

티스토리 뷰
[1] Dota2 with Large Scale Deep Reinforcement Learning (OpenAI "Five")
잿빛들판 2021. 5. 15. 17:25editor, Seungeon Baek
Reinforcement learning Engineer /RL, Planning and Control
- 해당 글은 개인 블로그의 글들을 옮겨온 글입니다. -
https://seungeonbaek.tistory.com/2?category=806048
Paper review of RL (1) Dota2 with Large Scale Deep Reinforcement Learning (OpenAI "Five")
강화학습 연구 관련 트렌드를 파악하기 위하여, 블로그에서 강화학습 논문 리뷰 연재를 시작하게 되었습니다. 꾸준히 작성하여 많은 사람들에게 도움이 되었으면 좋겠습니다! DeepMind의 연구진
seungeonbaek.tistory.com
클릭해 주셔서 감사합니다.
저는 강화학습 연구 관련 트렌드를 파악하기 위하여, 개인, 팀 블로그에서 강화학습 논문 리뷰 연재를 시작하게 되었습니다. 꾸준히 작성하여 많은 사람들에게 도움이 되었으면 좋겠습니다!
DeepMind의 연구진들이 블리자드사의 Starcraft2를 정복한 논문을 발표함에따라, 강화학습이 cartpole, Atrai 2600 등의 간단한 게임들 뿐만 아니라, 상업적 프로리그가 존재하는 더욱 어려운 게임들을 해결할 수 있다는 것을 증명해 냈습니다.
그에 맞서, OpenAI의 연구진들도 Dota2라고 하는, 가장 어려운 게임 장르 중 하나인 AOS 장르의 게임에서 현재 세계 챔피언인 Team OG를 꺾은 논문을 발표하였습니다.
General AI를 꿈꾸는 강화학습 연구진들의 꿈이 점점 현실로 다가오는 것 같아서 무서우면서도 대단하네요.
그럼, 본격적인 리뷰 시작하겠습니다!

DeepMind의 Starcraft II를 정복한 agent의 이름은 Alphastar였죠, Open AI의 Dota2를 정복한 agent의 이름은 Five로 지었다고 합니다. 논문의 제목은 굉장히 심플하게 지었다는 느낌이 듭니다.

목차는 다음과 같습니다. 가장 먼저 AI, 특히 RL이 이루어낸 이전의 마일스톤들에 대해 간단히 설명을 드리고, Dota2가 어떤 게임인지에 대한 설명을 드린뒤, 본론인 training system관련 내용과 실험 및 결과를 평가한 내용에 대해 준비 하였습니다.
