
티스토리 뷰
Focal Loss for Dense Object Detection 리뷰
hanyangrobot 2021. 2. 5. 13:05작성자 1 : 한양대학원 융합로봇시스템학과 유승환 석사과정 (CAI LAB)
작성자 2 : 한양대학교 로봇공학과 정석훈 학부생
오늘은 Focal Loss 논문 리뷰를 하겠습니다! 우리가 흔히 사용하는 MSE(Mean Squared Error)나 CEE(Cross Entropy Error)를 사용하는데, 그 중 CEE를 Object Detection의 정확도 향상을 위해 reshape한 것이 Focal Loss입니다. 그럼 리뷰 시~작!
링크 0 (승환 논문 리뷰 링크 모음) : github.com/RobotMobile/cv-deep-learning-paper-review/blob/master/README.md
RobotMobile/cv-deep-learning-paper-review
Contribute to RobotMobile/cv-deep-learning-paper-review development by creating an account on GitHub.
github.com
링크 1 (원문) : arxiv.org/pdf/1708.02002.pdf
0. Abstract
<Object Detection 종류>
- object detector는 크게 one-stage, two-stage로 구분됨

- two-stage detector에는 R-CNN 계열(R-CNN, Faster R-CNN 등)이 있으며, 속도는 느리지만 정확도는 높음
- one-stage detector는 YOLO, SSD 등이 있으며, 속도는 빠르지만 정확도는 two-stage에 비해 낮음
- 본문에서는 왜 one-stage detector는 정확도가 낮은지에 대해 분석을 진행함
<one-stage detector의 정확도가 낮은 이유 분석>
- 학습을 할 때, 극단적인 클래스 불균형이 이러한 결과(낮은 정확도)가 도출됨 (이유는 1. intro에서 더 자세히 소개)
* 클래스 불균형 : detect할 물체 vs 배경 --> 물체에 비해 배경의 수가 훠월씬 더 많음
- 이를 해결하기 위해 Cross Entropy Loss를 reshape함 --> Focal Loss라고 이름을 붙임
* Focal Loss의 수식은 1절 Introduction에서 소개
<새로운 제안 : Focal Loss 및 RetinaNet>
- Focal Loss에 분류하기 쉬운 문제(Easy Negative Examples : Backgrounds)보다 분류하기 어려운 문제(Hard Positive Examples : object(foreground))에 더 많은 가중치(factor 감마)를 적용함으로써 Object 검출에 더욱 집중하여 학습 진행


- Focal Loss의 효과를 입증하기 위해 간단한 dense detector를 만듦 --> RetinaNet
- RetinaNet은 one-stage detector로 판단속도가 빠르고, state-of-the-art-two-stage detector보다 정확도가 높음

1. Introduction
(1-1) 현재의 state-of-the-art Object Detectors의 특징 : Two-Stage Detector
- 현재 object detector 중 성능이 가장 좋은(state-of-art) 모델은 two-stage임
- 대표적으로 Feature Pyramid Network(FPN), Faster R-CNN 등이 있음
- region proposal-driven 메커니즘을 지님 (관심 있는 영역을 추출하는 first stage가 존재)
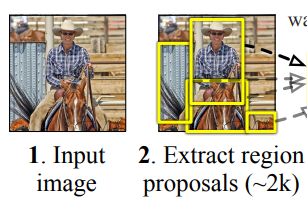
- first stage : candidate object locations의 세트(=region proposal)를 생성
* Region Proposal에 사용되는 알고리즘 : Selective Search, EdgeBoxes, DeepMask, Region Proposal Network 등등
- second stage : 해당 object locations의 class(foreground인지 혹은 background인지)를 CNN을 사용하여 예측
* 본문에서 foreground란 단어가 많이 등장하는데, 이는 detect할 object라고 이해하면 됩니다!
- two-stage detecor는 first stage에서 object가 존재할 확률이 높은 region proposal를 생성하기 때문에 one-stage보다 class 불균형 문제가 덜 민감함
- 또한 second stage에서 fixed forground-to-background ratio (1:3) 혹은 Online Hard Example Mining (OHEM)을 사용함으로써 object와 background의 비율을 맞춤
* fixed forground-to-background ratio : region proposals 중에서 forground region과 background region을 IoU 임계값을 기준으로 1:3으로 맞춘다는 의미인 것 같습니다
* OHEM : Loss 값이 큰 Region(=Hard Example) 중 N개를 다시 학습에 사용
* fixed~와 OHEM 참고 링크 : velog.io/@haejoo/Training-Region-based-Object-Detectors-with-Online-Hard-Example-Mining-%EB%85%BC%EB%AC%B8-%EC%A0%95%EB%A6%AC
Training Region-based Object Detectors with Online Hard Example Mining 논문 정리
CPN읽다가 도저히 이해가 안가서 OHEM(Online Hard Example Mining) 이해하려고 가져온 Training Region-based Object Detectors with Online Hard Example Mining paper 정리글이다.
velog.io
(1-2) 그러면 One-Stage Detector의 성능(정확도)을 더 높일 수 있을까?
