
티스토리 뷰
R-CNN : Region-based Convolutional Networks forAccurate Object Detection and Segmentation 리뷰
hanyangrobot 2021. 1. 19. 13:30작성자 1 : 한양대학원 융합로봇시스템학과 유승환 석사과정 (CAI LAB)
작성자 2 : 한양대학교 로봇공학과 정석훈 학부생
오늘은 CNN 계열의 Object Detection의 부모와 같은!! R-CNN 논문 리뷰를 진행해보겠습니다~! (segmentation에 대한 내용은 생략했습니다.)
링크 0 (승환 논문 리뷰 링크 모음) : github.com/RobotMobile/cv-deep-learning-paper-review/blob/master/README.md
RobotMobile/cv-deep-learning-paper-review
Contribute to RobotMobile/cv-deep-learning-paper-review development by creating an account on GitHub.
github.com
링크 1 (원문) : http://islab.ulsan.ac.kr/files/announcement/513/rcnn_pami.pdf
1. 연구 개요 : Abstract + Introduction
<R-CNN>
- 간단하고(simple) 확장 가능한(scalable) detection 알고리즘 제안
* 확장 가능의 의미 : object class 갯수가 수천개로 늘어나도 정확도 및 판단 속도에 큰 영향을 미치지 않음
- detection 알고리즘(모델) 명칭 : R-CNN (Region-Based Convolutional Neural Network)
- R-CNN 성능 : VOC 2012에서 가장 좋은 결과를 보였던 모델에 비해 mAP 50% 향상
<선행 연구>
- 이전까지는 복잡한 앙상블 모델(시스템)이 가장 좋은 성능 발휘
머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)
앙상블(Ensemble) 앙상블은 조화 또는 통일을 의미합니다. 어떤 데이터의 값을 예측한다고 할 때, 하나의 모델을 활용합니다. 하지만 여러 개의 모델을 조화롭게 학습시켜 그 모델들의 예측 결과들
bkshin.tistory.com
- 이러한 시스템은 multiple low-level image features를 high-level context와 combine.
<R-CNN의 2가지 아이디어>
(1) Object를 localize하기 위해 CNN에 bottom-up region proposals 적용
* bottom-up region proposal 기법 : Selective Search (SS란? : hoya012.github.io/blog/Tutorials-of-Object-Detection-Using-Deep-Learning-what-is-object-detection/)
Tutorials of Object Detection using Deep Learning [1] What is object detection?
Deep Learning을 이용한 Object detection Tutorial - [1] What is object detection?
hoya012.github.io

(2) 라벨링 된 학습 데이터가 부족할 때, 다음 기법을 적용하여 성능 향상
* supervised pre-training : ILSVRC2012 데이터셋 중 image label만 이용하여 네트워크 pre-training (bounding box label 없음)
* domain-specific fine-tuning : Training 절에서 자세히 설명할 예정 (fine-tuning 방법)
<R-CNN 개요>

(1) 입력 이미지를 받음
(2) 2000개의 bottom-up Region Proposals 추출 및 생성 (노란색 박스들)
* SS(Seletive Search) 기법을 사용
* CNN 네트워크 입력 사이즈에 맞게 Region Proposals의 크기를 warp
* warp이란? : nostudy.tistory.com/27
[OpenCV] 이미지 와핑(Warping)
* 이미지 와핑(Warping) - 기하학적 변형(Geometric Transformation)의 한 종류 - (x, y) 좌표의 픽셀을 (x', y') 좌표로 대응시키는 작업 * OpenCV의 이미지 와핑(Warping) - OpenCV에서도 와핑 함수가 구현이 돼..