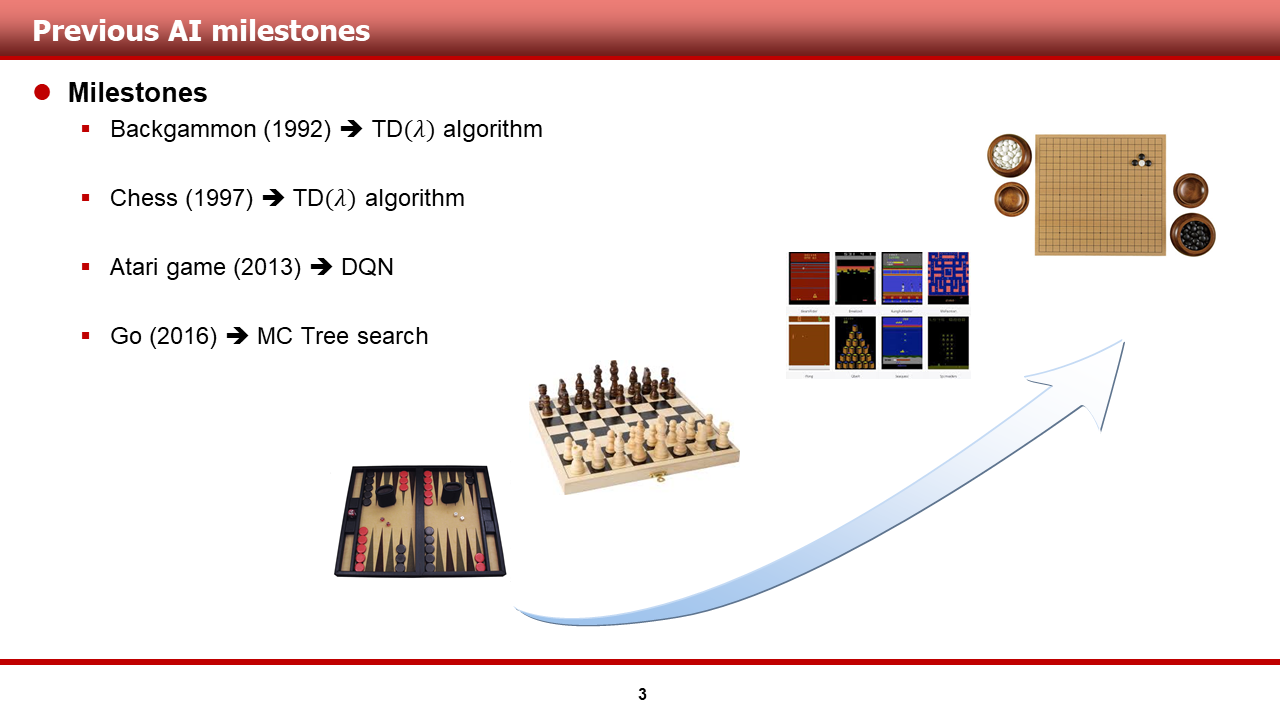
강화학습을 연구하는 많은 연구진들은, 실제 세상의 복잡하고 연속적인 문제를 풀 수 있는 AI를 설계하기 위한 초석으로써, 게임이라는 환경을 많이 선택해오곤 했습니다. 그리하여, 그림에 표현된 것 처럼 1992년 비교적 간단한 게임인 Backgammon을 고전적인 알고리즘인 TD - labmda algorithm을 통해 해결하기도 하였습니다.
그후, 강력한 function approximator인 신경망의 등장에 힘입어 수 백여개로 이루어진 Atari 2600 게임 중 50여 개에 대한 학습이 어느정도 성공적으로 이루어졌으며, 저를 포함한 많은 사람들을 놀라게한 Alpha Go 또한 등장하기도 하였습니다.

이러한 흐름의 일부로써, 그리고 종착지 중 하나로써 Open AI는 Team game이며 상업적인 리그가 존재하는 Dota2를 학습하는 결정을 내렸으며, 이 페이지에서는 Dota2의 특성과 RL의 관점에서 본 Dota2의 challenging issue들을 설명하고 있습니다.
Dota2의 경우, 기존의 학습 대상이었던 게임과 다른점은 다음과 같습니다.
1) Dota2는 Multi-player game입니다. 즉, single agent를 control 하던 문제와는 한 차원 다른 협업/경쟁 이라는 task를 수행해야 하는 게임입니다.
2) Dota2는 실시간으로 전황이 바뀌는 AOS 장르의 게임입니다. 그리하여, Dota2를 정복하기 위한 RL agent는 학습을 통해 최적의 decision 뿐만 아니라, 최적의 tactics, 최적의 strategy 모두 학습을 해야합니다.
3) 프로/아마추어 대회가 존재하는 상업적으로 성공한 게임입니다. 그렇기에, 경기와 관련된 데이터를 획득하기 쉽고, 랭크 시스템, 프로팀 과의 대결 등을 통해 RL agent의 실력을 가늠하는 것이 가능합니다.
이러한 Dota2를 RL의 관점에서 보았을 때, challenging한 이슈들은 다음과 같습니다.
1) 먼저, Dota2의 경우, 기존의 chess, Go와 같이 수 백여 번의 action으로 끝나는 게임이 아니며, 약 15~30분 동안 20000번의 action을 수행해야 끝나는 long-horizon planning이 필요한 게임입니다.