- One-stage detector는 region proposal 과정을 거치지 않고, CNN의 결과물인 Feature map 자체에서 localization 진행
- 이를 위해 anchor box를 사용하며, anchor box에 scales, aspect ratio를 적용
* anchor box란 사전에 미리 정의한 box (미리 정해놓으면 계산 효율성 증가)
* scale는 anchor의 길이 비율 (scale 1, scale 2, scale 3 등등)
* aspect ratio는 anchor box의 가로 세로 비율 (1:1, 1:2, 1:3 등등)
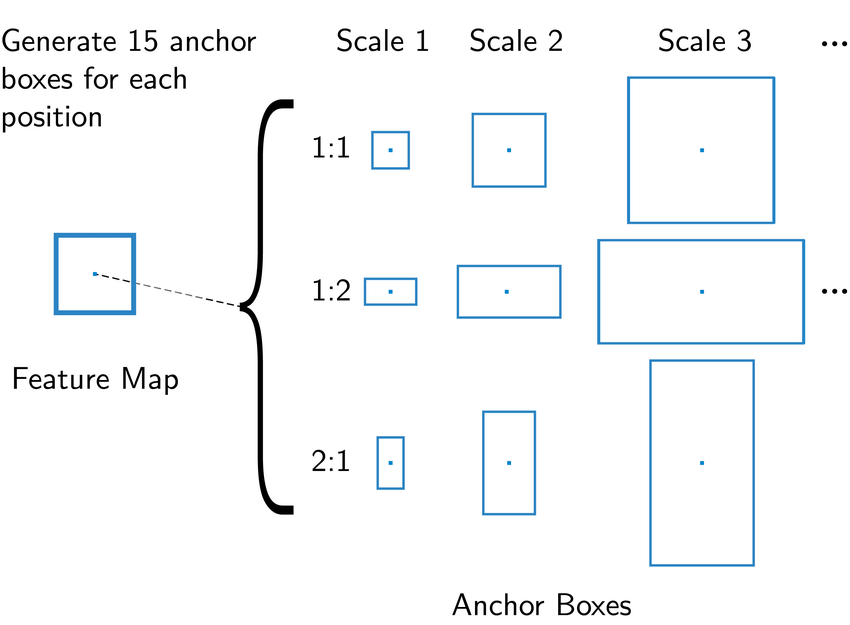
- one-stage detector는 two-stage에 비해 속도는 빠르지만 정확도는 낮음
- 정확도가 낮은 이유 중 하나로, Class 불균형 문제(Object vs Background)가 존재
- Feature Map의 grid 마다 anchor box를 적용하기 때문에, one-stage보다 candidate object locations의 개수가 훨씬 많음
* 어떤 논문에서는 Feature Map을 receptive field라고 부르기도 합니다.
* Grid : 예를 들어 5*5 Feature map이라면, 가로 5칸, 세로 5칸으로 총 25개의 grid가 존재
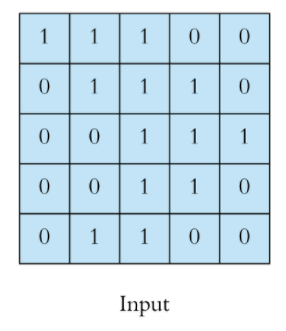

- 따라서 Feature Map에는 object가 background 보다 훨씬 적음
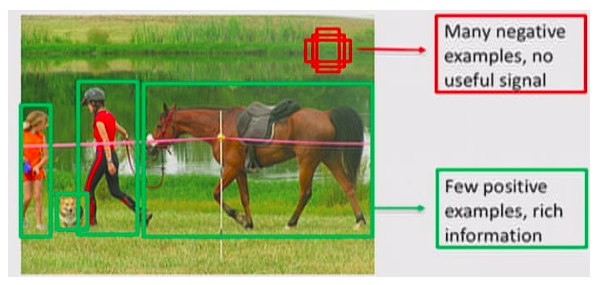
- 이러한 상황은 데이터 클래스 불균형(Class-Imbalance) 문제를 야기함
- 최근(2018년도)의 one-stage detector는 YOLO(You Look Only Onece)와 SSD(Single Shot multibox-Detector)가 있음
* YOLO는 version 1 ~ 5까지 존재 (YOLOv5는 논문이 없습니다)
* YOLOv4 논문 리뷰 : ropiens.tistory.com/33
YOLO v4 리뷰 : Optimal Speed and Accuracy of Object Detection (공부중)
작성자 : 한양대학원 융합로봇시스템학과 석사과정 유승환 오늘은 저번달에 나온 따끈 따끈한 YOLO의 새로운 버전, YOLO v4에 대해 공부해보겠다! 아카이브 기준으로 2020년 4월 23일에 YOLO v4 논문이
ropiens.tistory.com
* SSD 논문 리뷰 : taeu.github.io/paper/deeplearning-paper-ssd/
[논문] SSD: Single Shot Multibox Detector 분석
SSD:Single Shot Multibox Detector
taeu.github.io
(1-3) 헤결책 : Focal Loss 그리고 RetinaNet
<첫번째 : Focal Loss>
- 본문에서 새로운 one-stage object Detector(RetinaNet)를 제안함
- 이 모델은 two-stage detector(FPN, Faster R-CNN 등) 만큼 성능이 좋음
- 이 결과를 이루기 위해 학습 도중의 class 불균형 문제를 해결해야 했고, 새로운 Loss Function(=Focal Loss)의 설계가 이를 해결
