
티스토리 뷰
YOLO v4 리뷰 : Optimal Speed and Accuracy of Object Detection
hanyangrobot 2020. 5. 11. 17:29작성자 : 한양대학원 융합로봇시스템학과 유승환 석사과정 (CAI LAB)
오늘은 저번달에 나온 따끈 따끈한 YOLO의 새로운 버전, YOLO v4에 대해 공부해보겠다! 아카이브 기준으로 2020년 4월 23일에 YOLO v4 논문이 나왔으며, 최신 논문 답게 CSP 같은 최신 딥러닝 기법들이 많이 소개되어 있다. YOLO v4의 아키텍쳐와 함께 최신 딥러닝 기법들도 간단하게 정리해보겠다.
링크 0 (원문 링크 ) : https://arxiv.org/pdf/2004.10934.pdf
링크 1 (참고 영문 블로그 링크) : https://medium.com/@jonathan_hui/yolov4-c9901eaa8e61
YOLOv4
While object detection matures in the last few years, the competition remains fierce. As shown below, YOLOv4 claims to have…
medium.com
0. Abstract
기존의 CNN들은 batch-normalization, residual-connections과 같은 새로운 기법을 활용하여 성능을 향상시켰다.
* batch normalization 이란? : https://m.blog.naver.com/laonple/220808903260
[Part Ⅵ. CNN 핵심 요소 기술] 1. Batch Normalization [1] - 라온피플 머신러닝 아카데미 -
Part I. Machine Learning Part V. Best CNN Architecture Part VII. Semantic ...
blog.naver.com
* residual-connections 이란? : https://m.blog.naver.com/laonple/220793640991
[Part Ⅴ. Best CNN Architecture] 8. ResNet [7] - 라온피플 머신러닝 아카데미 -
Part I. Machine Learning Part V. Best CNN Architecture Part VII. Semantic ...
blog.naver.com
YOLO v4에서는 최신의 딥러닝 기법을 적용하여 성능 향상을 했다. 사용한 기법들은 아래와 같다.
1) WRC (Weighted-Residual-Connections)
2) CSP (Cross-Stage-Partial-Connections)
3) CmBN (Cross mini-Batch Normalizations)
4) SAT (Self-Adversarial-Training)
5) Mish Activation
6) Mosaic Data Agumentation
7) Drop Block Regularization
8) CIOU Loss
이러한 기법들을 적용하고나서, MS COCO 데이터셋에서 AP : 43.5% (AP50 : 65.7%), 65 FPS(Tesla V100 그래픽카드 , 거의 실시간에 가까운 높은 FPS)를 달성했다. 소스 코드는 아래에 있다.
* YOLO v4 깃헙 링크 : https://github.com/AlexeyAB/darknet
AlexeyAB/darknet
YOLOv4 - Neural Networks for Object Detection (Windows and Linux version of Darknet ) - AlexeyAB/darknet
github.com
1. Introduction
최신 Neural Networks들은 높은 정확도를 가지지만, 낮은 FPS(실시간 X)와 너무나 큰 mini-batch-size로 인해 학습하는데 많은 수의 GPU들이 필요하다는 단점이 있다. 이러한 문제를 해결하기 위해, YOLO v4는 다음과 같은 기여를 제공한다.
1) 일반적인 학습 환경에서도 높은 정확도와 빠른 object detector를 학습시킬 수 있다. 1개의 GPU(ex : GTX 1080 Ti, 2080 Ti)만 있으면 충분하다.
2) detector를 학습하는 동안, 최신 BOF, BOS 기법이 성능에 미치는 영향을 증명한다. (BOF와 BOS가 무엇인지는 2장에서 설명)
3) CBN, PAN, SAM을 포함한 기법을 활용하여 single GPU training에 효과적이다.
요약하자면 1개의 GPU를 사용하는 일반적인 학습환경에서 BOF, BOS 기법을 적용하여 효율적이고 강력한 Object Detection을 제작했다는 이야기다.
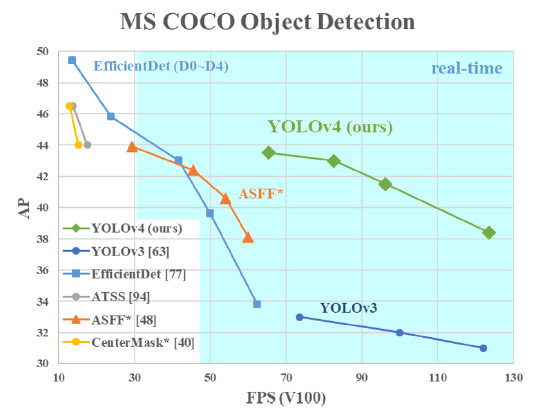
2. Related Work
2.1. Object Detection Models
이 절에서는 Object Detection의 일반적인 구조(백본, Neck, Head)와 종류(1-stage, 2-stage)에 대해 소개한다.