2) Dota2는 Chess, Go 처럼 모든 정보가 공개된, 관측 가능한 게임이 아닙니다. 팀원 혹은 게임 내 팀원 몬스터 등이 존재하는 지역이 아니면 안개가 끼는, partial observable한 게임입니다.
3) Dota2는 매우 높은 차원의 observation and action space를 가지는 게임입니다. 단적으로 Open AI에서 설계한 agent의 경우, 1 step에 8000~80000 개의 action을 선택 해야 했다고 하니 agent입장에서 굉장히 난해한 문제였다고 볼 수 있을 것 같습니다.
4) Complex rules, Dota2의 장르인 AOS는 인간에게도 입문이 쉽지 않은 게임 중 하나에 속합니다. 물론 저도 꽤나 즐기고 있는 장르이지만, 처음 입문했을 당시를 생각하면 팀원에게 욕먹고, 포탑과 일기토를 하다 죽던 제가.... 스킵하겠습니다.

그러면, 이 장 부터는 Open AI가 이렇게 어려운 게임인 Dota2를 어떻게 학습 시켰는지에 대해 말씀드리겠습니다. 일단, Open AI의 경우 Dota2를 해결하기 위해 다음과 같은 제약을 두었습니다.
1) Case study를 통해, 117개의 전체 영웅 중 17개의 영웅만을 적과 아군이 고를 수 있도록 하였습니다.
2) 상대방을 조종하는 등 변수를 너무 많이 줄 수 있는 item을 배제한 뒤 학습을 수행하였습니다.
이러한 제약 조건은 Observation space를 줄여주어, agent가 탐험해야할 공간을 줄여준 것으로 볼 수 있을 것 같습니다.
뿐만 아니라, 몇몇 행위는 policy를 통해 선택하는 것이 아니라, hand-script를 사용하였다고 합니다.
1) 아이템과 ability의 구매 행위
2) 특정 탈것 유닛의 제어
3) item을 보관하는 행위
Open AI Five는 이러한 방법을 통해 action space를 줄여주는 효과를 얻은 것 같습니다.

이렇게, 그나마 간소화된 Dota2를 Open AI는 다음과 같은 model architecture를 통해 훈련시켰다고 합니다. 그 안을 자세히 들여다 보겠습니다.
먼저, Open AI의 Five의 경우, DeepMind의 Alphastar와 달리 observation을 간단한 processing만을 거친 뒤 사용하였다고 합니다. 이를 두고 Visual processing보다 planning 문제를 해결하는데 초점을 맞추고 싶었다는 주장을 하고 있긴 하지만, 저는 feature를 잘 선정하는 것도 planning 문제를 해결하기 위해 필요한 과정이라고 생각하기 때문에, 이 의견에 백 퍼센트 동의하지는 않습니다.
이렇게 processing, flatten 된 observation은 4096-unit의 거대한 LSTM으로 입력된다고 하며, 이러한 모델은 각 영웅 별로 가지게 된다고 합니다. 그리하여, 전체 신경망의 parameter는 159 million.. 이라고 합니다. Dota2가 굉장히 어려운 문제였다는 것을 방증하는 parameter의 개수라는 생각이 듭니다.

또한, 전체 강화학습 신경망의 학습은 슬라이드에 첨부한 그림과 같은 방법으로 훈련을 시켰다고 합니다. 그림에 대한 설명을 드리기에 앞서 몇 가지 설명을 드리도록 하겠습니다.
1) 먼저, 강화학습 알고리즘은 Policy gradient 계열에서 SOTA중 하나로 인정받는 PPO를 사용했다고 합니다.
추가적으로, 기존 ML분야에서 많이 사용되는 gradient clipping 기법을 사용했다고 합니다.
2) 또한, Go, Star를 학습 시킨 방법과 유사하게, Dota2 역시 self-play를 활용하여 학습을 수행했다고 합니다.