- Focal Loss는 기존의 Cross Entropy Loss에 factor를 적용 -> 감마가 0보다 커질수록 잘 검출한 물체(IoU가 높음)와 아닌 물체(IoU가 낮음) 사이의 loss 값의 차이를 더욱 분명하게 만듦
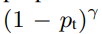
- 이 factor는 학습 시에 background보다 object 검출에 집중할 수 있게 도움
- 본문의 실험 결과는 Focal Loss가 기존의 방법(sampling heuristics(fix positive, negaitve ration), OHEM)보다 더 효과적이고 간단한 것을 보여줌
<두번째 : RetinaNet>
- Focal Loss의 성과를 효과적으로 보여주기 위해, 본문에서는 새로운 one-stage detector : RetinaNet을 제작
- RetinaNet는 anchor box를 사용하는 FPN & Focal Loss 적용이라고 볼 수 있음
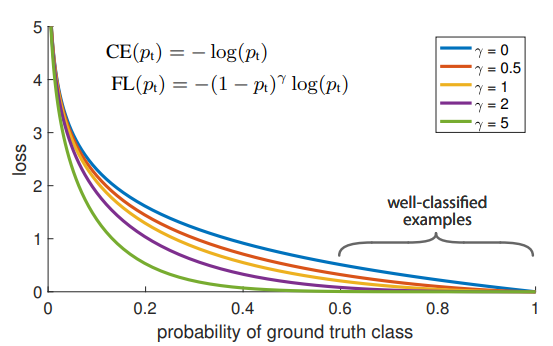
- backbone으로 101층의 FPN을 사용하는 RetianNet은 COCO 테스트 셋에서 AP 39.1%을 달성 (속도는 5 fps)
- 파란색 그래프 : backbone으로 FPN-50 layer를 사용하는 RetinaNet
- 주황색 그래프 : backbone으로 FPN-101 layer를 사용하는 RetinaNet
2. Related Workd
(2-1) Class Object Detectors
- 딥러닝 기반 oebject detector가 나오기 전에 성능이 좋았던 detector에 대한 설명
- 특징 : sliding-window 기반

- 대표적인 모델로 HOG와 DPM이 있음
- HOG(Histogram of Oriented Gradients) : 이미지의 기울기를 histogram으로 변환하며, 이를 detector의 특징(feature)으로 사용하게 됨
* HOG는 모델보다는 기법에 해당
* HOG 참고 링크 : jangjy.tistory.com/163
HOG Feature / Descriptor
일반적으로 보행자 검출이나 사람의 형태에 대한 검출에 많이 사용되는 HOG Feature Histogram of Oriented Gradients 의 줄임말로 image의 지역적 gradient를 해당영상의 특징으로 사용하는 방법이다. cell 이..
jangjy.tistory.com
- DPMs : HOG 특징을 SVM(Suport Vector Machine)에 적용하여 물체를 classify 및 detect하는 모델
* DPM 참고 링크 : 89douner.tistory.com/82
4. DPM (Deformable Part Model)
안녕하세요~ 이번글에서는 RCNN을 배우기전에 존재한 object detection 모델에 대해서 알아보도록 할게요~ 이러한 개념들을 이해하고 있어야 RCNN이 등장한 Motivation에 대해서 이해하실 수 있어요. 그래
89douner.tistory.com
(2-2) Two-stage Detectors
- 대표적인 모델 : R-CNN, Faster R-CNN (제 블로그의 R-CNN 글을 보시면 됩니다.)