nostudy.tistory.com

* 이러한 region proposal는 detections의 후보 세트를 정의
(3) CNN을 통해 각 Region Proposals들의 features 계산 --> 고정된 길이의 feature vector 생성
(4) 클래스마다 linear SVMs(Suport Vector Machine)을 적용하여 각 region의 class 분류
* SVM이란? : hleecaster.com/ml-svm-concept/
서포트 벡터 머신(Support Vector Machine) 쉽게 이해하기 - 아무튼 워라밸
서포트 벡터 머신은 분류 과제에 사용할 수 있는 강력한 머신러닝 지도학습 모델이다. 일단 이 SVM의 개념만 최대한 쉽게 설명해본다. 결정 경계, 하드 마진과 소프트 마진, 커널, C, 감마 등의 개
hleecaster.com
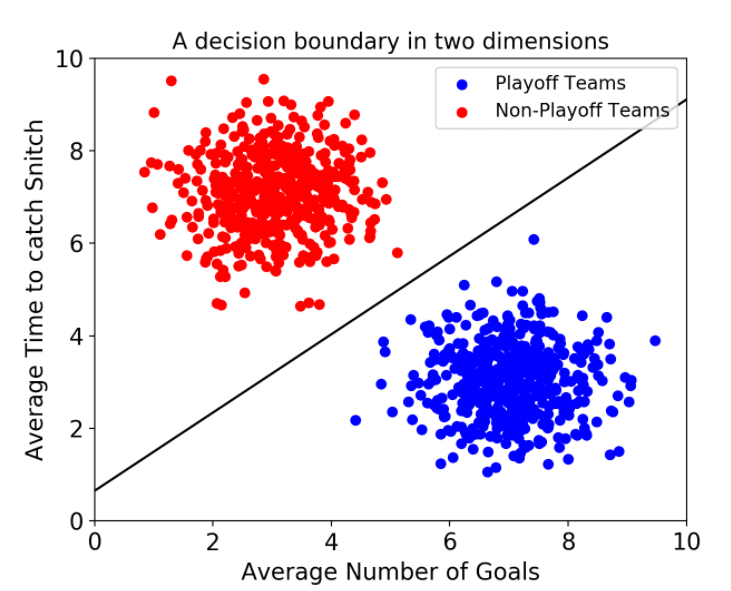
<연구 초반의 2가지 고민들>
(1) deep network를 이용하여 object를 어떻게 localize할 수 있을까? --> 이미지 내에서 Bound Box를 어떻게 그릴 수 있을까?
- 접근법 1 : localizing을 regression 문제로 접근
* 아래의 6.3 Bounding-Box(BBox) Regression 참고
- 접근법 1 장점 : 단일 object의 localizing 성능 좋음
- 접근법 1 단점 : 다수 objects의 localizing 성능 저조
- 접근법 2 : Sliding-Window 기법 적용
* sliding-window 기법이란? : hoya012.github.io/blog/Tutorials-of-Object-Detection-Using-Deep-Learning-what-is-object-detection/
Tutorials of Object Detection using Deep Learning [1] What is object detection?
Deep Learning을 이용한 Object detection Tutorial - [1] What is object detection?
hoya012.github.io
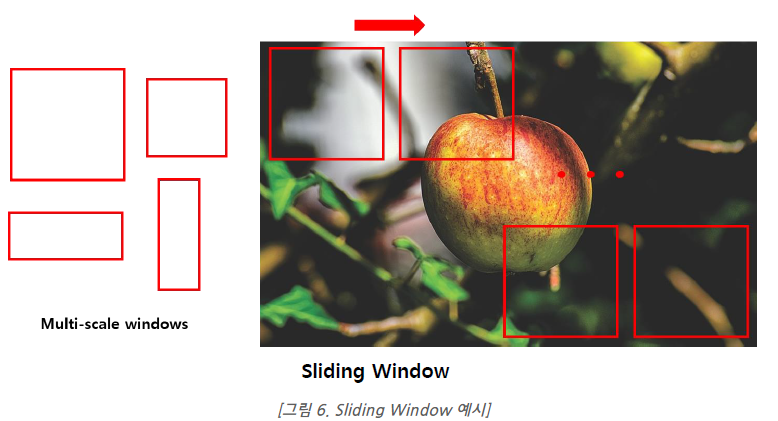
- 접근법 2 장점 : computational efficiency
- 접근법 2 단점 : 모든 object에 동일한 aspect ratio(동일한 윈도우 크기, 비율)을 사용 --> 다양한 object 크기를 반영 못함
- 접근법 3 : Recognition Using Regions (본문에서 적용한 기법, 위의 R-CNN 개요가 이 기법에 해당하는 내용) --> 본문의 기여점 1
- 접근법 3 장점 : 이 기법은 Detection 및 Segmentation에 모두 성능이 좋음
(2) 적은 양의 label된 데이터로 high-capacity 모델을 어떻게 학습할 수 있을까?