3) Dota2가 패치될 때 마다 학습을 bottom to scratch로 진행하는 것이 불가능 하므로, transfer learning과 유사한 surgery를 이용했다고 합니다.
이제 본격적인 학습 시스템에 대해 설명을 드리겠습니다.
1) Policy network가 내재되어 있는 Forward pass GPU에서는, rollout worker로부터 observation을 받고 action을 전달해 줍니다.
2) Rollout worker는 각각 Dota2 engine을 포함하고 있으며, Python control code와 gRPC를 이용한 통신을 통해 Dota2 엔진에서의 step을 수행하고, sample을 모으는 역할을 합니다.
3) 이렇게 모아진 sample은 experience buffer로 전달이 되며, Optimizer에서 PPO algorithm을 이용해 학습이 수행된다고 합니다.
4) 마지막으로, 이러한 학습된 parameter들을 controller를 통해 신경망으로 다시 전달해주는 것으로 전체 학습 시스템이 동작합니다.
최근 어려운 Multi-agent planning문제를 해결한 DeepMind의 Alphastar, Open AI의 Dota2 모두 self-play 개념을 이용하여 강화학습 신경망의 학습에 있어서 탁월한 결과를 얻었다는 점은 눈여겨 볼 만한 자료인 것 같습니다. 또한, 패치에 대응하는 transfer learning개념과 gRPC를 이용한 FIVE의 분산학습 구조도 눈여겨 볼 만한 점이라고 생각이 되는 것 같습니다.
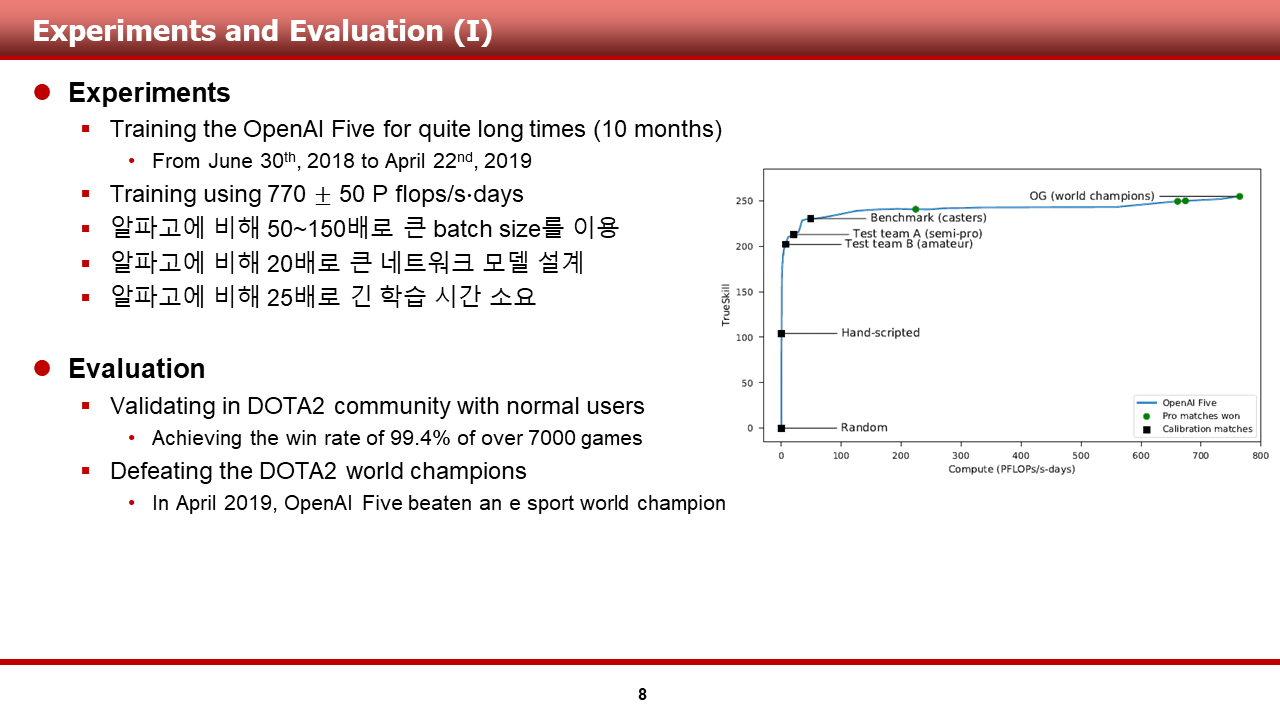
이러한 신경망 구조와, 학습 방법을 이용하여 Open AI는 약 10개월 동안 학습을 수행했다고 합니다. 이 10개월 간 신경망의 학습에는 약 770 P flops/s.day의 연산이 수행 되었다고 하는데, 정말 엄청난 스케일이 아닌가 하는 생각이 듭니다..
