetting 또는 catastrophic interference라고도 불리며, 새로운 skill의 습득이 중요한 paramter들을 수정하는 바람에 기존의 skills의 수행을 방해한다는 점에서 interference라는 표현 역시 적절하다고 볼 수 있겠다.
Handling Memories
- catastrophic forgetting(파괴적 망각)문제를 해결하기 위해서는 gradient descent(학습 최적화 과정)에 의해 망각될 정보들을 기억하는 법을 찾아야만 한다.
- continual learning은 과거의 tasks에 대한 경험을 저장할 수 있는 메커니즘이 필요하다. 메커니즘은 다양한 형태로 구성될 수 있을 것이며, 저장할 정보의 종류 역시 아주 다양한 형식으로 raw data, representations, model weights 등 다양해질 수 있다.
- 효율적인 메모리 관리전략은 중요한 정보만을 저장해야 할 것이며, 이를 통해 새로운 tasks를 위해 knowledge와 skill에 대한 transfer가 이루어질 수 있어야 한다.
- 무엇이 앞으로 중요할 정보이며 미래에 전달 가능한 정보인지를 완전히 아는것은 불가능하므로, 정확한 정보의 기록과 적절한 망각 사이에서의 trade-off를 찾는 것이 필요할 것이다. 이러한 trade-off는 stability/plasticity dilemma 문제로 잘 알려져있다.
- memory handling이 남기는 중요한 도전과제는 바로 기억할 정보와 망각할 정보에 대한 평가를 자동화하는 것일 것이다.
Detecting Distributional Shifts

- 학습 agent로 전달되는 data distribution이 stationary하지 않은 상황에서는 데이터의 분포의 변화가 발생(concept dfirt) 할 수 있다.
- 외부에서 shift에 대한 정보가 들어오지 않는 경우에는 CL 모델이 이 shift를 찾아내야만 한다! 그리고 스스로 그러한 변화에 대해 대처할 수 있어야 한다. (이러한 shift를 제대로 감지하지 못한다면 돌이킬 수 없는 망각을 초래하게 될 것이다.)
- Concept Drift는 크게 두 가지로 정의 될 수 있다.
- Virtual Concept Drift vs Real Concept Drift
- virtual concept drift는 input의 distribution이 바뀐 상황을 의미하며 이는 흔히 발생한다.
- real concept drift는 데이터에 대한 novelty나 새로운 classes(tasks)에 의해 발생하며, 갑자기 performance가 떨어지는 등의 효과등에 의해 발견된다.
- Virtual Concept Drift vs Real Concept Drift
- Distributional Shift는 task가 변함에 따라 발생하기도 한다.
- 예를들어, RL의 경우 새로운 Task를 풀어야 하는 상황이 발생하는데, 이 때는 data distribution이 명확히 바뀌지 않지만 의도적인 외부 signal을 전달한다.
- 이 때 shift가 정확히 어디서 발생했는지와 무관하게 관련없는 기술과 지식의 catastrophic interference를 피할 수 있는 방향으로 감지되어야 할 것이다.
4. A Framework for Continual Learning(요약)
해당 섹션은 [1]에서 제시한 Continual Learning의 Framework에 대해 간단히 소개하고자 한다. 이러한 작업은 연구자들 사이에서 CL문제의 정의에 대한 공론화를 통해 올바른 비교와 분석을 할 수 있도록 가이드를 제시하는 것에 의의를 둘 수 있을 것이다. 실제로 아주 방대한 양이니 자세한 내용이 궁금하다면 논문을 참고하기 바란다.
[Definition 1] Continual Distributions and Traning Sets
$$
D = {D_1, D_2,...,D_N} \space over \space X \times Y
$$
위와 같이 잠정적으로 무한히 뿜어져나오는 unknown distribution $D$가 있다. 여기서 X와 Y는 각각 input, output을 의미하는 random variable이다. 그리고 $i$ 시각에서의 training set $T_{r_i}$는 $D_i$로부터 얻어 algorithm으로 전달된다.
[Definition 2] Task

위 문장은 task의 개념과 정의에 대해 간결히 잘 설명되어있다. 즉, task란 task-label에 의해 정의된 learning experience의 축약된 표현이다.
[Definition 3] Continual Learning Algorithm
general target function $h^*$, task label $t$가 주어졌을 때, continual learning algorithm $A^{CL}$은 다음과 같은 특징을 지닌다.