- 이전에 사용했던 방법 : Unsupervised Pre-training (with Supervised Fine-Tuning)
- 본문에서 사용한 방법 : Supervised Pre-training --> 본문의 기여점 2
* 대량의 데이터셋(ILSVRC)에서 pre-training
* domain-specific fine-tuning on a small dataset(PASCAL)
* 이 기법을 사용하여 적은 양의 데이터에서도 효과적인 성능을 보임
<R-CNN의 확장성>
- R-CNN을 base로 Fast R-CNN, Faster R-CNN 등 다양한 모델들이 나옴
- 이 부분은 2. 관련 연구에서 자세히 설명할 예정
2. 선행 연구 : Related Work
<Deep CNNs for Object Detection>
- 논문 참고문헌 12 : Deep neural networks for object detection, Szegedy et al, 2013
- 이 논문은 접근법 1(localizing을 regression으로 접근)을 적용
- image window가 주어지면, CNN을 사용하여 전체 object에 대한 grid는 몰론 object의 상단, 하단, 왼쪽 및 오른쪽 절반에 대한 전경 픽셀을 예측
- 그 후, 그룹화 프로세스로 예측된 mask(픽셀 뭉치들)를 bounding box로 변환
- VOC 2007 test에서 mAP 30.5%
- 그러나 R-CNN은 동일한 아키텍쳐 구조로 mAP 58.5% 달성 (ImageNet pre-train 사용)
- 최근 연구(논문 참고문헌 25 : Analyzing the performance of multilayer neural networks for object recognition)에서 절반의 데이터로 R-CNN을 학습한 결과 mAP 40.7% 달성.
- 이는 R-CNN의 Recognition Using Regions이 Regression 기법보다 더 효과적인 것을 증명
<Scalability and Speed>
- Object Detection 시스템은 Object의 class 갯수가 증가해도 성능 저하가 없어야함
- 기존에는 DPM : Deformable Part Model 방법을 이용하여 class의 갯수를 수천개로 늘리는 시도를 함
* DPM이란 ? : 89douner.tistory.com/82
4. DPM (Deformable Part Model)
안녕하세요~ 이번글에서는 RCNN을 배우기전에 존재한 object detection 모델에 대해서 알아보도록 할게요~ 이러한 개념들을 이해하고 있어야 RCNN이 등장한 Motivation에 대해서 이해하실 수 있어요. 그래
89douner.tistory.com
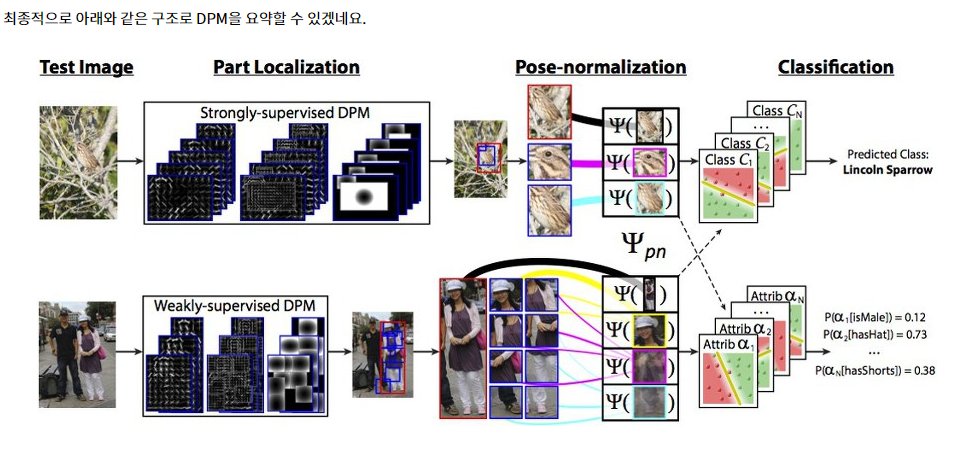
- 예를 들어 [논문 참고 문헌 26 : Fast, accurate detection of 100,000 object classes on a single machine, Dean et al, 2013]에서, DPM의 정확한 필터 convolutions을 hashtable로 바꿈.