이 규모를 논문에서는 DeepMind의 AlphaGo와 비교 하였는데, AlphaGo에 비해 50~150배로 큰 batch size, 20배로 큰 network model, 25배로 긴 학습 시간이 소요되었다고 합니다. 가슴이 웅장해지는... large scale입니다.
학습한 결과는 다음과 같습니다. Open AI의 경우, 수행한 연산량에 따라 Agent가 어느정도 수준에 도달 했는지를 보여주고 있습니다.
학습이 수행된 이래, 100 P flops/s.day의 연산이 수행 되기도 전에, FIVE는 armature와 semi-pro를 이겼다고 합니다. 그 후, 200 P flops/s.da이상의 연산이 수행되자 casters라는 프로팀을 꺾었으며, 전체 학습이 끝난 시점엔 World champion인 Team OG를 꺾었다고 합니다.
AOS 장르를 한 때 즐겼던 제 입장에선, 이게 얼마나 대단한 일인지 피부로 와닿고 있지만, AOS 장르 게임에 생소하신 분들에게는 '2020년의 뮌헨을 이긴 로봇 축구단이 탄생했다!' 정도의 임팩트라고 생각해 주시면 될 것 같습니다.

Open AI는 AlphaStar와 유사하게, 여러 hyperparameter 들에 따른 case study를 수행하여, 후대 연구자들에게 인사이트를 주고자 한 것 같습니다. 이 장은 그에 대해 설명하고 있습니다.
1) Batch size에 따른 학습 성능 평가: Optimizer에서 gradient 계산과 update를 수행함에 있어 sample을 쌓아둔 batch size의 경우, 크면 클 수록 좋다고 합니다. '장인은 도구를 가리지 않는다.'는 말은 적어도 이러한 대규모 스케일의 AI에선 통하지 않는 말인 것 같습니다.
2) Data quality에 따른 학습 성능 평가: 이는, experience buffer 내의 sample을 몇 회 재사용 할 것이냐에 따른 학습 성능을 보여주고 있습니다. 그 결과는, sample reuse 회수가 적을 수록 학습 성능이 좋았다고 하며 이 또한, Rollout worker가 얼마나 빠르게 수행되어 많은 sample을 줄 수 있는지(computing power)와 관련된 문제인 것 같습니다.
3) Planning horizon에 따른 학습 성능 평가: Open AI의 경우, 감사하게도 planning horizon에 대한 실험도 수행해 주었습니다. 막연히, horizon이 길 수록 좋지 않겠냐는 생각은 누구나 할 수 있지만, 이렇게 실험을 통해 입증을 해준 것은 또 다른 의미를 가지는 것 같습니다.
논문의 링크는 밑에 준비되어 있습니다.
Dota 2 with Large Scale Deep Reinforcement Learning
On April 13th, 2019, OpenAI Five became the first AI system to defeat the world champions at an esports game. The game of Dota 2 presents novel challenges for AI systems such as long time horizons, imperfect information, and complex, continuous state-actio
arxiv.org
'잿빛들판 > Multi-agent RL' 카테고리의 다른 글
| [4] Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments (MADDPG) (0) | 2021.05.17 |
|---|