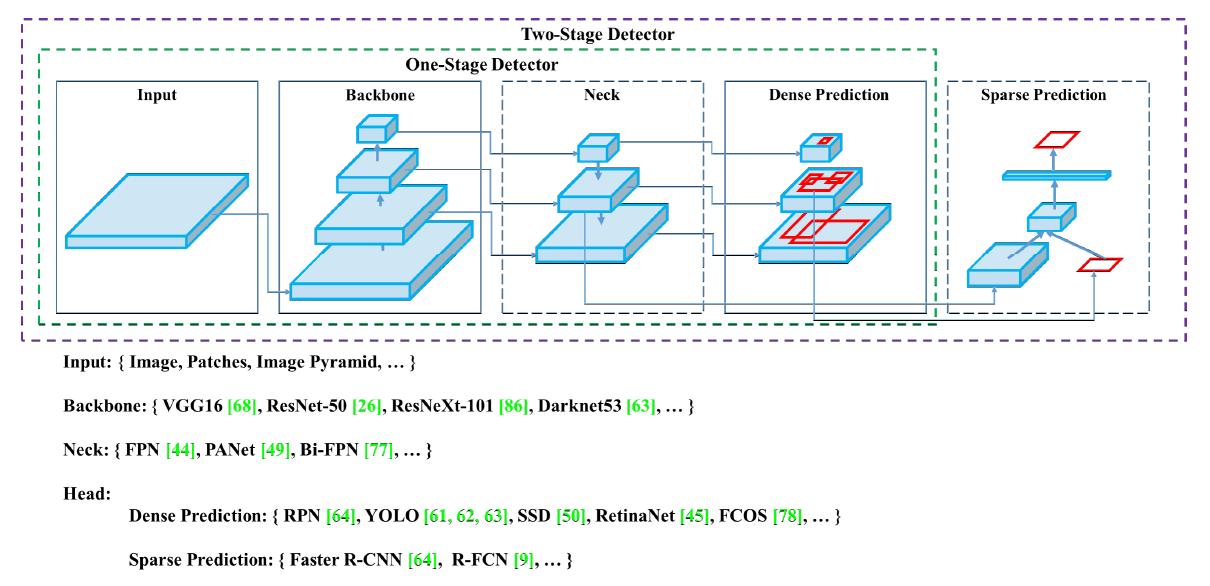
최신 detector는 주로 백본(Backbone)과 헤드(Head)라는 두 부분으로 구성된다. 백본은 입력 이미지를 feature map으로 변형시켜주는 부분이다. ImageNet 데이터셋으로 pre-trained 시킨 VGG16, ResNet-50 등이 대표적인 Backbone이다. 헤드는 Backbone에서 추출한 feature map의 location 작업을 수행하는 부분이다. 헤드에서 predict classes와 bounding boxes 작업이 수행된다.
헤드는 크게 Dense Prediction, Sparse Prediction으로 나뉘는데, 이는 Object Detection의 종류인 1-stage인지 2-stage인지와 직결된다. Sparse Prediction 헤드를 사용하는 Two-Stage Detector는 대표적으로 Faster R-CNN, R-FCN 등이 있다. Predict Classes와 Bounding Box Regression 부분이 분리되어 있는 것이 특징이다. Dense Prediction 헤드를 사용하는 One-Stage Detector는 대표적으로 YOLO, SSD 등이 있다. Two-Stage Detector과 다르게, One-Stage Detector는 Predict Classes와 Bounding Box Regression이 통합되어 있는 것이 특징이다. 자세한 설명은 아래 블로그에서 친절히 설명되어 있다.
* 참고 링크 (One Vs Two-Stage Detector) : https://nuggy875.tistory.com/20
[Object Detection] 1. Object Detection 논문 흐름 및 리뷰
Deep Learning 을 이용한 Object Detection의 최신 논문 동향의 흐름을 살펴보면서 Object Detection 분야에 대해서 살펴보고, 구조가 어떤 방식으로 되어있으며 어떤 방식으로 발전되어 왔는지 살펴보고자 ��
nuggy875.tistory.com
넥(Neck)은 Backbone과 Head를 연결하는 부분으로, feature map을 refinement(정제), reconfiguration(재구성)한다. 대표적으로 FPN(Feature Pyramid Network), PAN(Path Aggregation Network), BiFPN, NAS-FPN 등이 있다. FPN과 PAN도 추후 기회가 되면 블로그에 정리를 해보겠다.
2.2. Bag of Freebies (BOF)
BOF는 inference cost의 변화 없이 (공짜로) 성능 향상(better accuracy)을 꾀할 수 있는 딥러닝 기법들이다. 대표적으로 데이터 증강(CutMix, Mosaic 등)과 BBox(Bounding Box) Regression의 loss 함수(IOU loss, CIOU loss 등)이 있다. 이 기법들의 상세한 내용은 3.4 YOLO v4에서 소개하겠다.