* R-CNN : ropiens.tistory.com/73
R-CNN : Region-based Convolutional Networks forAccurate Object Detection and Segmentation 리뷰
작성자 : 한양대학원 융합로봇시스템학과 유승환 한양대학교 로봇공학과 정석훈 오늘은 CNN 계열의 Object Detection의 부모와 같은!! R-CNN 논문 리뷰를 진행해보겠습니다~! (segmentation에 대한 내용은
ropiens.tistory.com
- 관심있는 지역(region proposal)을 추출하는 stage와 물체를 분류 및 detect하는 stage로 분리
- R-CNN은 관심있는 지역을 추출하기 위해 Selective Search와 같은 전통 computer vision 알고리즘을 사용
- Faster R-CNN은 RPN(Region Proposal Network)로 관심있는 지역 추출 (region proposal extract에 딥러닝 적용)
(2-3) One-stage Detectors
- 대표적인 모델 : YOLO, SSD (1. intro에 링크 걸어둠)
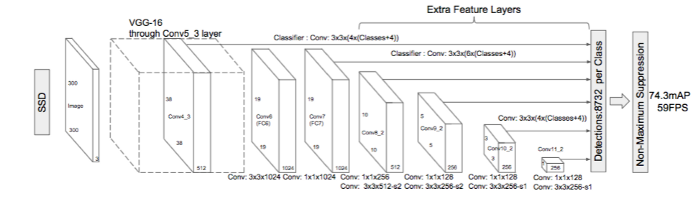
- SSD : object localize에 여러 개의 feature map을 사용함으로써 작은 물체의 detect에도 신경을 썼으나, two-stage detector에 비해 AP가 10~20% 낮음
- YOLO : 작은 해상도(네트워크 input 크기 : 288 pixel)에서 큰 해상도(input 크기 : 544)의 input을 가지는 네트워크 중에서 상황에 알맞는 네트워크를 선택함으로써 속도-정확도 간의 trade-off 가능
- RetinaNet : 본문에서 개발한 네트워크 -> RPN에서 나온 Anchor box 개념과 SSD와 FPN에서 나온 feature pyramids 개념을 이용
- RetinaNet은 네트워크 디자인이 아니라 새로운 loss function 설계 : Focal Loss가 좋은 성능에 영향을 줬다는 것을 강조
(2-4) Class Imbalance
- 기존 연구(DPM) 그리고 최신 연구(SSD)는 학습 도중에 object와 background의 class 불균형 문제에 직면함
- 이러한 detector는 이미지 당 1~10만 개의 candidate loactions을 생성하지만, 정작 그 중 검출할 object를 포함한 locations은 몇 개 없음
- 이러한 불균형은 2가지 문제를 야기함
* 첫번째 문제 : 대부분의 locations은 학습에 쓸모가 없는 배경이기 때문에 학습이 비효율적임
* 두번째 문제 : 배경이 학습에 영향을 줘서, object를 검출하지 못하거나 배경으로 검출하는 오검출을 야기함
- 이에 대한 공통된 해결책으로 hard negative mining이 있음
* hard negative mining : 학습 도중에 hard negative examples(배경인데 object라고 예측하기 쉬운 examples들)을 sampling하여 학습에 다시 사용

hard negative mining
Object Detection Network 에서 자주 나오는 hard negative sk hard negative mining라는 말이 자주 나...
blog.naver.com
- hard negative mining과 대조적으로, focal loss는 sampling하거나 기울기를 계산하지 않고도, 효율적으로 class 불균형 문제를 해결할 수 있음
(2-5) Robust Estimation : Loss function
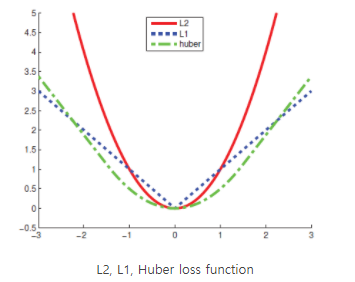
- 기존에는 robust한 loss functions을 사용함
* 예시 : Huber loss
* 에러가 작을 때 L2-error 적용 (윗항) 함으로써 미분이 불가능한 L1-error의 단점 극복
* 에러가 클 때 L1-error 적용 (아랫항) 함으로써 outlier에 민감한 L2-error의 단점 극복
* Outlier에 민감하다 : 빨간색 L2 그래프와 파란색 L1, 초록색 Huber 그래프를 비교하면, L2 그래프는 0에서 조금만 벗어나도 값이 확 커져버림 -> Outlier 값이 큼

* Huber loss 참고 링크 : process-mining.tistory.com/130
Robust Linear Regression이란? (Laplace regression, Huber regression 장점, Huber loss)
이번 포스팅에서는 Linear Regression과 Ridge Regression에 이어 Robust linear regression의 종류 중 하나인 Laplace Regression과 Huber Regression, 그리고 이들의 장점과 단점에 대해 알아보겠다. * 이번..