- 이 기술을 사용하면 워크스테이션 기준, 이미지 한 장당 5분 내에 10,000개의 DPM detectors 실행 가능
- 그러나 DPM detectors가 많아질수록, detection 정확도가 감소함
- 반면에 R-CNN은 거의 모든 계산이 모든 object간 공유되기 때문에, object의 class수가 늘어나도 정확도 및 시간이 크게 감소하지 않음
* 어떤 계산이 공유되는 걸까?
- 적은 양의 행렬-벡터 내적과 greedy NMS(non-maximum suppression)가 class별로 적용되는 계산
- CPU에서 20개의 class 탐지 시간과 200개의 class 탐지 시간은 약 30ms 밖에 차이가 안남
- 그러나 R-CNN은 2000개의 region들이 독립적으로 CNN을 통과하기 때문에, 네트워크 크기에 따라 한 이미지 당 10~45초 정도 소요됨 (GPU 기준)
- 최근에는 SPPnet, Fast R-CNN(50~300ms 소요) 등 더 빠른 네트워크 들이 등장
<Localization Methods>
- Object Detection의 접근 방법은 sliding-window detectors를 기반으로 함
- 다른 대안은 후보 object로 사용되는 image regions의 pool을 계산한 후, 실제 object만 보존하는 것을 목표로 하는 방식으로 이러한 후보들을 필터링 함
- 그 중 R-CNN은 Selective Search 알고리즘(1. 연구 개요-연구 초반의 고민들 참고)에 영감을 받음
<Transfer Learning>
(이 부분은 이해가 부족합니다... 추후 기회가 되면 내용을 추가하겠습니다.)
- R-CNN 학습은 귀납적 전이학습(inductive transfer learning)에 기반을 두고 있음
- 먼저 ImageNet(classificiation) 데이터셋으로 R-CNN을 학습
- 그 후 supervised fine-tuning을 사용하여 전이학습
- 이러한 전략은 기존의 unsupervised transfering learning과 다름
- R-CNN은 supervised transfering learning을 채택
<R-CNN Extensions>
- [참고 문헌 23 : Deep fragment embeddings for bidirectional image sentence mapping, Karpathy
et al, 2014] : bi-directional image와 sentence retrieval로 모델을 학습
- 그들의 이미지 표현은 ILSVRC2013 detection 데이터셋으로 200개의 class를 detect하는 것을 학습한 R-CNN으로부터 유도됨
- 그 외는 논문 참고하기!
3. 연구 방법 : Object Detection with an R-CNN
3.1 Module Design
<3.1.1 Region Proposals>
- region proposals를 생성하는 방법들은 다양함 : objectness, selective search, category-independent object proposals, CPMC(constrained parametric min-cuts), multi-scale combinatorial grouping 등등...
- R-CNN은 이러한 방법들 중 어떤 것으로도 region proposal를 생성할 수 있지만, 이전 연구 [참고 문헌 21, 54]와 비교하기 위하여 region proposal 생성에 Selective Search를 택함.
<3.1.2 Feature Extraction>
- CNN을 사용하여 각 region proposal에서 고정된 길이의 feature vector를 생성
- CNN 아키텍쳐로 TorontoNet(input 사이즈 : 227 pixel)과 OxfordNet(16개의 layer, input 사이즈 : 224 pixel)를 사용
- 둘 다 feature vector는 4096 차원
- region을 input size에 맞추기 위해 모든 pixel를 wrap(resize)
3.2 Test-time detection
- 약 2,000개의 region proposals를 생성하기 위해 test image에 selective search를 적용
* 모든 실험에서 selective search의 fast mode를 적용
- 그 후, 각 region proposals를 wrap한 후, feature 계산을 위해 CNN으로 forward propagate 진행
- 그리고 각 클래스마다, SVM을 사용하여 추출된 feature vector를 점수 매김
- greddy NMS를 적용
* NMS란? : dyndy.tistory.com/275
NMS (non-maximum-suppression)
오래간만의 포스팅. 요즘 딥러닝을 이용한 여러 Object Detection 알고리즘을 구경하는데, 대부분 NMS (non-maximum suppression)을 사용하여 연산량을 줄이고, mAP도 올리는 효과를 본다고 한다. 물론 필수로
dyndy.tistory.com
3.3 Training
<3.3.1 Supervised Pre-Training>
- CNN의 pre-train에 사용한 데이터 : ILSVRC2012 classification (not box labels)
- Caffee 코드로 pre-training 수행
<3.3.2 Domain-Specific Fine-Tuning>
- CNN을 새로운 task(detection)과 새로운 도메인(warped proposal windows)에 adapt하기 위해, 오직 warped region proposals를 사용하여 CNN 파라미터의 학습에 SGD를 사용
- CNN 아키텍쳐는 object의 class가 변경됨에 따라 마지막 레이어가 수정된 것 외에는 동일
- ILSVRC2013에서는 200개의 class 분류
- IoU 임계값은 0.5를 사용
- 학습률은 0.001, mini-batch size는 128로 설정
4. 실험 분석 : ANALYSIS
4.1 Visualizing learned features
- 첫번째 레이어는 직접적으로 시각화 할 수 있으며 쉽게 이해할 수 있다. 하지만 이후의 레이어는 이해하기 다소 어렵다.