2.3. Bag of Specials (BOS)
BOS는 BOF의 반대로, inference cost가 조금 상승하지만, 성능 향상이 되는 딥러닝 기법들이다. 대표적으로 enhance receptive filed(SPP, ASPP, RFB), feature integration(skip-connection, hyper-column, Bi-FPN) 그리고 최적의 activation function(P-ReLU, ReLU6, Mish)이 있다. 이 기법들의 상세한 내용도 3.4절에서 소개하겠다.
3. Methodology
(3.1. Selection of Architecture, 3.2. Selection of BOF and BOS, 3.3. Addition Improvements의 내용은 3.4절에서 통합해서 설명하겠다.)
3.4. YOLO v4
YOLO v4의 아키텍쳐는 다음과 같다.
1) Backbone : CSP-Darkent53
2) Neck : SPP(Spatial Pyramid Pooling), PAN(Path Aggregation Network)
3) Head : YOLO-v3
YOLO v4에서는 다음과 같은 최신 딥러닝 기법들을 사용했다.
[Bag of Freebies (BoF) for backbone]
4-1) CutMix : 데이터 증강법의 일종. 한 이미지에 2개의 class를 넣은 것이 특징.
* 참고 링크 : https://hoya012.github.io/blog/ICCV-2019-paper-preview/
ICCV 2019 paper preview
ICCV 2019 학회에 논문들에 대한 간단한 분석 및 주요 논문 22편에 대한 리뷰를 작성하였습니다.
hoya012.github.io
4-2) Mosaic Data Augmentation : CutMix와 마찬가지로 데이터 증강법의 일종. 한 이미지에 4개의 class를 넣은 것이 특징.
* 3.3절의 Figure 3 참고
4-3) DropBlock Regularization : 드롭아웃(DropOut)과 같은 Regularization 기법의 일종. 랜덤하게 out시키는 DropOut과는 달리, 일정한 범위를 out 시킴.
* 참고 링크 : www.norman3.github.io/papers/docs/dropblock.html
4-4) Class label Smoothing : 라벨 방법에 관한 새로운 기법. 기존의 라벨법은 0과 1과 같은 정수로 표시했지만, label smoothing 기법을 적용하면 label을 0.1, 0.9와 같은 확률로 표시하게 됨. 이러한 기법을 사용하는 이유는 misslabeling 때문. 이미지 라벨링을 사람이 하기 때문에 misslabeling 문제가 발생하는데(ex : 고양이 사진을 dog라고 라벨링하는 경우), 데이터 수가 많다면 라벨 수정에 어려움을 겪게 됨. 이 문제를 해결하기 위해 label을 0 또는 1이 아니라 smooth하게 부여함으로써, calibration 및 regularization 효과를 얻게 되어 overfitting 문제를 방지.
* 참고 링크 : https://3months.tistory.com/465
Label smoothing: 딥러닝 모델의 일반화와 Calibration 향상을 위한 테크닉
Label smoothing 본 포스팅에서는 최근 딥러닝 모델의 정확도와 Calibration 향상 최종적으로는 model generalization 에 도움이 된다고 알려진 Label smoothing 에 대해서 살펴보도록 하겠습니다. Introduction..
3months.tistory.com
[Bag of Specials (BoS) for backbone]
5-1) Mish Activation : 활성화 함수에 관한 최신 기법. 수식은 다음과 같이 정의되고, 그래프는 아래에 첨부한다.
f(x) = x * tanh(softpuls(x))
// softplus(x) = ln(1 + e^x)
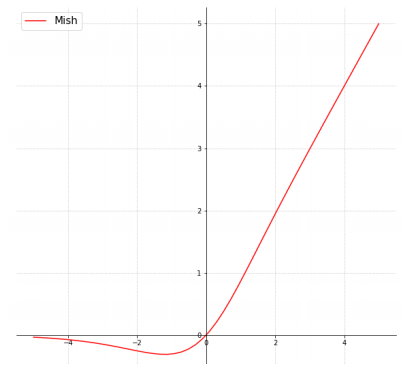
Mish를 사용하면 다음과 같은 이점을 얻게 된다.