[Definition 4] Continual Learning Scenarios
CL Scenario란 일련의 N개의 task label이 시간에 따라 특정 "task structure"를 구성하도록 하는 CL setting을 의미한다.
위의 제안된 framework를 기반으로, 우리는 다음과 같은 세가지 일반적인 시나리오를 정의해볼 수 있다.
이미지 분류 문제를 예로 들어 다음의 시나리오를 쉽게 설명해보도록 하겠다.

- Single-Incremental-Task(SIT): 한 종류의 task를 수행하지만 시간에 따른 distribution이 바뀐다
- 처음에는 *하얀 개와 고양이* 사진만을 보여주다가 시간이 지남에 따라 *검은 개와 고양이* 사진을 보여주는 것이다.
- 이러한 경우에는 검은 개와 고양이를 구별하도록 학습이 지속되기 때문에 흰 개와 고양이를 구별하는 법을 잊을 수 있다.
- 즉, task는 동일하지만 concept drift가 forgetting을 일으키는 상황!
- 개와 고양이를 구분하는 classification문제에서 시간에 따라 distribution이 변하는 문제를 가정해보자.
- Multi-Task(MT): 다양한 task를 수행하지만 시간에 따른 distribution 변화가 없다(stationary)
- 개 vs 고양이, 차 vs 자전거 등 전혀 다른 task를 수행한다. 이때 forgetting은 일어나지 않는다.
- class가 변할 때 task label도 변하므로 이 정보를 이용해 성능을 올릴 수 있다.
- Multi-Incremental-Task(MIT): 다양한 task를 수행하며 시간에 따라 distribution도 변한다..
- SIT과 MT scenario가 모두 적용되는 보다 복합적인 상황이다.
- 시간이 지남에 따라 일련의 task 속에서 동일한 task를 몇 번이고 반복해야 할 수 있다.
- 개 vs 고양이, 차 vs 자전거 등 다양한 분류를 해야하지만, 분류 내 이미지의 형태나 모양이 시간에 따라 편향될 수 있으므로 forgetting이 일어날 수 있다.
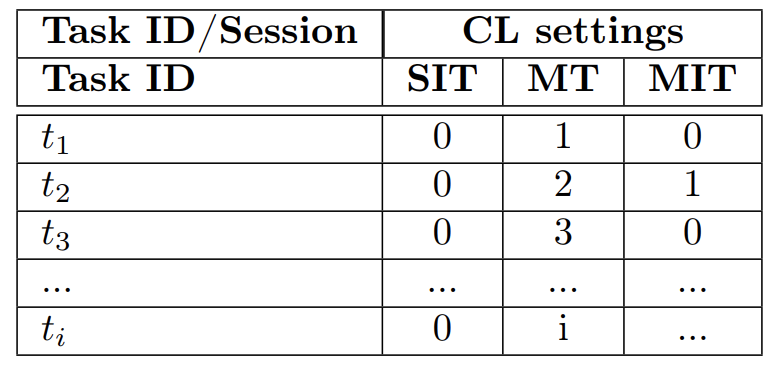
[Definition 5] Task Label and Concept Drift Scenarios
Task Label은 CL 시나리오에서 발생하는 몇 가지 케이스를 만들어낼 수 있다. 그리고 이는 다음과 같이 concept drift를 고려한 task label 케이스로 크게 세가지로 나누어볼 수 있다.