- 네트워크가 어떻게 학습됐는지 직접적으로 보여줄 수 있는 단순한 방법인 'non-parametric method'를 제안한다.
- 이 아이디어는 네트워크에서 특정한 feature를 분리하여 feature 자체를 object detector로 사용하였다.
- 본 논문에서는 TorontoNet의 pool5 레이어의 5번째와 마지막 콘볼루션 레이어를 시각화 하였다

- Fig. 4의 각 행은 CNN의 pool5레이어에서 활성화된 상위 16개 unit을 나타낸다.
- 이러한 unit들은 네트워크가 무엇을 학습하였는지 보여주는 대표적인 예시이다.
- 두 번째 행을 보면 강아지의 얼굴과 점들의 배열에 집중했다는 것을 볼 수 있다.
- 본 연구의 대부분의 결과는 TorontoNet 네트워크 아키텍쳐를 사용하였다.
- 하지만 어떠한 아키텍쳐를 사용하는지에 따라 R-CNN의 성능에 큰 영향을 미친다는 것을 발견하였다.
- Table 3을 보면 ILSVRC 2014 Classification Challenge에서 우수한 성능을 보인 OxfordNet을 VOC 2007 데이터로
test한 결과를 볼 수 있다.
- OxfordNet은 3x3 커널을 갖는 컨볼루션 레이어 13층과 Max-pooling 레이어 5층, 그리고 마지막 3층의 fcn으로구성되어 있다.
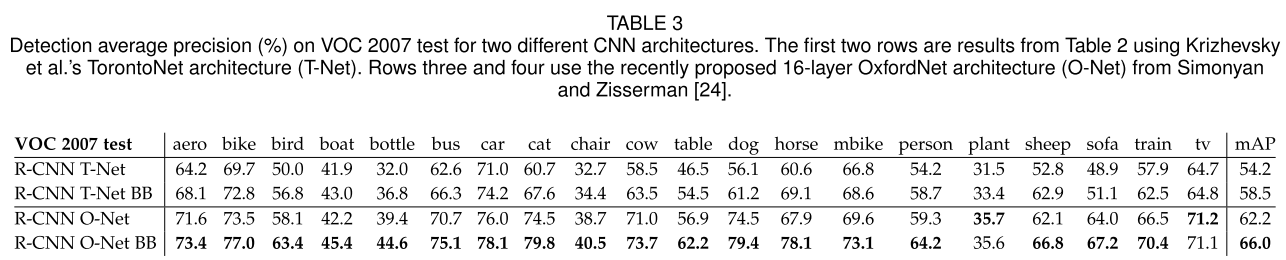
- Table 3을 보면 OxfordNet이 TorontoNet보다 mAP를 7.5% 향상시킨 것을 확인할 수 있다.(58.5% -> 66.0%)
- 하지만 Compute time은 OxfordNet이 TorontoNet보다 7배가량 오래 걸렸다.