process-mining.tistory.com
- Huber loss는 hard examples(큰 error 값을 가짐)의 loss를 down-weight(L1 에러를 적용)함으로써 outlier의 민감도를 줄임
- 이와 반대로 focal loss는 easy examples(작은 error 값을 가짐)의 loss를 down-weight(Focal Loss의 그래프를 보면 class의 확률이 높아질수록 loss값이 훨씬 작아짐)함으로써 inliers의 민감도를 줄임으로써 class 불균형 문제 해결
- 즉, Focal Loss는 Huber Loss와 반대의 역할을 함
- Focal Loss는 Hard Example 학습에 초점을 맞춤
3. Focal Loss
- Focal Loss는 one-stage object detector의 극단적인 class 불균형 문제(예시 -> object :background = 1:1000)를 해결하기 위해 desing한 loss function
- 먼저 binary classification(class인지 배경인지 classify)에 사용되는 Cross Entropy Error 설명을 함
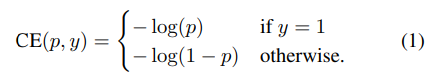
- 편의성을 위해 본문에서 P_t라는 변수를 정의
- P_t : 해당 class가 존재할 확률
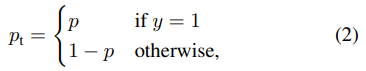
- 이제 CE를 다음과 같이 표기 가능
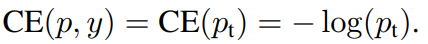
- Cross Entropy의 특징으로 P_t가 0.5보다 커도(= box에 물체가 존재할 확률이 50%가 넘어도) loss 값이 꽤 있다는 점
- 이러한 특징 때문에 easy examples(P_t가 0.5보다 큰 examples)이 많이 있다면, 이러한 loss들이 쌓이고 쌓여서 물체를 검출하지 못하는 나쁜 방향으로 학습이 될 수 있음
3.1. Balanced Cross Entropy
- α-balanced CE loss : class 불균형을 해결하기 위해 일반적으로 CE에 weighting factor α를 적용
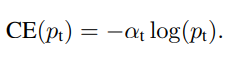
- 검출할 클래스 : α 값을 0~1 사이로 적용
- 배경 : 1-α 를 적용
- 이는 Focal Loss의 기반이 되는 수식
- 만약 α = 0.3로 설정하면, 아래와 같은 그래프가 나옴
- 이렇게 object에 대한 loss는 작게, background에 대한 loss는 크게 설정할 수 있음

3.2. Focal Loss Definition
- α-balanced CE loss의 장점 : positive/negative example의 차별성을 표현 가능
- α-balanced CE loss의 단점 : easy(p_t > 0.5)/hard example(p_t < 0.5)의 차별성을 표현 불가능
- Focal Loss : easy example에 대한 가중치를 줄이고, hard negative example의 학습에 초점을 맞추도록 α-balanced CE loss를 수정
* easy example에 대한 가중치를 줄인다 : easy example에 대한 loss 값을 줄임
* hard example의 학습에 초점을 맞춘다 : hard example에 대한 loss 값을 키움
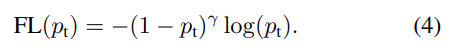
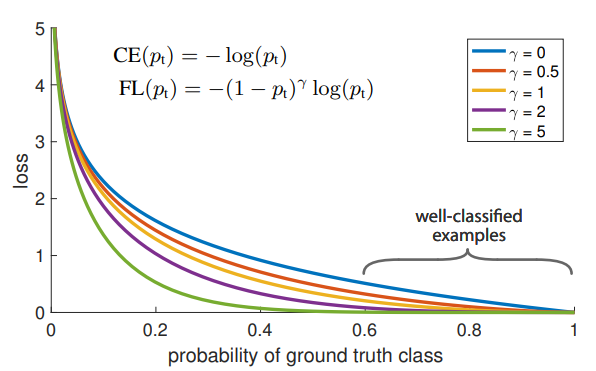
- CE에 modulating factor (1 − p_t)^ γ를 추가 (focusing parameter γ >= 0)
- focal loss는 두 가지 특징이 있음
* 첫번째 특징 : p_t 값이 작을 때, modulating factor는 거의 1에 근접하며 loss 값이 커짐 & p_t 값이 클 때 modulating facotr는 0에 근접하며 well-classified examples(p_t > 0.6)의 loss 값이 작아짐
* 두번째 특징 : 감마 값이 커질 수록 modulating factor의 영향이 커짐 (본 문에서는 감마=2가 가장 좋은 성능을 냈다고 함)
- 즉, modulating factor는 easy example의 loss 값을 더욱 더 작게 만듦
<α-balanced variant of the focal loss>
- 위에서 보인 focal loss는 α-balanced 를 적용하지 않았음
- 아래의 수식은 α-balanced 를 적용한 focal loss