5-1-1) 일반적으로 0에 가까운 기울기로 인해, 훈련 속도가 급격히 느려지는 포화(Saturation) 문제 방지
-> ReLu보다 Mish의 gradient가 좀 더 smooth함
5-1-2) 강한 규제(Regularation) 효과로 overfitting 문제 방지
* 참고 링크 : https://krutikabapat.github.io/Swish-Vs-Mish-Latest-Activation-Functions/
Swish Vs Mish: Latest Activation Functions
In this blog post we will be learning about two of the very recent activation functions Mish and Swift. Some of the activation functions which are already in the buzz. Relu, Leaky-relu, sigmoid, tanh are common among them. These days two of the activation
krutikabapat.github.io
5-2) CSP(Cross-Stage Partial connections) : 기존의 CNN 네트워크의 연산량을 줄이는 기법. 원문에서 제안하는 CSP Net은 연산량을 20% 줄이면서도 MS COCO에서 높은 AP를 가진다고 한다. 요약하자면 학습할 때 중복으로 사용되는 기울기 정보를 없앰으로써 연산량을 줄이면서도 성능을 높인다. CPS를 소개하기 위해서, 원문 3장에서와 같이 DenseNet과 CSP-DenseNet을 비교하면서 설명하겠다.
* 원문 링크 : https://arxiv.org/pdf/1911.11929.pdf
[DenseNet (일반적인 아키텍쳐)]
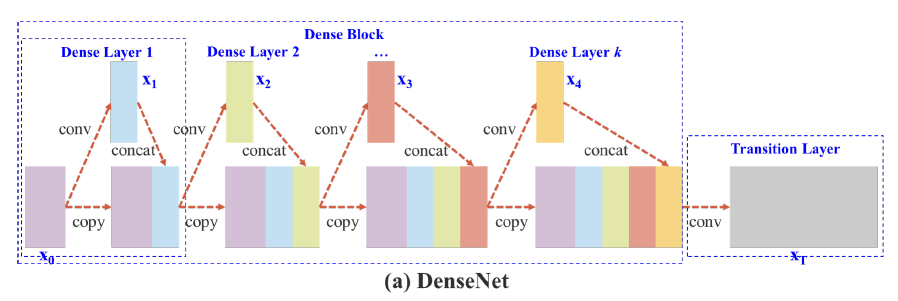
추가 Figure 2-(a)는 DenseNet의 네트워크 구조이다. DenseNet은 크게 dense block과 tranistion layer이 포함된다. 그리고 각 dense block은 k개의 dense layers을 포함하고 있다. i번째의 dense layer에서 x_0(연보라색 블록)과 x_1(연하늘색 블록)이 결합되고(concatenated), 이 결합된 output은 (i + 1)번 째의 dense layer의 input이 된다. 이에 관한 메커니즘 방정식은 다음과 같이 식 1로 표현될 수 있다.
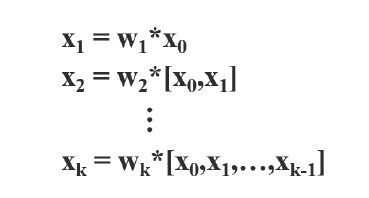
식 1에서 *는 convolution 연산자를 나타낸다. [x_0, x_1, ,,, x_k]는 x0, x1, ,,, x_k를 결합했다는 의미이다. (ex : Dense Layer 1에서 연보라와 연하늘 블록이 결합) w_i, x_i는 i번째 dense layer의 가중치(weight)와 output이다. 이 식을 보면 이전 레이어에서 계산했던 x_0, x_1 등의 결합 연산을 다음 레이어에서 한번 더 반복한다. (쓸데 없는 연산 낭비)
가중치를 업데이트 하기 위해서 오차 역전파(back propagation) 알고리즘을 사용할 때, 가중치 업데이트 방정식은 다음과 같이 작성할 수 있다.
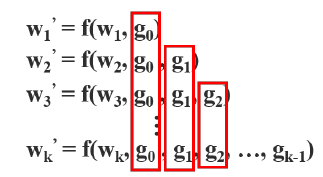
여기서 함수 f는 가중치 업데이트에 관한 함수이며 g_i는 i번째 dense layer로 전파되는 기울기(gradient)를 나타낸다. 우리는 많은 양의 기울기 정보가 서로 다른 dense layers의 가중치를 업데이트하기 위해 재사용된다는 것을 발견할 수 있다. 이렇게 되면 서로 다른 dense layers가 복사된 gradient 정보를 반복적으로 학습하게 된다.
[CSP(Cross-Stage-Partial) DenseNet]
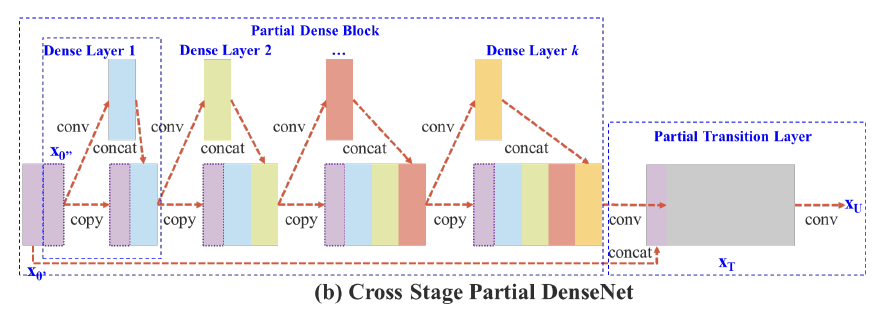
본문에서 제안하는 CSP DenseNet의 아키텍쳐는 위의 추가 Figure 2-(b)에서 볼 수 있다. CSP DenseNet은 partial dense block과 partial transition layer로 구성된다. (DenseNet의 구성품 앞에 수식어 'partial'를 붙임)
partial dense block에서는 dense layer 1의 피쳐맵(연보라색 블록을 의미, 원문에서는 base layer라고 표기됨)은 채널을 통해 다음과 같이 두 부분으로 분리된다.