5. 데이터셋 : The ILSVRC2013 Detection Dataset
5.1 Dataset overvies
<ILSVRC2013 detection 데이터셋 구성>
* 학습(train) : 395,918 개
* 검증(val) : 20,121 개
* 테스트(test) : 40,152 개
- 검증 및 테스트 데이터셋은 모두 annotate 되어 있음
* annotate 의미 : 각 이미지에 box label이 있음 (200개의 class)
- 반면 학습 데이터셋의 annotate는 일부 누락
- 각 데이터셋 중에 negative image들은 사용되지 않음
* negative image : label 정보가 아에 없는 이미지들(?)
<데이터셋에 대한 고민들>
(이해도 부족...)
- 학습 데이터는 hard negative mining을 할 수 없음 --> annotation이 일부 누락되어 있기 때문
* hard negative mining란? : blog.naver.com/PostView.nhn?blogId=sogangori&logNo=221073537958&parentCategoryNo=&categoryNo=6&viewDate=&isShowPopularPosts=false&from=postView
hard negative mining
Object Detection Network 에서 자주 나오는 hard negative sk hard negative mining라는 말이 자주 나...
blog.naver.com
< R-CNN의 전략>
- val 데이터셋을 학습과 검증에 모두 사용하기 위해, val 데이터셋을 동일한 크기로 2분할 --> val1, val2
- val 데이터셋에서 어떤 class는 갯수가 적기 때문에, class-balance를 맞출 필요가 있음
* 가장 적은 class 데이터 갯수는 31개, 그리고 절반 이상의 class는 110개 이하
- class-balance를 맞추기 위해 많은 수의 candidate splits을 생성
* candidiate split란 무엇일까?
- 상대적으로 클래스 불균형이 가장 작은 candidate splits이 선택
- 각 candidate splits는 그들의 class counts를 특징으로 하여 val 이미지를 클러스터링한 후, split balance를 향상시킬 수 있는 randomized local search를 통해 생성
5.2 Region Proposals
<selective search>
- val, test 데이터셋에서 fast mode로 사용됨 (not on images in train)
- not scale invariant
- 생성되는 region의 수는 이미지 해상도에 따라 달라짐
- 따라서 모든 이미지 크기를 500pixel로 resize
- val에서 selective search는 이미지마다 평균 2,403개의 region proposals를 생성했고, 91.6%의 recall값을 얻음
5.3 Training Data
(1) CNN fine-tuning
- val_1 + train_N 데이터셋에서 SGD를 50,000번 반복 (PASCAL 때의 설정과 동일)
- 이 작업에 13시간 소요됨 (Caffee 라이브러리, NVIDIA Tesla k20 사용)
(2) detector SVM training
- val_1 + train_N에 있는 모든 ground-truth boxes들이 모두 positive examples로 사용됨
- Hard negative mining은 val_1 데이터셋에서 5,000개의 이미지를 랜덤으로 선택해서 가져옴
- No negative examples는 train 데이터셋에서 가져옴 (annotations 일부 누락되있기 때문)
(3) bounding-box regressor training
- val_1에서 학습됨
6. Implementation and Design Details
6.1 Object Proposal Transformations
- 생성한 region proposals(본문에서는 object proposals라고 표기)를 CNN의 input size로 변환 필요
- 본문에서는 resize 방법으로 warp 외에도 2가지 방법을 더 시도
- 실험 결과 warping with context padding(p = 16 pixels)이 가장 성능이 좋았음
- 아래의 그림에서, (A) : origin image, (B) : tightest square with context, (C) : tightest square without context, (D) : warping 결과
- 각 사진에서 위의 사진은 p(padding_pixels)=0, 아래 사진은 p=16

(1) tightest square with context
- object와 배경이 모두 CNN input size에 맞게 scaling (여백 생김)
(2) tightest square without context
- object만 CNN input size에 맞게 scaling (여백 생김)
(3) warping
- object만 CNN input size에 맞게 scaling (여백 거의 없음)
6.2 Positive vs. negative examples and softmax
(이해가 되지 않음... 추가 공부 필요)
(1) 왜 object detection SVM을 학습하는 것과 비교하여, CNN의 fine-tuning을 위해 positive와 negative의 예가 다르게 정의되는 이유는 무엇일까?
- 가설 : 이 질문은 근본적으로 중요하지 않으며, 이는 fine-tuning 데이터가 부족한 사실에서 비롯되는 것
(2) fine-tuning한 후, SVM을 학습하는 이유는 무엇일까?