-> easy/hard example의 차별성뿐만 아니라 positive/negative example의 차별성도 표현 가능

- α-balanced 를 적용한 focal loss가 적용하지 않은 focal loss보다 성능이 더 좋았음
- 아래의 부록 A에서 다양한 형태의 focal loss의 실험 결과가 적혀있음
3.3. Class Imbalance and Model Initialization
- 기존의 classification model은 output이 1 혹은 -1로 고정됨
- 본문에서는 학습 초반에 object에 대한 모델이 추정한 확률 p에 대한 개념을 추가
- p를 prior라고 이름을 붙이며, π 라고 표기
- prior를 적용한 CE와 focal loss 모두 학습 안정성을 향상시킴 (4.1절에서 자세한 내용 및 수식 소개)
3.4. Class Imbalance and Two-stage Detectors
- 이에 대한 내용은 1.intro - 1.1. two stage detecor의 class 불균형 내용과 중복되므로 생략
4. RetinaNet Detector
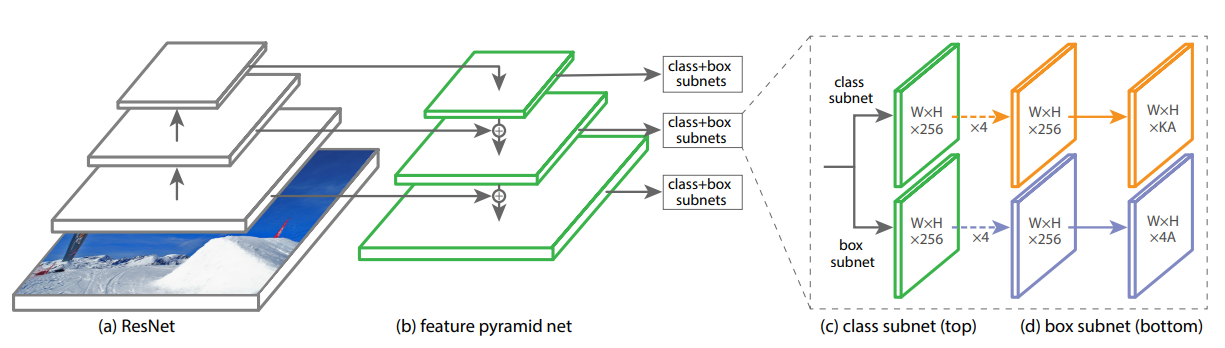
- RetinaNet는 FPN backbone(백본)과 두 개의 subnet(class & box regression)을 사용함
- (a) feedforward로 ResNet을 사용
- (b) ResNet 상단에서 FPN 백본을 사용하며, multi-scale convolutional feature pyramid를 생성 -> anchor box 생성
- (c) anchor box의 class를 예측하는 class subnet
- (d) anchor box와 GT box를 비교하여 regression을 진행하는 box subnet
<Feature Pyramid Network Backbone>
- RetinaNet의 backbone으로 FPN(Feature Pyramid Network)을 사용
- FPN은 하나의 입력 이미지에 대해 multi-scale feature pyramid를 생성
- 각 레벨의 pyramid는 다른 scale에서 object를 detect하는데 사용됨
- 작은 크기의 object 부터 큰 크기의 object 까지, 다양한 scale을 가지는 object의 detect 능력 향상
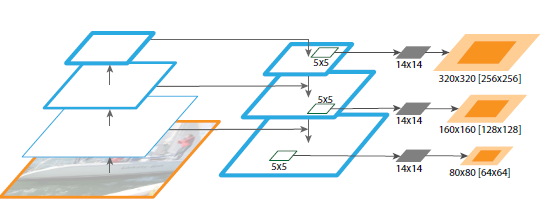
- RetinaNet에서 FPN을 ResNet의 상단에 build함
- ResNet 자체만을 사용했을 때는 AP가 낮아서 ResNet 상단에 FPN을 적용
- pyramid를 level P3~P7
- 모든 pyramid는 channels의 수는 256
<Anchors>
- 3개의 aspect ratio를 지니는 anchor 사용 (1:2, 1:1, 2:1)
- 각 pyramid level에서 anchor size 3개를 적용 (1, 1.26, 1.58) // (2^0, 2^(1/3), 2^(2/3))
- 각 level마다 9개의 anchor를 사용했으며, scale의 범위는 32~813 pixel
- 앵커 박스의 IoU 임계값은 0.5를 사용하며, IoU가 0~0.4 사이면 background라고 정의
* IoU는 당연히 앵커박스와 정답(GT)박스의 값
- 0.4~0.5 사이의 IoU를 가지는 앵커박스는 학습 도중에 무시
<Classification Subnet>
- 각 앵커박스 내의 object가 존재할 확률을 predict함
- 각 FPN level에 붙여져있는 작은 FCN(Fully Convolution Network)
- 3*3 conv layers, ReLU activations
<Box Regression Subnet>
- Class Subnet과 같이 각 FPN level에 작은 FCN을 붙임
- 각 앵커 박스의 offset 4개(box_x_center, box_y_center, box_width, box_height)를 GT박스와 유사하게 regression 함
- class-agnostic bounding box regressor를 사용
- 이 regressor는 class 정보 없이 anchor box를 regression함
- parameter 수가 적고, 성능도 효과적임
- class subnet과 box subnet은 구조는 같지만 개별적인 파라미터를 사용 (파라미터 공유 x)
4.1. Inference and Training
<Inference>