x_0 = [x_0', x_0'']
former(x_0')는 stage의 끝인 partial transition layer과 직접 연결되어 있고, latter(x_0'')는 다음 dense block들을 거치게 된다. partial transition layer와 관련된 모든 step은 다음과 같다.
첫째, dense layer의 output인 [x_0'', x_1, ,,, , x_k]은 transition layer(회색 블록)를 겪게(undergo) 될 것이다.
둘째, 이 transition layer의 output인 x_T는 x_0'과 결합되어 x_U를 생성한다. CSP-DenseNet의 feed-forward pass와 가중치 업데이트 방정식은 각각 식3, 4에 나타나 있다.
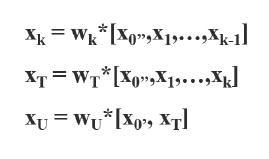
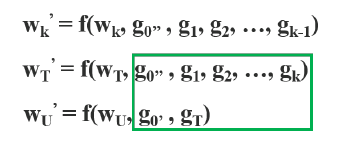
식 4의 초록색 상자를 보면, dense layer에서 오는 기울기 g들이 분리되어 각각 w_T와 w_U에 통합되어 있음을 알 수 있다. (w_T에는 g_0'', g_1, ,,, g_k 값을 가지지만, w_U에는 g_0', g_T 값을 가진다.) 가중치를 업데이트하기 위한 기울기 값에 대해서, w_T와 W_U는 모두 다른 면에 속하는 중복 기울기 정보를 포함하지 않는다.
요약하자면, 제안된 CSP-DenseNet은 DenseNet의 장점인 'feature 값 재사용'을 보존하면서도, 동시에 기울기 정보가 중복으로 사용되는 것을 방지한다. 이 아이디어는 hierarchial feature fusion 전략을 설계함으로써 실현되고, partial transition layer에서 사용된다.
[Partial Dense Block]
Partial Dense Block의 설계 목적은 총 3가지이다. 1) 기울기 path 증가, 2) 각 레이어의 밸런스 맞춘 계산량, 3) 메모리 traffic 감소
1) 기울기 path 증가 : split(base layer의 분리)과 merge(transition block에서 통합) 전략을 통해, gradient paths의 수는 두배가 된다. Cross-Stage 전략 때문에, 결합을 위해 복사한 피쳐맵(연보라색 블록)을 사용함으로써 생기는 단점을 완화할 수 있다. (왜 path 수가 두배가 되고, 이것이 어떻게 단점을 완화하는지 잘 안와닿네...)
2) 각 레이어의 밸런스 계산량 : DenseNet의 base layer(연보라색 블록)의 채널 수는 growth rate(growth rate는 무엇일까?)보다 훨씬 크다. partial dense block에서 dense layer 연산에 관여하는 base layer의 채널들이 원래 값의 절반 밖에 차지하지 않기 때문에, DenseNet 보다 계산량의 두 배를 효율적으로 감소할 수 있다.
3) 메모리 traffic 감소 : DenseNet의 dense block의 base 피쳐맵 사이즈가 w(너비) * h(높이) * c(채널)이고, growth rate는 d, 그리고 총 m개의 dense layer가 있다고 하자. 이때 Dense Block의 CIO(CIO가 뭐지...)는 (c * m) + ((m^2 + m) * d)/2이고, Partial Dense Block의 CIO는 ((c * m) + (m^2 + m) * d)/2 이다. m과 d는 보통 c보다 훨씬 작지만, partial dense block은 네트워크의 메모리 traffic의 절반을 저장할 수 있다.
[Partial Transition Layer]
Partial Transition Layer의 설계 목적은 기울기 조합의 차이를 최대화하는 것이다. 우리는 gradient flow의 줄임(truncating)이 네트워크의 학습 능력에 어떻게 영향을 미치는지 보여주기 위해 CSP-DenseNet의 두 가지 변형을 설계한다.