- softmax regression classifier인 fine-tuned 네트워크의 마지막 레어어를 object detector로 간단히 적용하는 것이 더 깔끔하지 않을까?
- 그러나 이를 적용했을 때, VOC 2007의 mAP가 54.2%(SVM 학습)에서 50.9%(SVM 미학습)로 하락
- 이 성능 하락은 fine-tuning에 사용되는 positive examples의 정의가 정확한 localization을 강조하지 않으며, softmax classifier가 SVM 학습에 사용되는 "hard negatives'의 부분 집합이 아니라 무작위로 sampling된 negative examples에 대해 훈련되었다는 것을 포함한 여러 가지 이유들이 있음
- 이 결과는 fine-tuning 후 SVM을 학습하지 않고도 동일한 수준의 성능을 얻을 수 있음을 보여줌
- fine-tuning을 위한 몇 가지 추가 수정이 있을 경우, 남은 performance gap은 닫힐 수 있다고 추측
- 이것이 맞다면, 이는 detection 성능 손실 없이 R-CNN 훈련을 단순화 및 가속화 함
6.3 Bounding-Box(BBox) Regression
- localization performance 향상을 위해, 간단한 BBox regression을 사용
- SVM으로 Seleceive Search Proposal를 계산한 후, BBox regressor를 사용하여 detection을 위핸 새로운 BBox를 예측
- 이 BBox regressor는 DPM에서 사용했던 것과 유사
- 알고리즘 input : (Proposal_box, GT_box)
* P_x, P_y, P_w, P_h (x, y : box_center of x, y // w,h : box's width, height)
* G_x, G_y, G_w, G_h
- 알고리즘 목표 : P를 G에 mapping 하기
- d(P) : mapping 함수, proposal P의 5번째 pooling layer의 featrue의 linear function으로 모델링됨
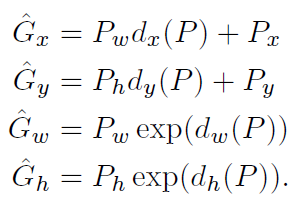
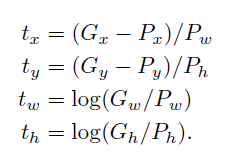
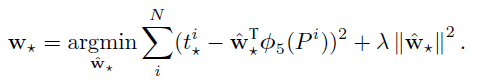
- MSE로 예측값과 GT값의 에러 값을 구함
- 이를 argmin 함수로 최소값을 찾음
- 뒤에 있는 람다는 regularzation 기능
7. 결론 : Conclusion
- 이전까지 object detection에서 가장 좋은 성능을 보인 모델 : 복잡한 앙상블 모델
* object detectors과 scene 분류기를 통해 low-level image feature를 high-level context를 병합
- 본문에서는 R-CNN이라는 간단하고 확장가능한 detection 모델을 소개
- 이는 PASCAL VOC 2012기준 이전까지 가장 좋았던 모델보다 50%가량 성능이 좋음
- 아래의 두 가지 insights를 통해 최고 성능을 발휘
(1) object를 localize하기 위해 CNN에 bottom-up region proposals(Selective Search)를 접목
(2) 라벨링 된 데이터가 부족할 때, large CNN을 학습하는 paradigm.
- 풍부한 데이터(image classification)로 네트워크를 pre-train한 후, 데이터가 부족한(detection) task를 수행하는 네트워크를 fine-tune하는 것이 효과적
- 이를 supervised pre-training/domain-specific fine-tuning 이라고 부름
'sinanju06 > 딥러닝 논문 리뷰 (computer vision)' 카테고리의 다른 글
| Focal Loss for Dense Object Detection 리뷰 (4) | 2021.02.05 |
|---|---|
| Mask R-CNN 리뷰 (4) | 2021.01.27 |
| YOLOv3 : An Incremental Improvement 리뷰 (2) | 2020.08.05 |
| YOLO v4 리뷰 : Optimal Speed and Accuracy of Object Detection (10) | 2020.05.11 |
| ResNet : Deep Residual Learning for Image Recognition 논문 리뷰 (2) | 2020.05.06 |