
티스토리 뷰
YOLOv3 : An Incremental Improvement 리뷰
hanyangrobot 2020. 8. 5. 15:16작성자 : 한양대학원 융합로봇시스템학과 유승환 석사과정 (CAI LAB)
오랜만에 딥러닝 관련 논문 리뷰를 합니다ㅎㅎ 오늘은 Object Detection에서 유명한 YOLO의 version 3를 리뷰해보겠습니다! YOLOv3는 아카이브 기준 2018년 8월에 나왔으며, Object Detection의 교제 같은 베이스 알고리즘이죠! 그럼 리뷰 시작합니다~!
링크 0 (원문) : https://arxiv.org/pdf/1804.02767.pdf
링크 1 (참고 블로그) : https://taeu.github.io/paper/deeplearning-paper-yolov3/
[논문] YOLOv3: An Incremental Improvement 분석
YOLOv3: An Incremental Improvement
taeu.github.io
0. 요약 (Abstract)
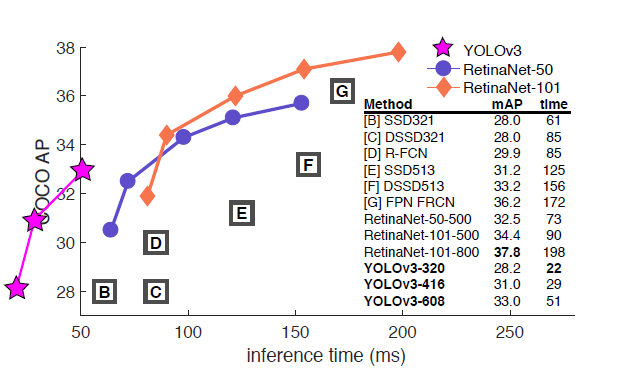
- 예전 버전(욜로 v1, v2)에서 업데이트 되서, YOLO v3는 예전보다 더 좋은 성능을 발휘함
- 정확도가 올라감과 동시에 여전히 빠른 속도(FPS)도 유지
- 320*320 input을 가지는 YOLOv3는 28.2mAP의 성능을 내며, 판단 속도는 22ms로 매우 빠름
* mAP란? (https://bskyvision.com/465)
물체 검출 알고리즘 성능 평가방법 AP(Average Precision)의 이해
물체 검출(object detection) 알고리즘의 성능은 precision-recall 곡선과 average precision(AP)로 평가하는 것이 대세다. 이에 대해서 이해하려고 한참을 구글링했지만 초보자가 이해하기에 적당한 문서는 찾�
bskyvision.com
- YOLOv3와 비교할만한 Object Detection으로 SSD(Single Shot multibox Detector)가 있는데, SSD와 mAP가 비슷하지만 속도는 3배 더 빠름
- 소스 코드는 아래에서 확인할 수 있음 : https://pjreddie.com/darknet/yolo/
YOLO: Real-Time Object Detection
YOLO: Real-Time Object Detection You only look once (YOLO) is a state-of-the-art, real-time object detection system. On a Pascal Titan X it processes images at 30 FPS and has a mAP of 57.9% on COCO test-dev. Comparison to Other Detectors YOLOv3 is extremel
pjreddie.com
1. 소개 (Introduction)
- 별 말은 없고, 기존 YOLO에서 몇 가지 개선을 진행했다고 적힘
2.1. Bounding Box Prediction
- YOLO는 클러스터링을 통해 앵커 박스(anchor box, 미리 정의된 형태를 가진 bounding box)를 생성하여, bounding box(학습 모델이 예측한 물체의 위치(YOLO의 경우 : x_center, y_center, box_width, box_height))를 예측함
- 기존의 YOLO는 grid의 중심점을 예측했다면, YOLOv2 이후부터는 좌상단 offset으로부터 얼만큼 이동하고(b_x, b_y), 앵커박스의 너비와 높이를 얼만큼 비율로 조절할지를 지수승을 통해 예측(b_w, b_h)

[Bounding Box Prediction과 관련된 파라미터]
1) c_x, c_y : grid 셀의 좌상단의 좌표(offset)
- 위와 같이 YOLO는 이미지를 S*S grid 셀로 나눔
- 예를 들어 7*7 grid 셀로 설정하면, 한 이미지에 7*7 = 49개의 셀이 생성
2) p_w, p_h : 앵커박스의 너비 및 높이
3) t_x, t_y, t_w, t_h : YOLO가 예측해야하는 물체의 좌표 값 (bounding box)
4) b_x, b_y, b_w, b_h : 위에서 언급한 값들을 조정하여 실제 GT(Ground Truth, 라벨 값)와 IOU를 계산할 최종 bounding box의 offsets 값들
- b_x, b_y : 시그모이드 함수(sigmoid function)를 통해 t_x, t_y를 0~1 사이의 값으로 초기화
* 시그모이드 함수란? (https://icim.nims.re.kr/post/easyMath/64)
활성함수(Activation) 시그모이드(Sigmoid)함수 정의 | 알기 쉬운 산업수학 | 산
icim.nims.re.kr
- b_w, b_h : 이해 중...