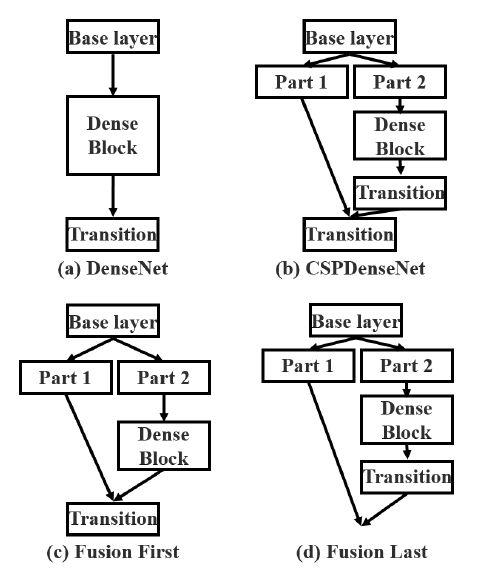
Figure 3-(c)에서 fusion first에서의 CSP는 다음을 의미한다 : 두 부분으로 생성된 피쳐맵(part 1, part 2)을 연결한 다음, transition 연산을 수행. 이 전략이 채택되면 대량의 기울기 정보가 재사용된다.
Figure 3-(d)에서 fusion last에서의 CSP는 다음을 의미한다 : dense block의 결과물은 transition layer를 거치고나서, 두 부분의 피쳐맵이 결합된다. 이 경우, 기울기 흐름이 잘리기 때문에, 기울기 정보가 재사용되지 않는다.
Figure 3-(a) ~ (d)의 결과는 아래의 Figure 4에서 볼 수 있다.
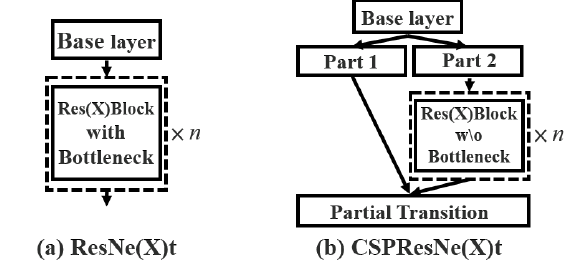
번외로 CSP를 ResNe(X)t에 적용하면 다음과 같이 구성할 수 있다.
5-3) MiWRC(Multi-input weighted residual connections) : 추후 공부 예정
[Bag of Freebies (BoF) for detector]
6-1) CIoU-Loss : 추후 공부 예정
* 원문 링크 : https://arxiv.org/pdf/1911.08287.pdf
6-2) CmBN(Cross-mini Batch Normalization) : 추후 공부 예정
[Bag of Specials (BoS) for detector]
7-1) SPP-block : 새로운 Pooling 방법인 Spatial Pyramid Pooling에 대한 내용이다. SPP를 적용한 Neural Network를 SPP-Net이라고 한다. SPP Net의 특징은 input image에 fixed-size(예시 : 224*224)가 필요 없다는 것이다. 이러한 이점을 활용하여 정확도를 향상시키고, object detctor 기법인 R-CNN보다 속도가 향상되었다.
* 원문 링크 : https://arxiv.org/pdf/1406.4729.pdf
* 참고 블로그 : https://yeomko.tistory.com/14
갈아먹는 Object Detection [2] Spatial Pyramid Pooling Network
지난 글 갈아먹는 Object Detection [1] R-CNN 들어가며 지난 시간 R-CNN에 이어서 오늘은 SPP-Net[1]을 리뷰해보도록 하겠습니다. 저 역시 그랬고, 많은 분들이 R-CNN 다음으로 Fast R-CNN 논문을 보시는데요, 해
yeomko.tistory.com
기존의 CNN은 input으로 fixed-size image가 필요했다. 그런데 과연 image가 꼭 fixed일 필요가 있을까? 현재 CNN 아키텍쳐들은 image를 fixed-size로 맞추기 위하여 crop, wrap과 같은 방법을 사용한다. 아래의 그림은 crop과 wrap의 예시이다.

image를 crop하거나 wrap하면 문제점이 발생한다. crop를 하면 region은 해당 오브젝트의 전체를 포함하지 않는다. 위의 자동차 사진을 crop한 예시도 자동차의 앞, 뒷부분이 잘리는 문제점이 발생한다. 반면에 wrap은 기하학적 왜곡이 발생한다. 위의 등대 사진을 wrap한 예시도 등대의 너비가 길어짐으로써 왜곡되는 현상을 볼 수 있다. 즉 crop과 wrap과 같이 인의적으로 이미지를 fixed-size로 변형하면 원본 데이터가 손상되는 문제점이 발생한다.
이제 CNN에서 fixed input size가 왜 필요한가에 대해 생각해볼 필요가 있다. CNN은 convolution layer와 fully-connected layer 라는 두 가지 파트로 구성되어 있다. convolution layer에서는 fixed image size가 필요 없고, 원하는 size의 feature map을 생성할 수 있다. 반면에 fully-connected layer는 fixed-size/length를 지닌 input이 필요하다. CNN에서 fixed-size image가 필요한 이유는 fully-connected layer 때문이다.