- No task label
- distribution에 대한 변화가 어떤 task label에 의해서도 전달되지 않는다.
- task는 항상 동일하다.(equivalent to SIT scenario)
- Sparse task label
- distribution에 대한 변화가 드문드문 task label에 의해 전달된다.
- 몇 가지 task로 나누어져 있지만 하나의 task 내에서 종종 distribution의 변화에 의해 concept drift가 일어나기도 한다.
- Task label oracle
- data distribution의 모든 변화가 task label에 의해서만 일어난다.(외부 신호로부터 전달받는것)
[Definition 6] Availability of Task Label
task label은 다음과 같이 두가지 케이스로 주어질 수 있다.
- Learning label
- task label이 오직 학습을 위해서만 주어진다. test time(execution)에서는 task label 등의 정보 없이 수행해야 한다.
- Permanent label
- task label이 학습을 위해 주어지며, test time(execution)에도 inference를 하기위해 사용된다.
[Definition 7] Content Update Type
매 번 training set $T_{r_i}$으로부터 얻게되는 observations나 자연(nature or real-world)으로부터 얻게 되는 data samples는 다음과 같은 형식으로 분류된다.
- New Instances(NI) : 새로운 컨셉 없이 새로운 데이터만 들어온다
- time-step $i$에서의 training set으로부터 얻은 data samples 또는 observation이 기존과 동일한 dependent variable $Y$(output)이다.
- 마찬가지로 classification의 예로 들자면, 흰 고양이만 들어오다가 검은 고양이가 데이터 입력되었다.
- New Concepts(NC) : 기존의 컨셉에 속하지 않는 아닌 새로운 컨셉이 들어온다
- time-step $i$에서의 training set으로부터 얻은 data samples 또는 observation이 모델로부터 학습된 새로운 dependent variable $Y$(output)이다.
- e.g. 고양이 이미지만 입력으로 들어오다가 자전거 이미지가 데이터로 입력되었다.
- New Instances and New Concepts(NIC) : 새로운 컨셉과 알려진 새로운 이미지들이 섞여 들어온다
- time-step $i$에서의 training set으로부터 얻은 data samples 또는 observation이 이미 조우한적이 있거나 새로운 dependent variable $Y$(output)이다.
- e.g. 순서 상관없이 흰고양이, 코뿔소, 엄마기린, 검은고양이, 아기기린.... 새로운 분류의 데이터가 나오기도하고 기존의 데이터가 입력되기도 한다.
(이상 자세한 내용은 [1] 참조.)
다음 편에는 Continual Learning에서 직면하고 있는 문제를 풀기위한 전략들에 대해 알아보고, Robotics에 적용하기에 어떤 기회들과 문제점들이 있는지 자세히 알아볼 예정이다.
To Be Continued...
본문은 "Continual learning for robotics: Definition, framework, learning strategies, opportunities and challenges."의 내용 및 구성을 참고해 수정 및 추가하였습니다.
References
[1] Lesort, Timothée, et al. "Continual learning for robotics: Definition, framework, learning strategies, opportunities and challenges." Information fusion 58 (2020): 52-68.
[2] Parisi, German I., and Christopher Kanan. "Rethinking continual learning for autonomous agents and robots." arXiv preprint arXiv:1907.01929 (2019).
[3] Parisi, German I., et al. "Continual lifelong learning with neural networks: A review." Neural Networks 113 (2019): 54-71.
[4] Khetarpal, Khimya, et al. "Towards continual reinforcement learning: A review and perspectives." arXiv preprint arXiv:2012.13490 (2020).
[5] Sünderhauf, Niko, et al. "The limits and potentials of deep learning for robotics." The International Journal of Robotics Research 37.4-5 (2018): 405-420.
[6] Driess, Danny, Jung-Su Ha, and Marc Toussaint. "Deep visual reasoning: Learning to predict action sequences for task and motion planning from an initial scene image." arXiv preprint arXiv:2006.05398 (2020).
[7] "Embracing Change: Continual Learning in Deep Neural Networks", Seminar by Razvan Pascanu at the UCL Centre for AI. Recorded on the 5th May 2021., https://www.youtube.com/watch?v=ES1CA9Fi5uc
관련 글
'whitebot > Continual Learning' 카테고리의 다른 글
| Continual Learning for Robotics(1) (12) | 2021.06.19 |
|---|