[Bounding Box Prediction의 Loss Function]
- YOLO를 학습하는 동안, squared error loss(제곱 오차)의 합을 사용
* 오차 함수 관련 내용 (https://m.blog.naver.com/wideeyed/221025759001)
딥러닝 손실함수 MSE(Mean Squared Error), CEE(Cross Entropy Error)
손실함수는 정답에 대한 오류를 숫자로 나타내는 것으로오답에 가까울수록 큰 값이 나온다. 반대로 정답에 ...
blog.naver.com
- YOLO의 gradient 값 : ^t* - t*
-> ^t* : 일부 좌표 예측에 대한 GT
-> t* : YOLO의 예측 값
- ^t*=YOLO의 gradient 값 + t*
-> GT 값 ^t*은 방정식^t* - t* 을 뒤집어서 쉽게 계산할 수 있음
- YOLOv3는 로지스틱 회귀(Logistic Regression)을 이용하여 각 바운딩 박스에 대한 objectness 점수를 예측함
-> 바운딩 박스 안에 물체의 유무 판단
* (Logistic Regression이란? : https://nittaku.tistory.com/478)
5-6. 로지스틱 회귀분석(Logistic Regression)
로지스틱 회귀분석 지금까지 학습한 선형 회귀분석 단순/다중은 모두 종속변수Y가 연속형 이었다. 로지스틱회귀분석 은 종속변수가 범주형이면서 0 or 1 인 경우 사용하는 회귀분석이다. 로지스�
nittaku.tistory.com
- 여러 개의 앵커 박스(bounding box prior) 중에서 GT 박스(정답 박스)의 IOU(Intersection Over Union)가 가장 높은 박스를 1로 두어 매칭
* (IOU란? : https://inspace4u.github.io/dllab/lecture/2017/09/28/IoU.html)
Intersection over Union
이 포스트에서는 두 사각형의 IOU를 구하는 방법을 설명하겠습니다. 개요 IOU(Intersection over union)이란 두 영역의 교차영역의 넓이를 합영역의 값으로 나눈 값을 뜻합니다. 객체 검출에서 예측된 경
inspace4u.github.io
- 그 외의 박스는 무시함 (IOU가 가장 높은 박스에 대해서만 계산한다는 의미)
- IOU의 threshold 값으로 0.5를 사용
2.2. Class Prediction
- 각 Box는 mulit-label classification을 사용하여 바운딩 박스가 포함할 수 있는 Class를 예측함
- class predicition : softmax 대신 logistic classifiers를 사용함 (더 좋은 성능을 내기 위해, Darknet-53과는 무관한 부분!)
-> logistic classifiers : Sigmod, ReLU, tanh 등등
- 따라서 loss function도 categorical cross entropy loss(mulit-class classification에서 사용되는 loss 함수)가 아니라, binary cross entropy loss를 사용함
* (cross entropy loss : https://wordbe.tistory.com/entry/ML-Cross-entropyCategorical-Binary%EC%9D%98-%EC%9D%B4%ED%95%B4)
[Classification] Cross entropy의 이해, 사용 방법(Categorical, Binary, Focal loss)
이 글에서는 여러 가지 클래스를 분류하는 Classification 문제에서, Cross entropy를 사용하는 방법와 원리를 알아봅니다. 1. Tasks 우선, 두가지 문제를 봅시다. 1-1) Multi-Class Classfication 각 샘플(이미..