이 논문에서, 우리는 SPP(Spatial Pyramid Pooling) layer를 소개한다. SPP는 CNN에서 fixed-size image를 요구하는 것을 제거할 수 있다. 즉 image size로부터 자유로워진다. SPP는 input size에 상관 없이, fixed-length를 지닌 output을 생성할 수 있다. 그리고 SPP는 multi-level spatial bins을 사용한다. (이 bins이 뭔지에 대해서는 아래에서 설명한다.) 마지막으로 SPP는 다양한 scale로 feature를 pooling 할 수 있다. 아래의 사진은 일반적인 CNN과 SPP-Net의 구조 차이를 보여준다.

[Spatial Pyramid Pooling Layer]
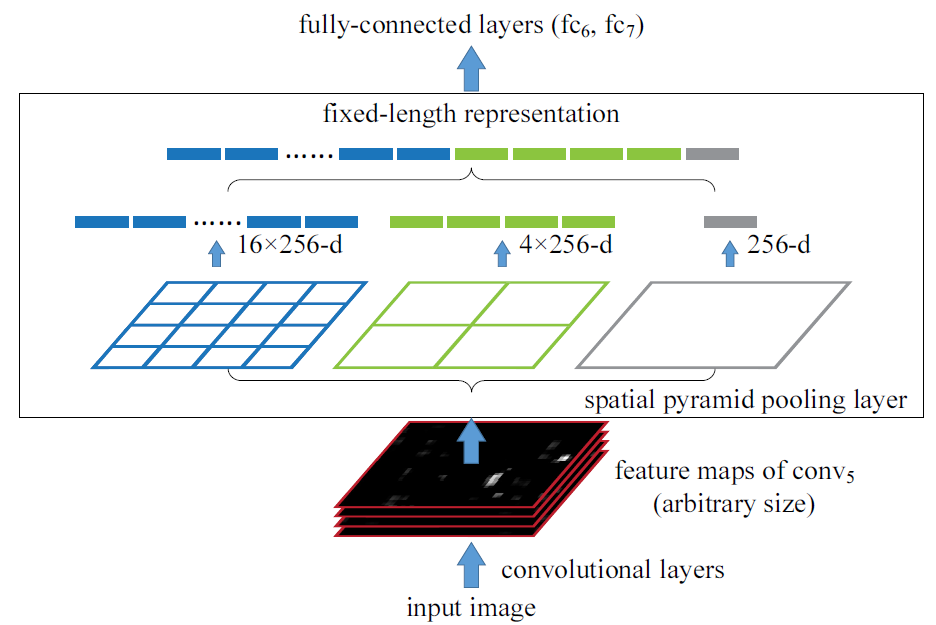
SPP는 local spatial bins를 pooling함으로써 spatial 정보를 유지할 수 있다. 여기에서 spatial bins란, spatial pyramid(1*1 회색, 4*4 녹색, 16*16 파란색)에서 1칸짜리 공간을 의미한다.
이러한 spatial bins들은 image size에 비례하여 sizes를 가진다. 따라서 bins의 수는 고정되어 있다. (이미지의 크기에 상관없이!) 이것은 이전 deep networks의 sliding window pooling과 대조된다. sliding window의 수는 input size에 비례한다.
각각의 spatial bins에서, 우리는 각 필터의 resopnses를 풀링한다. (논문에서는 max-pooling을 사용) SPP의 output은 kM 차원을 가진다. (k : 마지막 conv layer의 필터 수, M : bins의 수) 이렇게 kM 값을 갖는 fixed-dimensional vectors은 Fully connected layer의 input으로 사용된다.
SPP를 이용함으로써, image size는 어떤 크기든 사용할 수 있다. 이것은 임의의 aspect ratiois와 scales을 사용할 수 있게 한다. 따라서 우리는 어떤 scale로든 input image를 resize할 수 있다.
7-2) SAM-block : 추후 공부 예정
7-3) PAN(Path-Aggregation) block : 원문에서는 PAN block을 적용한 PANet(Path Aggregation Network)을 소개한다. PANet는 COCO 2017 Challenge Instance Segmentation과 Object Detection 분야에서 각각 1, 2등을 했다. (Instance segmentation은 1) predict class label과 2) predict pixel-wise insatnce mask to localize varying number of instances 로 구성되어 있다.)
PANet은 instance segmentation 프레임워크에서 information flow를 강화하는 것을 목표로 한다. 구체적으로는 lower layers (앞단의 conv layer)와 topmost feature(뒷단의 conv layer) 사이의 information path를 단축하는 bottom-up path augmentation에 의해 lower layers의 정확한 localization 신호로 전체 feature 계층을 강화한다. 또한 각 feature level에서 유용한 정보가 sub networks로 직접 전파되도록 feature gird와 모든 feature level을 연결하는 adaptive feature pooling을 원문에서 제안한다.