- RetinaNet의 판단 속도 향상을 위해, 각 FPN level에서 가장 box prediction 점수가 높은 1,000개의 box만 result에 사용함
- 다른 detector와 마찬가지로 최종 detection에 NMS(non-maximum suppression)를 0.5 임계값으로 적용
<Focal Loss>
- class sub의 output으로 Focal Loss를 사용
- focal loss는 각 이미지의 100,000개의 앵커 박스에 적용되고, 모든 박스의 loss 합으로 focal loss를 계산
- 이는 이전의 연구 (heuristic sampling : RPN, hard example mining : OHEM, SSD)와 다른 방식임
- focal loss에서 positve/negative sample 구분을 더 잘하기 위해 α 를 적용
- 본 연구에서는 γ = 2, α = 0.25 일 때, RetinaNet의 AP가 가장 높게 나옴
<Initialization>
- 두 개의 모델에 대해 실험 진행 : ResNet-50-FPN, ResNet-101-FPN
- ResNet-50, ResNet-101은 ImageNet으로 pre-train진행
- FPN의 initialization은 FPN 논문과 똑같은 설정값으로 진행
- RetinaNet subnet에서 마지막 layer를 제외한 모든 conv layer는 bias = 0, Gaussian weight fill = 0.01로 초기화
- classification subnet의 마지막 conv layer는 bias = − log((1 − π)/π) 로 초기화 (본문에서는 π = 0.01를 사용)
<Optimization>
- 최적화 알고리즘으로 SGD(Stochastic gradient descent)를 사용
- GPU 8개를 사용했으며, 미니배치당 총 16개의 이미지를 사용 (= GPU당 2개의 이미지)
- 초기 학습률은 0.01, 총 90,000번 학습 진행
- 학습 횟수 60,000번일 때 학습률은 0.001로 변경 (10 나누기)
- 학습 횟수 80,000번일 때 학습률은 0.0001로 변경 (10 나누기)
- weight decay는 0.0001, momentum은 0.9 사용
- class predict에는 focal loss, box regression에는 smooth L1 loss 사용
- 학습 시간은 10~35시간 소요
5. Experiments
5.1. Training Dense Detection
<Network Initialization>
- 첫 시도로 Standard CE를 이용하여 RetinaNet을 학습시켰지만 학습중 발산하며 실패하였다.
- 효율적인 학습을 위해 단순히 모델의 마지막 레이어를 π=0.01로 초기화 하였다.
- ResNet-50을 백본으로 하는 RetinaNet을 위와 같은 초기값으로 학습하였을 때 COCO데이터에 AP 30.2의 성능을 보였다.
- 실험 결과들이 π의 값에 민감하지 않아서 모든 실험에서 π를 0.01로 설정하여서 진행하였다.
<Balanced Cross Entropy>
- 두 번째 시도로 α-balanced CE를 통해 학습시킨 결과 α=0.15로 설정하였을 때 AP 0.9의 성능을 보였다.
<Focal Loss>
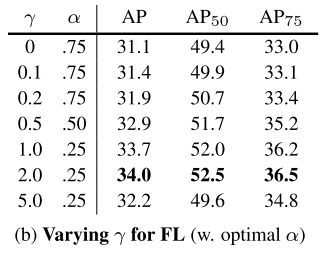
- 실험과 비교를 통해 γ값에 따른 최적의 α값을 찾았다.
- γ를 바꾸는 것에 대한 이점이 더 컸으며 실제로 α의 최적의 범위는 0.25~0.75 사이였다.
- 실험에서는 γ=2.0, α=0.25로 설정하여 실험을 진행하였으며 α=0.5일때도 괜찮은 성능을 보였다.
<Analysis of the Focal Loss>
- Focal Loss에 대한 이해를 위해 수렴한 모델들의 loss분포를 분석해 보았다.
- 이를 위해 ResNet-101 백본과 600픽셀 이미지, γ=2.0으로 학습시켰다.
- 학습 결과에 대한 FL을 Foreground와 Background로 나누어서 누적분포함수를 그려보았다.
- Foreground에 대한 누적분포 함수를 보면 γ의값에 크게 영향을 받지 않는 것을 확인할 수 있다.
- FL을 통해 효과적으로 Easy negatives의 영향을 무시할 수 있고 오직 Hard negative example에 집중할 수 있다.

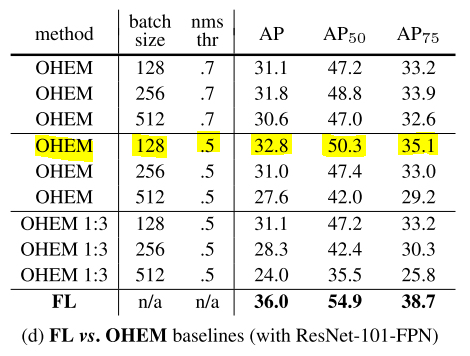
<OHEM : Online Hard Example Mining>
- FL과 마찬가지로 OHEM도 잘못 분류된 example을 강조하지만 FL과 다른점은 easy example을 완전히 고려하지 않는다는 것이다.