wordbe.tistory.com
- 이러한 과정들은 좀 더 복잡한 데이터셋(Open Images Dataset)으로 YOLO를 학습하는 것에 도움을 줌
2.3. Predictions Across Scales
- YOLOv3는 세 가지의 다른 scale에서 box를 예측
- YOLOv3는 이 scale에서 features를 추출
- 본문에서는 각 scale에 대해 3개의 박스를 생성함
-> 텐서 형태 : N * N * [3 * (4 + 1 + 80)
* N : Gird
* 3 : 바운딩 박스의 갯수 (#bb)
* 4 : 4개의 바운딩 박스 좌표 (offset : x, y, w, h)
* 1 : objectiveness
* 80 : COCO 데이터셋의 class 갯수 (class)
[앵커박스 생성]
- 앵커박스를 결정하기 위해 k-means 클러스터링(비지도 학습 알고리즘의 일종)을 사용
- 3개의 스케일을 사용하고, 각 스케일 마다 박스를 3개를 생성하기 때문에 총 9개의 클러스터(앵커박스)를 선택
- COCO 데이터셋에서의 앵커박스 형태 : 10*13, 16*30, 33*23, 30*61, 62*45, 59*119, 116*90, 156*198, 373*326
2.4. Feature Extractor
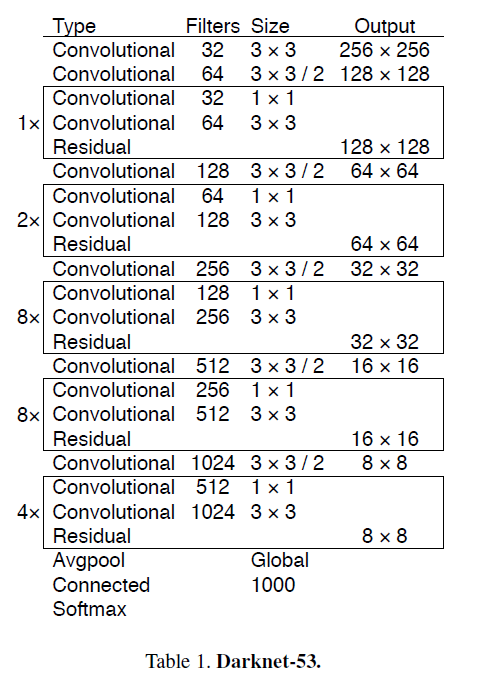
- 백본(Backbone)으로 Darknet-53을 사용함
- ResNet에서 적용됐던 Shortcut Connections을 사용 (아래의 표에서 Residual라고 적혀있는 부분)
(Short Connections이란? : https://ropiens.tistory.com/32)
ResNet : Deep Residual Learning for Image Recognition
작성자 : 한양대학원 융합로봇시스템학과 석사과정 유승환 2016년도에 나온 CNN 아키텍쳐인 ResNet에 대해 리뷰하겠다. AlexNet, VGG, GoogLeNet, ResNet은 과거에 유명했던 CNN 아키텍쳐이고, 지금도 백본으�
ropiens.tistory.com
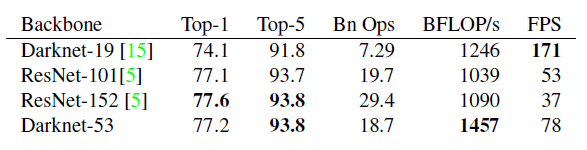
- YOLOv2에서 사용했던 Darknet19, 그리고 ResNet-101과 ResNet-152보다 정확도가 높고, FPS도 합리적임 (아래에 ImageNet에 대한 결과표 첨부)
- 각 네트워크의 학습에 사용했던 이미지 크기 : 256*256 (single crop)
'sinanju06 > 딥러닝 논문 리뷰 (computer vision)' 카테고리의 다른 글
| Mask R-CNN 리뷰 (4) | 2021.01.27 |
|---|---|
| R-CNN : Region-based Convolutional Networks forAccurate Object Detection and Segmentation 리뷰 (3) | 2021.01.19 |
| YOLO v4 리뷰 : Optimal Speed and Accuracy of Object Detection (10) | 2020.05.11 |
| ResNet : Deep Residual Learning for Image Recognition 논문 리뷰 (2) | 2020.05.06 |
| What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis (6) | 2020.04.10 |