* 원문 링크 : https://arxiv.org/pdf/1803.01534.pdf
PANet
Path Aggregation Network for Instance Segmentation (2018, arXiv) - Paper : https://arxiv.org/...
blog.naver.com
[1. Introduction]
low levels(앞단 conv layer)에 있는 features는 instance identification에 도움을 준다. 그러나 low-level features가 topmost (뒷단 conv layer) features로 가기에는 long path가 존재한다. 이러한 긴 경로는 정확한 localization 정보를 얻는 것에 어려움을 준다. 이러한 문제를 해결하기 위하여 원문에서는 PANet(Path-Aggregation Networks)를 제안하고, 우리의 기여는 다음과 같다.
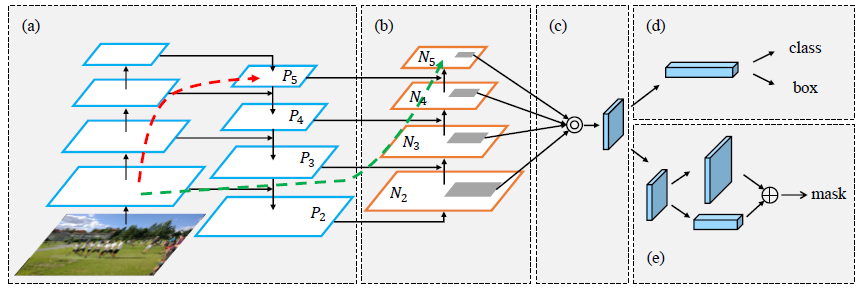
첫째, information path (low levels의 feautre가 topmost로 가는 경로) 를 단축하고, low-levels에 존재하는 정확한 localization 신호로 feature pyramid를 강화하기 위하여, bottom-up path augmentation (Figure-1의 (b) 부분) 을 생성한다.
둘째, each proposal과 모든 feature levels 사이에 있는 손상된 infromation path를 복구하기 위해, adaptive feature pooling (Figure-1의 (c) 부분) 을개발한다. Adaptive feature pooling은 임의로 할당된 결과를 피하면서, 각 proposal에 대한 모든 feature levels에서 나온 feature를 집계하는 간단한 구성요소 이다.
마지막으로, tiny fully-connected layers (Figure-1의 (e) 부분) 로 mask prediction을 증축한다. 이 fc layers는 Mask R-CNN이 원래 사용하던 fully connected network에 대해 보완적 특성을 갖는다.
[3. Framework]
PANet의 구조는 위에 있는 Figure 1에 설명되어 있다. 성능 향상을 위해 path augmentation과 aggregation 연산을 수행한다. low-layer의 정보가 더 쉽게 전파되도록 bottom-up path를 생성한다. 각 proposal이 prediction을 위해 모든 level에서 information에 접근할 수 있도록 adaptive feature pooling을 설계한다. 보완(complementary) 경로가 mask-prediction branch에 추가된다. 이러한 새로운 구조인 PANet은 괜찮은 성과로 이어진다. FPN과 유사하게, 이러한 개선은 CNN 아키텍쳐와는 무관하다.
[3.1. Bottom-up Path Augmentation]
<Motivation>
뒷단의 conv layer(higher layers)는 전체 objects에 강하게 반응하는 반면, 다른 뉴런은 local texture과 patterns에 의해 활성화될 가능성이 높다는 점은 다음과 같은 필요성을 요구한다 : 강한 feature를 전파하고 FPN에서 합리적인 classification 능력으로 모든 feature를 강화하기 위해 top-down path를 증강할 필요성
우리의 프레임워크는 edges나 instance parts에 강한 반응(response)이 정확한 instances의 localize에 대한 강력한 지표라는 사실을 바탕으로, low-level patterns의 강한 response를 전파함으로써 전체 feature 계층의 localization 능력을 더욱 강화한다.
이를 위해 low level에서 top까지 clean lateral connections을 가진 path를 생성한다. 따라서 이러한 level을 통과하여 10개 미만의 layers로 구성된 "short-cut"이 있다. (Figure 1의 초록색 점선) 이에 비해 FPN에 있는 CNN trunk는 low layer에서 topmost까지 100개 이상의 layer를 통과하는 긴 경로를 제공한다. (Figure 1의 붉은 점선)
'sinanju06 > 딥러닝 논문 리뷰 (computer vision)' 카테고리의 다른 글
| Mask R-CNN 리뷰 (4) | 2021.01.27 |
|---|---|
| R-CNN : Region-based Convolutional Networks forAccurate Object Detection and Segmentation 리뷰 (3) | 2021.01.19 |
| YOLOv3 : An Incremental Improvement 리뷰 (2) | 2020.08.05 |
| ResNet : Deep Residual Learning for Image Recognition 논문 리뷰 (2) | 2020.05.06 |
| What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis (6) | 2020.04.10 |