- ResNet-101과 FL을 사용하여 학습한 결과 36.0 AP의 결과를 보였지만 최적값으로 세팅한 OHEM을 통해 학습한 결과 32.8 AP의 성능을 보였다.
- 다양한 하이퍼파라미터를 통해 실험을 진행하였지만 결과적으로 OHEM이 FL보다 좋은 성능을 내지 못하였다.
<Hinge Loss>
- Hinge Loss를 이용하여 학습하였지만 의미있는 결과를 내지는 못하였다.
-
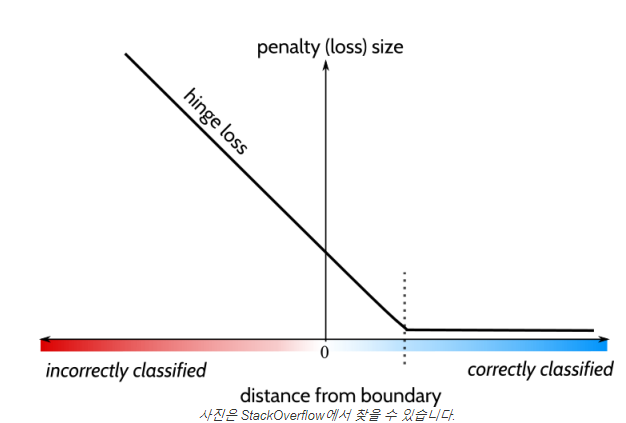
서포트 벡터 머신의 힌지 손실에 대한 명확한 설명입니다.
수수께끼 같은 비용 함수에 대한 실제 진실을 밝히는 데 도움이되는 완전히 포괄적이고 명확하며 간결한 설명입니다. 참고 :이 문서는 사용자가 SVM 작동 방식에 익숙하다고 가정합니다.
ichi.pro
5.2. Model Architecture Desing
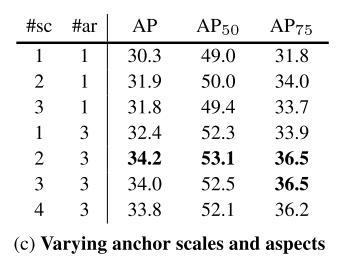
<Anchor Density>
- One-stage detector는 image box의 위치를 찾기 위해 Anchor box를 이용한다.
- ResNet-50을 사용하여 실험을 진행하였으며 하나의 정사각형 Anchor Box를 사용하였을 때 34.2 AP의 좋은 성능을 보였다.
- 3가지 크기와 3가지 비율 (총 9개)의 Anchor Box를 사용하였을 때 34.0 AP까지 성능이 올랐다.
- 6~9개 이상의 Anchor Box를 사용하는 것에는 크게 성능향상이 없었다.
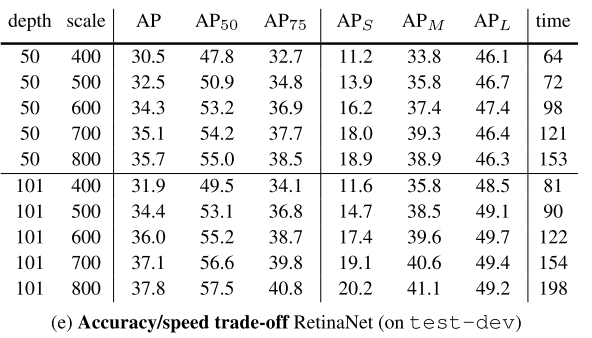
<Speed versus Accuracy>
- Focal Loss를 통해 학습한 RetinaNet이 기존에 있던 모든 모델보다 정확도 대비 연산속도가 빠르다.
- Larger Scale에서 RetinaNet이 기존의 모든 Two-stage Detector보다 속도와 정확도 모두 앞선다.

5.3. Comparison to State of the Art
- 기존 SOTA 모델들과 COCO데이터셋을 통해 비교해본 결과 : 우수함

6. Conclusion
- One-stage detector가 우수한 성능의 Two-stage detector를 능가하기 위해서는 foreground-background Class Imbalance 문제를 해결해야했고 이를 Focal Loss를 통해 간단하고 효율적으로 해결하였다.
'sinanju06 > 딥러닝 논문 리뷰 (computer vision)' 카테고리의 다른 글
| EfficientNet : Rethinking Model Scaling for Convolutional Neural Networks 논문 리뷰 (7) | 2021.04.18 |
|---|---|
| ADAM : A METHOD FOR STOCHASTIC OPTIMIZATION 리뷰 (5) | 2021.02.21 |
| Mask R-CNN 리뷰 (4) | 2021.01.27 |
| R-CNN : Region-based Convolutional Networks forAccurate Object Detection and Segmentation 리뷰 (3) | 2021.01.19 |
| YOLOv3 : An Incremental Improvement 리뷰 (2) | 2020.08.05 |